解讀數據庫《超體》PostgreSQL
《解讀數據庫《超體》PostgreSQL》要點:
本文介紹了解讀數據庫《超體》PostgreSQL,希望對您有用。如果有疑問,可以聯系我們。
相關主題:PostgreSQL教程
講師介紹
digoal(德哥),現任職于阿里云數據庫內核技術架構組.PostgreSQL中國社區發起人之一、常委、兼任社區年夜學校長,PostgreSQL中國社區杭州分會會長,PostgreSQL中國社區年夜學發起人之一.14項已授權專利.樂于分享,撰寫技術類文章幾千余篇,狂熱技術分子,致力于PostgreSQL數據庫在中國的技術推廣與人才教育.
“超體”這個例子來源于一部電影,電影中探討當人的腦細胞被開發到100%的時候會達到一個什么樣的現象.同樣的,本日我們以PostgreSQL為例,看看當數據庫被開發至100%會產生什么,是不是可以解放程序猿的雙手,節約50%的開發時間去撩妹?(¬?¬)σ
20%
1、物聯網、金融、日志、運營商網管、行為軌跡類數據
20%的時候會是什么樣子的?先來看一個場景,現在非常流行物聯網的場景,包含金融、運營商網關,還有電商,然后很多的一些O2O的平臺采集用戶的信息.因為每一次手機上的操作,點擊都會記錄下來,以便后面做一些用戶行為挖掘的動作.那么這些數據有什么樣的特征?
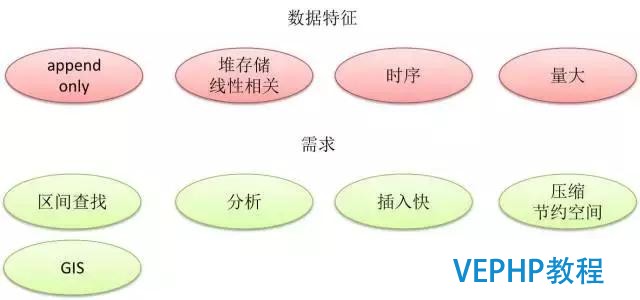
行為數據的特征包含追加寫,不停地寫入,同時在時間和維度上跟你的堆存儲存在一定的線性關系.行為數據的數據量是很大的,一個業務的日記錄數以億到百億記.
查詢需求方面,需求方可能需要查一個群體性數據在某一個時間點發生的行為,這是時間區間查詢的需求.第二個查詢需求可能是分析需求,好比群體性的特征分析,這么大一個數據量的情況下,會要求插入快,因為插入慢的話就有丟數據的風險(就像網絡丟包一樣,可能導致重傳和擁塞,影響用戶體驗).
存儲的要求,要支持壓縮,比如說我插的數據這么大的量不能壓縮,在成本上可能是扛不住的,業務方想保存一年的數據,壓縮與不壓縮成本可能相差好幾倍.
數據種類的需求.隨著物聯網的發展,終端采集的數據越來越多樣化,傳統的數字、字符串、時間是比擬常見的,現在可能還會加入更多的類型,比如定位的信息,而且事件的發生有時間和空間的維度在里面,越來越多的用戶需要支持更多的數據類型.
2、PostgreSQL塊級別索引– BRIN
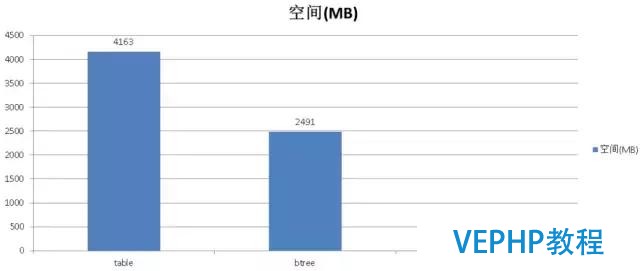
我們看一下檢索,假設一天產生幾十個G的數據,用戶想找到12點前后五分鐘的數據在哪里,但想一想一天幾百個GB的數據,索引有多大呢,那么什么辦法可以減少索引的大小?
