當物流調度遇見PostgreSQL-機器學習
《當物流調度遇見PostgreSQL-機器學習》要點:
本文介紹了當物流調度遇見PostgreSQL-機器學習,希望對您有用。如果有疑問,可以聯系我們。
相關主題:PostgreSQL教程
原題目:當物流調度遇見PostgreSQL - GIS, routing, 機器學習 (獅子,女巫,魔衣櫥)
配景
物流行業是被電子商務催生的財產之一.
快件的配送和攬件的調度算法是物流行業一個非常重要的課題,直接關系到配送或攬件的時效,以及物流公司的運作本錢.
好的算法,可以提高時效,降低本錢,甚至可以更好的調動社會資源,就像滴滴打車一樣,也許能全民參與哦.
以后也許上班路途還能順路提供快遞服務呢.
本文將以物流行業為例,給大家分析一下PostgreSQL與Greenplum在地理位置信息處理,最佳路徑算法,機器學習等方面的物流行業應用辦法.
要素闡發
物流做的事情很簡單,寄件,送件.
物流環節的要素有幾個,都與位置有關
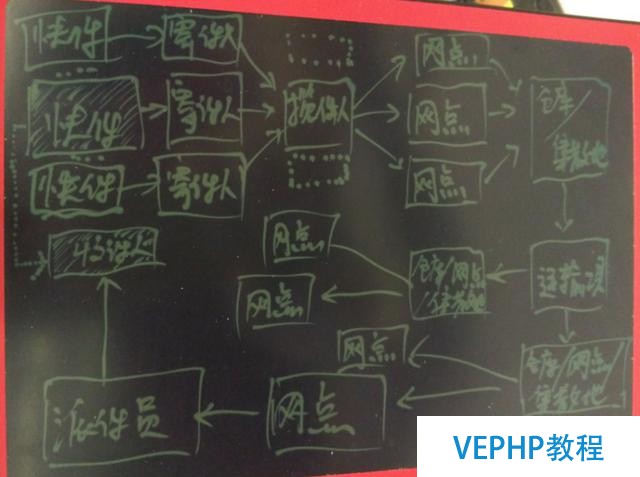
寄件人
攬件員
PS,攬件人通常不是直接將貨收到倉庫,而是網點.所以網點到倉庫也是必要調度的,本文未涉及.
調度辦法與配送差不太多.
貨物
倉庫
運輸工具
派件員
收件人
如果引入時間屬性,則更具有想象空間,例如前面提到的像滴滴打車一樣,也許能全民介入哦.
我們這里先從簡單的入手,假設現在只關心位置信息.
1. 寄件
貨物從寄件人到攬件員,通常是預約的操作,而且寄件人可以直接去網點解決寄件,所以沒有太多的算法在里面.
如果派件和攬件混合在一起的話,可以用KNN算法來辦理,再結合派件點路徑調度,選出最佳的攬件人.
例如,寄件人當前位置,與快遞員調度的下一個位置,進行KNN運算,因此B來攬件是本錢最低的.

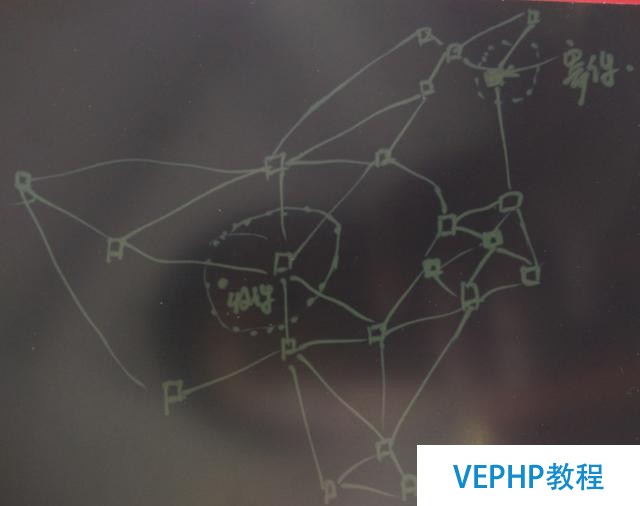
2. 貨物在倉庫之間流轉的物流調度

假設上圖為倉庫的位置,兩個倉庫之間如果開通了線路的話,就以線段連接起來.