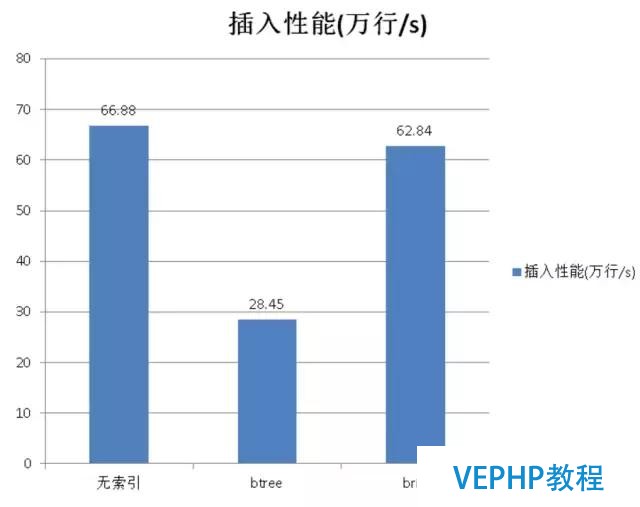
在這里可以使用塊級存儲,比如一個數據塊是一兆,這一兆的數據里面覆蓋了某個字段從幾點到幾點的信息,塊級索引只需要存儲邊界值、COUNT、SUM等信息,所以塊級索引會變得很小很小.使用了塊級別索引后你耗費的空間相比本來下降幾百倍,如果一個數據塊可以存兩百條記錄的話,你的索引會變成是本來兩百分之一那么小,而檢索的速度是沒有受到影響的(前提是被索引的字段數據的邏輯順序與對存儲的物理順序有線性相關性).
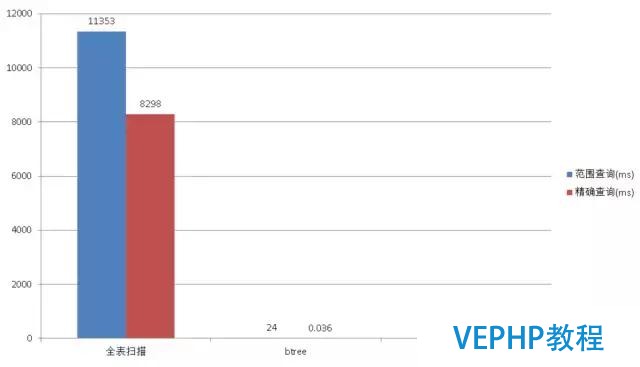
從圖上看單步插入的速度,比本來使用快了很多.
接下來我們看一下看壓縮的需求.壓縮這一塊,其實有很多的算法,有有損壓縮(旋轉門壓縮)和無損壓縮(列存儲:瓦片式/內置/FDW/IMCS).好比說旋轉門的壓縮,這個是來自于一個做電力的監控系統:
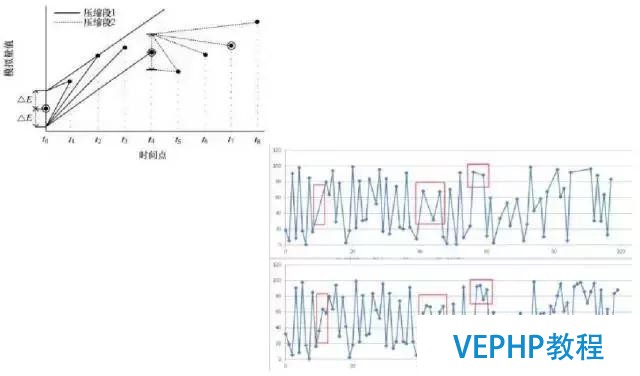
一個發電廠有很多的傳感器,這些傳感器每十毫秒就上傳一個數據,數據量是非常龐大的.這里有一個旋轉門壓縮轉盤,在這個數據庫里面可以寫一個UDF實現一個同樣的功能.剛剛講的這個功能,有一個非常典型的應用便是在阿里的菜鳥中有一個跟蹤系統有用到這個產品里面的特性.
第二個場景為搜索類、多維度交互類的場景.比如說淘寶前端的頁面,我們在做一些搜索的時候,我要找銷量大于多少的,還是依照店鋪名稱找,還是依照商品名找,或者是依照商品的地區搜索等等.我們在搜索時有很多選擇,但表設計好之后有幾十個字段,每個字段都有可能是客戶選擇的選項,如果是針對每一個字段建索引的話,雖然你滿足了用戶的需求,但是會帶來很大性能的插入和更新性能的損耗.同時用戶可能是依照某一個字段做模糊的搜索.

在PostgreSQL數據庫里面可以幫你做這件事情,它的原理非常簡單,就是通過這種倒排的辦法做索引(GIN),還有其它的辦法比如通過空間索引(GiST),通過這種辦法可以實現任意字段的檢索.
現在許多開發者會使用JSON存取數據,當設計之初,也許無法固定結構設計,那么可以用到PostgreSQL的JSON的數據類型,JSON內容的檢索與普通字段的檢索辦法一樣,同樣支持模糊查詢.
典型的用戶:在阿里里面一個是淘系用戶,這個任意字段檢索的特性用得比擬多.還有萬網和阿里云的官網.最后一個是相似的搜索,比如說一篇文章里面涉及到一百個商品,別人寫的文章里面涉及50多個商品,你跟他有40個是重疊的,怎么搜出來?這個是通過相似索引搜出來的,它達到的效果也是很高的,可以在幾個毫秒之內就在上億的數據里面幫你搜索出與你提供的數據相似的數據.

3、高效率規模查詢
再看看第三個場景——范圍數據.范圍數據出現最多的地方是物聯網.在物聯網里面它的傳感器要不停上報數據,但是好比說一些溫度傳感器,或者是濕度等等指標的傳感器,它的范圍波動是很小的.像電壓的波動,可能一直就在220左右波動的,假如一個小時上來的數據全部在這個范圍內波動,實際上在后臺根本沒必要每一個值都存下來,我可以直接存一個范圍,假設你的偏差精確到99.9%在業務上是可以容忍的,這時候我完全不需要把每一個精確的值存下來.
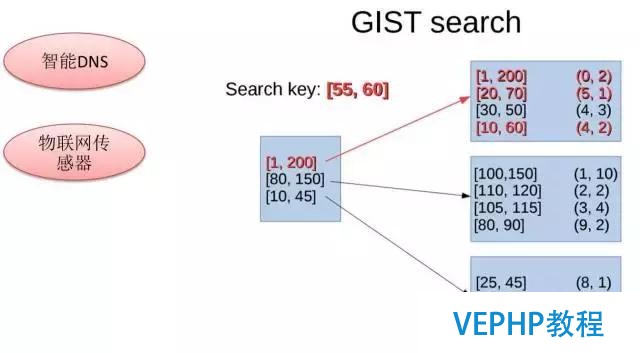
存取范圍,涉及到范圍類型,也是一個比較有趣的特性,比如說1到2,這種數值經常做什么樣的檢索呢?今天所有的傳感器上報的數據里面,哪些是100-200之間的數據,依照原來的設計兩個字段索引做搜索,是可以實現的,但是效率比較差,如果使用范圍索引來做的話,實測性能提升20多倍.GiST對范圍數據做聚類劃分,搜索時可以快速定位到需要搜索的范圍.
規模數據類型,典型應用場景是物聯網,以及智能DNS.智能DNS會根據你IP的來源落到某一個規模里,再去索引你到最近的庫里面去.
接下來講一個比較有意思的場景,求數據差集,用到數據庫的遞歸查詢特性.比如說一張表是一億數據的,用車輛ID這個場景說明.業務背景是商用車輛的軌跡跟蹤,在一家企業里面,假設有一百萬輛商用的車輛,一天可能上傳幾億的軌跡數據上來,但用戶想查今天沒有出勤的車輛,怎么查?使用遞歸的辦法可以做到0.幾毫秒,也是非常有意思的事情.而傳統的辦法,使用left join,需要幾秒.
遞歸查詢,典型的用戶好比說區塊鏈,還有ERP系統里面有很多的關系,特別是一個大數據,小數據的清洗.
40%
當數據庫施展到40%功能的時候看一下是什么樣的.
1、數據庫端編程
我們用傳統的辦法去寫一個應用時,肯定就是讓數據庫做該做的東西,我要的時候告訴你要查出什么樣的數據,但是一來一回,耗費在網絡上的開銷就變得特別大.特別是在銀行這種系統里面,開戶一開就是1個小時過去了,里面可能跟數據庫交互多少次,那如果說這個時候你把這個程序邏輯寫到數據庫里面去的話,實際很多場景里面也在用的,特別是銀行這些事務處理非常復雜,同時要求數據可靠性、一致性很高的場景用得比較多.所以實際上存儲過程在銀行、運營商用得比較多.