每個倉庫負責一個區域,這個區域是一個幾何的圖形.
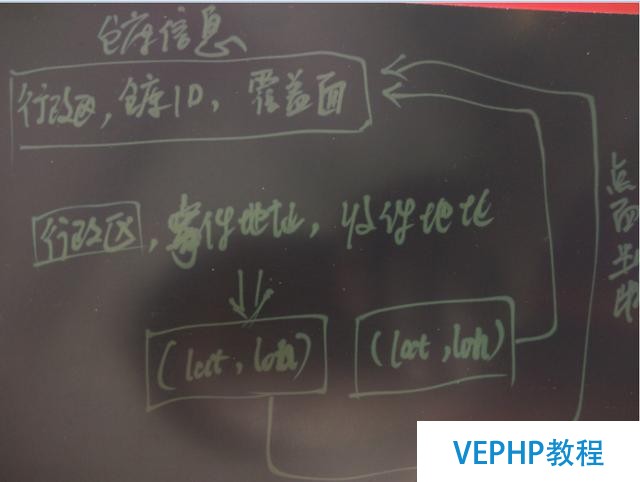
通過寄件人和收件人的位置,與倉庫的區域進行點面判斷,找出寄件人的倉庫與收件人的倉庫.
快件為點,倉庫為面,寄件時根據寄件人填寫的寄件和收件信息轉換為寄件和收件兩個經緯度,通過這兩個經緯度與快遞公司的倉庫表進行點面包括的判斷匹配,就可以找出快件對應的起點和重點的倉庫.
點面判斷
有了源和目標就可以通過pgrouting提供的各種最佳路徑算法算出每件貨物的最佳路徑.
本文后面會有demo來講解如何使用pgrouting計算最佳路徑.

倉庫之間的貨車的工作就簡單了,裝滿就走 或 分波次(考慮到時效) 的原則,負責好兩個直連節點的來回運輸,并不是一輛車完成整個貨物的從出發點到終點的運輸.
例如負責A和B之間線路的貨車,只在AB之間跑運輸.

3. 貨物從終點倉庫到網點的物流調度
貨物在抵達目標倉庫后,首先要將貨物分揀到派件的網點.
其實也是一個點面判斷的過程,網點覆蓋的派件范圍為面,快件則為點,點面判斷找出對應的網點.
從倉庫到網點,也可以使用倉庫建流轉的原理,計算出最佳線路.貨車只負責2個網點之間的貨物流轉即可.
4. 派件
進入派件的流程,也便是貨物在抵達收件人手中的最后一公里要做的事情.
為了更好的實現派件調度,必要對快件進行聚合操作,根據位置進行聚合.
原理和前面類似,還是要做點面判斷,只是目標更加精確,例如精確到小區或者很小的區域.

派件除了要考慮快件的目的地(聚合后的),還必要考慮快件的體積,重量,以及快遞員的運貨能力(體積與重量) .
假設一個網點當前收到的快件覆蓋了以下必要派送的點(聚合后的),同時每個點的貨物體積總和如數字所表示.
路徑規劃與前面紛歧樣的地方,這里規劃的是多個點作為目標.