一種辦法是在外面用程序做,跟數據庫交互若干次,另一種辦法是跟數據庫交互很少的次數,就是你把邏輯放到數據庫中,我們來看一下可以達到什么樣的效果?
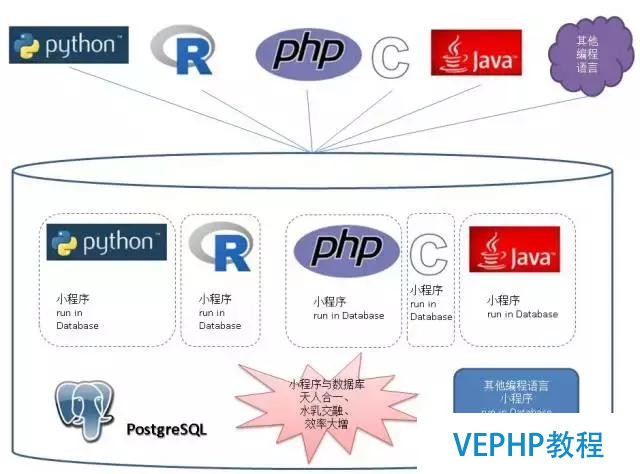
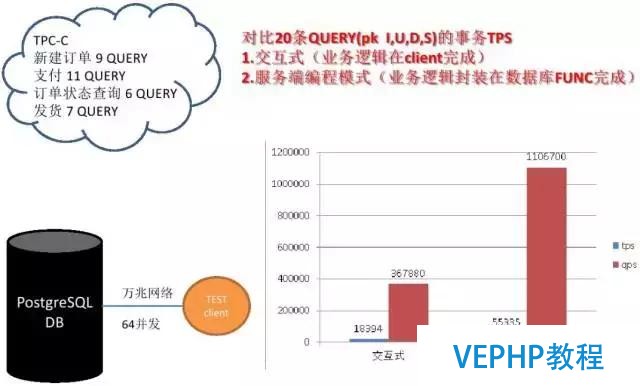
我們測試過萬兆網的場景,辦事物的處理,20條Query使用交互式的方式,還有使用邏輯全部放在數據庫這一端做的,他們出來的差別可以看一下,使用邏輯數據庫可以達到100萬的QBS,如果把數據庫放到云端的不同主機的話,數據庫延遲可能更大,所以如果業務對延遲響應苛刻、并且業務邏輯允許的情況下,建議你放到數據庫里面.
2、異步消息
問大家一個問題,當你要監控上萬臺,或者幾十萬臺設備時,你后端需要多少個數據庫?也是跟互聯網的傳感器一樣,你有若干個監控指標,每一個設備每一秒可能會產生上千個指標,傳到你的數據庫里面去,當數據有異常的情況,通知服務端,這就是異步消息所在.數據不停往數據庫里面插,發現有異常的時候,就通過異步消息告訴程序有異常,通過這種辦法可以做到百萬的NVPS,這是一個數據庫可以做到的.然后硬件的話實際上也是用普通的X86場景.后面會詳細的講這個流式計算的功能.
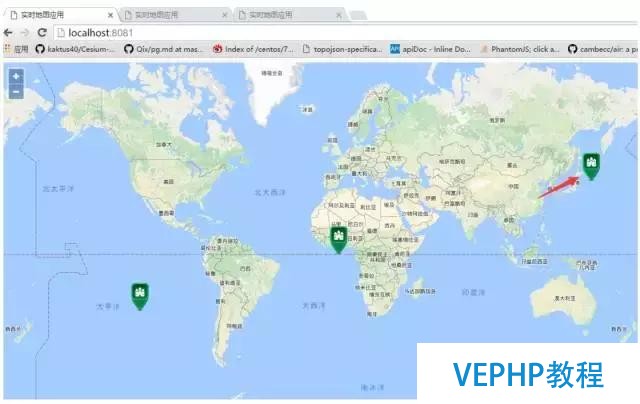
這個是基于地理位置放了很多的傳感器,這些傳感器不絕地上報數據,這些數據發生異常時,就告訴你這里發生異常了,通過異步的方式來實現.
3、數據泵
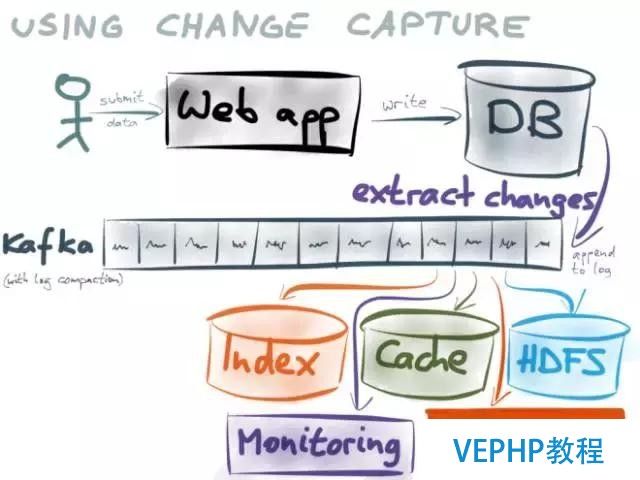
數據泵也是有意思的場景,特別是在一些歷史悠久的企業里面,各種數據庫都有,這么多的數據庫或者數據產品,他們要共享數據怎么辦?最開始我的數據往關系數據庫里寫的,但是如果要共享給其它的平臺,怎么樣實時地分享?那就用數據泵,這個東西便是數據庫內置的一個消息隊列的插件,通過REDO的結合實時對外分享數據.
4、天文、地輿
另外一個是現在需用到非常多數據的,特別是像O2O的產品,或者是基于位置的產品,商用車的管理、危化品車管理等.好比說一個綜合體里面可能每一層都會有商鋪,實際上有很多的產品是有這個定位功能的,但是他現在只有高度,我在手機上搜索的時候,能告訴你所在層有哪一些商鋪.PostGIS是一個空間數據管理插件,可以高效的存儲多維度數據.

好比基于這個位置附近搜人,最近我們菜鳥做性能跟蹤時,最后壓出來的結果讓我們很驚訝,PostGIS壓出來的性能比Redis好400%.但它差在什么地方呢?它就差在索引的效率上面,所以最后菜鳥選擇了使用這個來做軌跡系統.
除了民用場景,在軍工和科研方面,還要存三格數據等等一系列的數據.許多從互聯網發展起來的數據庫產品不會考慮這些場景,但是PostGIS來自高校的,有比較深的科研配景,因此這一塊應用非常的廣泛.幾乎全球的宇航局、導航系統、氣象系統、天文研究、軍工方面涉及空間數據的場景,都在使用PostGIS.

這個是十二生肖的3D數據,實際上給一個物品做3D的掃描,3D掃描之后除了每一個地位信息之外,還有屬性如材質、顏色等,這里面存的不僅僅是地位信息,還有其它的屬性在里面,通過pgpointcloud可以把這些掃描值存到一個對象里面.
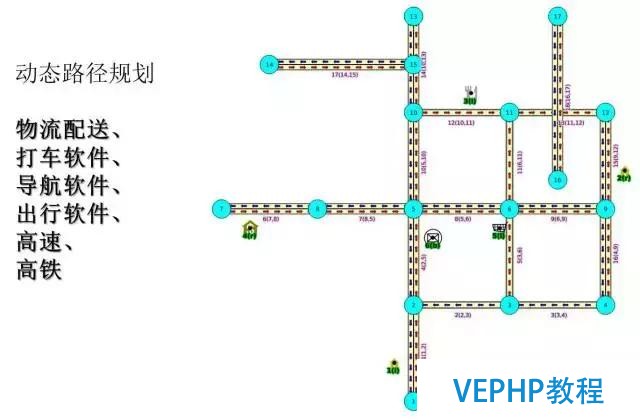
最后還有一個特別重要的功能就是路由的功能,從A到B怎么樣提供最優的路徑出來,在行進過程中不斷優化你的路徑.典型的應用場景,好比說物流等.