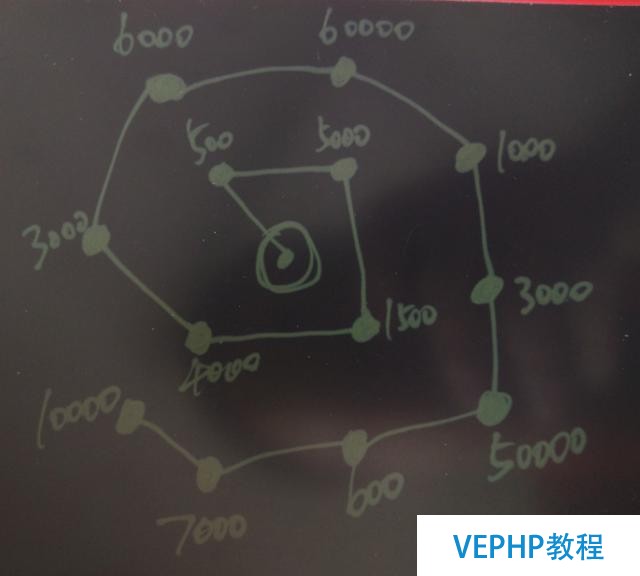
多點目標的最佳路徑,用意是確保相鄰目標的連續性,確保切分分歧網點的快件后,拿到快件的人跑的是還是相鄰的點.
例如中心是網點的位置,其他點是目標位置,目標位置的數字是體積,假設每個快遞員一次運輸的體積是7000,虛線是一個快遞員拿到的一趟的快件.
這種辦法確保了每趟的快件是連續的.
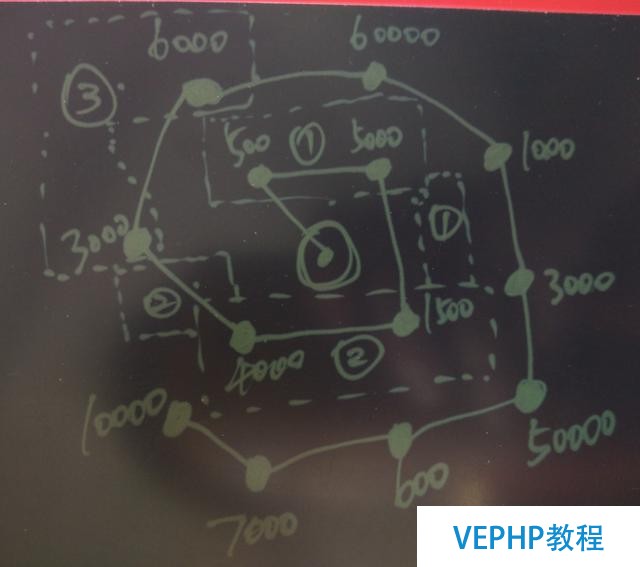
多點目標的最佳路徑規劃,在本文后面的部門也會有DEMO.
地址轉換成坐標
如何將地址轉換成坐標,不在本文的討論范圍,很多做導航的公司都可以輸出這個才能.
但是作為快遞公司,還有一種辦法可以獲得精確的坐標信息,例如快遞員的手持GPS終端,收件時掃個條碼,同時上報位置信息.
有了一定的基數后,通過文天職析和機器學習,也可以輸出地址轉坐標的能力.
如果基數非常龐大,可以選擇基于PostgreSQL的Greenplum數據倉庫,進行文天職析與機器學習(支持MADlib庫,支持R).
Greenplum支持文天職析,支持地理位置信息處理,支持MADlib機器學習庫,還支持R語言自定義函數,python函數,支持分布式并行計算. 最重要的是它開源,絕對是有文本和地理位置分析需求的用戶最好的選擇.
最佳路徑運算
以倉庫之間的數據流轉為例
必要用到PostgreSQL數據庫的PostGIS與pgrouting.
http://workshop.pgrouting.org/chapters/topology.html
基礎數據需求,用來表現開通了運輸航線的倉庫之間的線段數據,公里數據.
Road link ID (gid) 唯一,指路段號
Road class (class_id)
Road link length (length),長度,公里數
Road name (name),路名
Road geometry (the_geom),線段(可以是多點線段,也可以是雙點線段)
假設表名為ways,里面存儲的便是倉庫之間的線段信息
Table "public.ways"
Column | Type | Modifiers
----------+---------------------------+-----------
gid | bigint |
class_id | integer | not null
length | double precision |
name | character(200) |
osm_id | bigint |
the_geom | geometry(LineString,4326) |
Indexes: "ways_gid_idx" UNIQUE, btree (gid) "geom_idx" gist (the_geom)
1. 生成拓撲
要生成最佳路徑,首先要生成合法的拓撲,不然怎么生成路徑呢?
生成拓撲前,必要添加兩個字段,用來存儲線段的首尾編號
-- Add "source" and "target" columnALTER TABLE ways ADD COLUMN "source" integer;ALTER TABLE ways ADD COLUMN "target" integer;
調用pgr_createTopology生成拓撲,注意便是生成線段的首位編號的過程
pgr_createTopology('<table>', -- 必要生成拓撲的表名float tolerance, -- 容錯值,例如線段的端不能完全吻合時,允許多少誤差,單位一般為角度或公里數'<geometry column>', -- 線段列名'<gid>') -- gid
例如,ABC三條線段,其中B線段的兩端都沒有和AC完全吻合,誤差分別為1米和10米,所以必要設置容錯.

生成線段,實際上便是設置source和target的ID,設置完后,可能就變成這樣的了
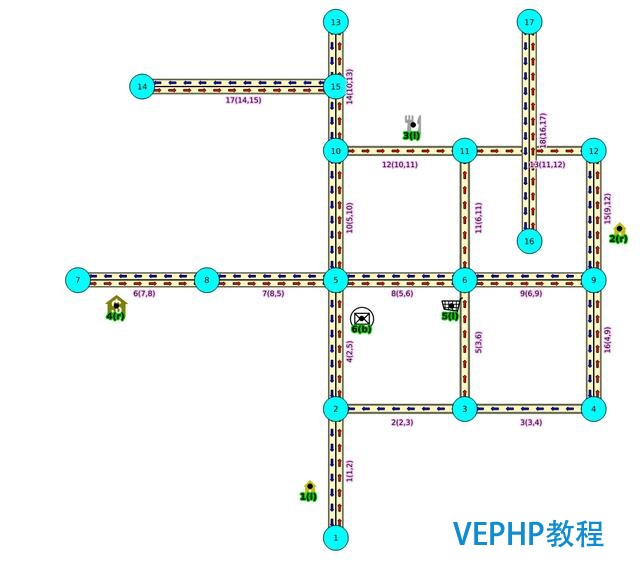
例子
-- Run topology function
SELECT pgr_createTopology('ways', 0.00001, 'the_geom', 'gid');
2. 生成最佳路徑
pgrouting支持的最佳路徑算法很多
http://docs.pgrouting.org/2.2/en/doc/index.html

這里以Shortest Path A*和Shortest Path Dijkstra為例,介紹如何生成最佳路徑
http://workshop.pgrouting.org/chapters/shortest_path.html
如果倉庫之間的線段支持雙向,回來的本錢是多少?
如果回程要考慮堵車更多一點,那么本錢就不僅僅是公里數了,還需要加上堵車的本錢.

本例加上回程本錢的字段,并設置為公里數,也就是說這條線段支持回程.
ALTER TABLE ways ADD COLUMN reverse_cost double precision;UPDATE ways SET reverse_cost = length;
2.1 Shortest Path Dijkstra算法舉例
調用
pgr_costResult[] pgr_dijkstra(text sql, -- 用于計算最佳路徑的數據來源, 用SQL表現, 例如
-- SELECT id (gid), source (線段起點id), target (線段重點ID), cost (起點到重點的本錢) [,reverse_cost (重點到起點的本錢)] FROM edge_tableinteger source, -- 規劃路徑的起點integer target, -- 規劃路徑的終點boolean directed, -- if the graph is directedboolean has_rcost -- if true, the reverse_cost column of the SQL generated set of rows will be used for the cost of the traversal of the edge in the opposite direction.);
返回多行,即路徑.
a set of pgr_costResult (seq (序號), id1 (起點id), id2 (目標ID, -1表示終點), cost (這一段的本錢)) rows, that make up a path.
例子
從30到60的最佳路徑
SELECT seq, id1 AS node, id2 AS edge, cost FROM pgr_dijkstra('
SELECT gid AS id,
source::integer,
target::integer,
length::double precision AS cost
FROM ways',
30, 60, false, false);
seq | node | edge | cost
-----+------+------+---------------------
0 | 30 | 53 | 0.0591267653820616
1 | 44 | 52 | 0.0665408320949312
2 | 14 | 15 | 0.0809556879332114
...
6 | 10 | 6869 | 0.0164274192597773
7 | 59 | 72 | 0.0109385169537801
8 | 60 | -1 | 0
(9 rows)
2.2 Shortest Path A*算法舉例
與Shortest Path Dijkstra算法類似,只是SQL必要用到每條線段的起點和重點的坐標,其他參數和pgr_dijkstra都一樣.
ALTER TABLE ways ADD COLUMN x1 double precision;ALTER TABLE ways ADD COLUMN y1 double precision;ALTER TABLE ways ADD COLUMN x2 double precision;ALTER TABLE ways ADD COLUMN y2 double precision;UPDATE ways SET x1 = ST_x(ST_PointN(the_geom, 1)); -- 線段出發點坐標xUPDATE ways SET y1 = ST_y(ST_PointN(the_geom, 1)); -- 線段出發點坐標yUPDATE ways SET x2 = ST_x(ST_PointN(the_geom, ST_NumPoints(the_geom))); -- 線段終點坐標xUPDATE ways SET y2 = ST_y(ST_PointN(the_geom, ST_NumPoints(the_geom))); -- 線段終點坐標y
調用
pgr_costResult[] pgr_astar(
sql text, -- SELECT id, source, target, cost, x1, y1, x2, y2 [,reverse_cost] FROM edge_table ,包括了起點和重點坐標,計算速度比Shortest Path A*算法快一點
source integer,
target integer,
directed boolean,
has_rcost boolean );
返回成果與pgr_dijkstra一樣
a set of pgr_costResult (seq, id1, id2, cost) rows, that make up a path.
例子
SELECT seq, id1 AS node, id2 AS edge, cost FROM pgr_astar('
SELECT gid AS id,
source::integer,
target::integer,
length::double precision AS cost,
x1, y1, x2, y2 FROM ways',
30, 60, false, false);
成果
seq | node | edge | cost
-----+------+------+--------------------- 0 | 30 | 53 | 0.0591267653820616
1 | 44 | 52 | 0.0665408320949312
2 | 14 | 15 | 0.0809556879332114
... 6 | 10 | 6869 | 0.0164274192597773
7 | 59 | 72 | 0.0109385169537801
8 | 60 | -1 | 0(9 rows)
2.3 生成多目標最佳路徑
在使用導航時,我們可以選擇途徑點,這其實便是多目標規劃的一種常見場景.
例如從杭州到萬載,途徑江山去丈母娘家休息一晚.
本例使用的算法是Multiple Shortest Paths with kDijkstra
用法與kDijkstra類似,只有一個參數不一樣,便是targets是使用數組表示的.
生成分段本錢
pgr_costResult[] pgr_kdijkstraCost(text sql, integer source, integer[] targets, boolean directed, boolean has_rcost);
例子
從10動身,到達60,70,80
SELECT seq, id1 AS source, id2 AS target, cost FROM pgr_kdijkstraCost('
SELECT gid AS id,
source::integer,
target::integer,
length::double precision AS cost FROM ways',
10, array[60,70,80], false, false);
seq | source | target | cost
-----+--------+--------+------------------ 0 | 10 | 60 | 13.4770181770774
1 | 10 | 70 | 16.9231630493294
2 | 10 | 80 | 17.7035050077573(3 rows)
生成路徑
pgr_costResult[] pgr_kdijkstraPath(text sql, integer source, integer[] targets, boolean directed, boolean has_rcost);
例子
從10動身,到達60,70,80
SELECT seq, id1 AS path, id2 AS edge, cost FROM pgr_kdijkstraPath('
SELECT gid AS id,
source::integer,
target::integer,
length::double precision AS cost
FROM ways',
10, array[60,70,80], false, false);
seq | path | edge | cost
-----+------+------+---------------------
0 | 60 | 3163 | 0.427103399132954
1 | 60 | 2098 | 0.441091435851107
...
40 | 60 | 56 | 0.0452819891352444
41 | 70 | 3163 | 0.427103399132954
42 | 70 | 2098 | 0.441091435851107
...
147 | 80 | 226 | 0.0730263299529259
148 | 80 | 227 | 0.0741906229622583
(149 rows)
小結
本文用到哪些技術
點面判斷
用法請參考PostGIS手冊
點面判斷后,按面進行聚合
路徑規劃
具體的用法請參考pgrouting的手冊以及workshop
支持哪些最優算法
非常多,具體的用法請參考pgrouting的手冊以及workshop
UDF
PostgreSQL支持python, R, C等各種自定義函數的語言
機器學習
PostgreSQL與Greenplum都支持MADlib庫,對于Greenplum的R用戶,可以使用Greenplum進行隱式的并行數據挖掘,處理大數據量的挖掘很有贊助
地址轉換成坐標
聚類算法
如果小區信息在數據庫中存儲的不是面,而是點,那么派件的點面判斷,可以用PostgreSQL或者Greenplum的K-Means聚類算法,將快件與小區進行聚合,達到同樣的目的.
用法舉例:
http://blog.163.com/digoal@126/blog/static/163877040201571745048121/
SELECT kmeans(ARRAY[x, y, z], 10) OVER (), * FROM samples;SELECT kmeans(ARRAY[x, y], 2, ARRAY[0.5, 0.5, 1.0, 1.0]) OVER (), * FROM samples;SELECT kmeans(ARRAY[x, y, z], 2, ARRAY[ARRAY[0.5, 0.5], ARRAY[1.0, 1.0]]) OVER (PARTITION BY group_key), * FROM samples;第一個參數是必要參與聚類分析的數組,第二個參數是最終分成幾類(輸出結果時類是從0開始的,如分2類的話,輸出是0和1).
第三個參數是種子參數,可以是1維或2維數組,如果是1維數組,必需是第一個參數的元素個數乘以第二個元素的值.(可以認為是給每一個類分配一個種子).
我們必要指定的種子數組,即網點覆蓋的小區或寫字樓等組成的點值數組.
PostgreSQL在地理位置處置的領域一直處于非常領先的地位,用戶群體也非常的龐大,PostGIS和pgrouting只是這個領域的兩插件.
以前還寫過一篇point cloud的數據處置相關文章,有興趣的童鞋可以參考如下
https://yq.aliyun.com/articles/57095
更多深度技術內容,請存眷云棲社區微信公眾號:yunqiinsight.
維易PHP培訓學院每天發布《當物流調度遇見PostgreSQL-機器學習》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9632.html
同類教程排行
- 小白入門-新手學習-網絡基礎-ms17-
- 如何找對業務G點, 體驗酸爽?Postg
- 在Kubernetes部署可用的Post
- Oracle和PostgreSQL的最新
- 解讀數據庫《超體》PostgreSQL
- MySQL和PostgreSQL:國內外
- 針對PostgreSQL的最佳Java
- 為PostgreSQL討說法:淺析Ube
- PostgreSQL測試工具PGbenc
- go 語言操作數據庫 CRUD
- 白帽黑客教程2.5Metasploit中
- JIRA使用教程:連接數據庫-Postg
- 德歌:PostgreSQL獨孤九式搞定物
- 大數據最大難關之模糊檢索,Postgre
- 當物流調度遇見PostgreSQL-機器