60%
1、流式處置
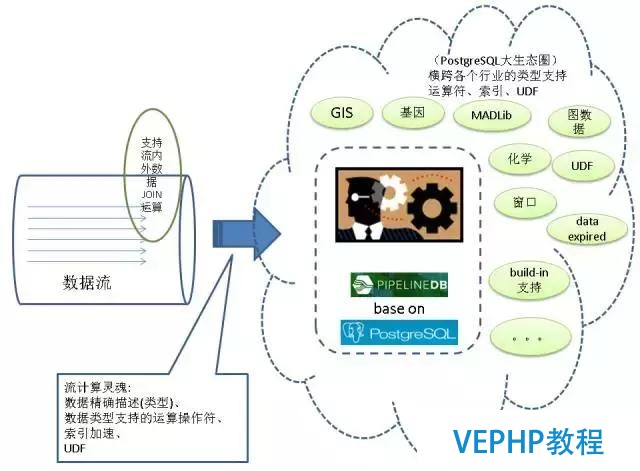
流式處理的話,剛剛提到了是監控的場景.流式處理每一條上報的監控 ,如果有異常的話,通過異步消息的方式來通知我們的應用程序.另一個非常有趣的例子,就在近日,三體高層架構發起的一次PCC性能大賽,場景是涉及到Facebook的關系,Like的場景,可以查到某一篇文章被Like的次數,或者是查出某一篇文章Like的好友中哪些是我的好友.這個關系說很繞,比賽的設計的目標是30萬的哀求被Like的次數,還有被哪些人Like.使用流計算的話,查到某一篇文章被Like的次數,查被哪些人Like,均可以達到100萬的QPS,查出某一篇文章Like的好友中哪些是我的好友可以達到70萬的QPS,超出設計目標,而僅僅使用了PostgreSQL的一個流計算功能.
2、Zabbix
流計算與異步消息結合,可以達到什么樣的效果呢?如果拿Zabbix來做流式監控的話就可以用這種辦法.Zabbix原生是主動的詢問方式來了解是否發生了異常,很浪費資源.使用這種異步機制,僅僅在真正有問題的時候,才會通知客戶端,大大減少了主動問詢的無用功開銷.
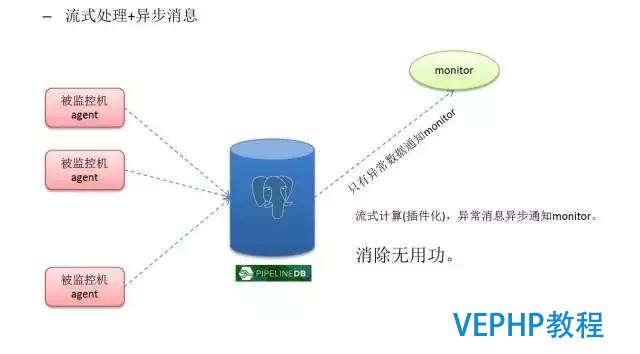
3、網狀關系搜索應用、金融風控、公安刑偵、社會關系、人脈闡發
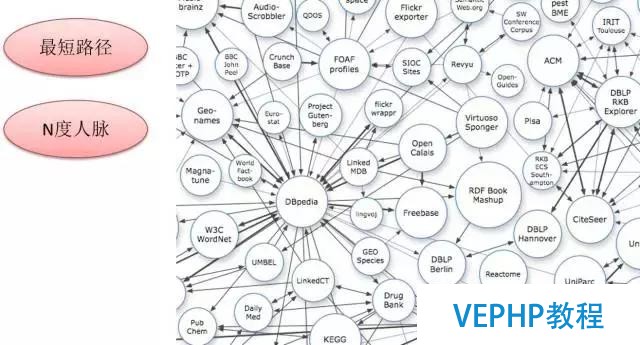
這里提到了一個關系的圖示查詢,這個的話之前也寫過一篇這樣的文章,寫得比擬詳細,就是使用PostgreSQL怎么樣做圖式搜索.我測了一個一千億的關系,一億的用戶,每個人有一千條邊關系,達到的性能是什么樣的,查兩個人最短關系路徑的時候,要看關系路徑有多遠,比如說4級以內的話在秒級以內響應,查詢N度人脈則可以做到毫秒級的響應.
4、相似內容判定、按標簽圈人
再看一下相似判斷,場景是導購平臺.現在我有上億的導購的文章,每一篇文章對應一些導購的商品,當有新的用戶發導購文章的話,我得確保他沒有盜文,也就是說必須找有沒有相似的導購文章,這個事情通過PostgreSQL來辦理.
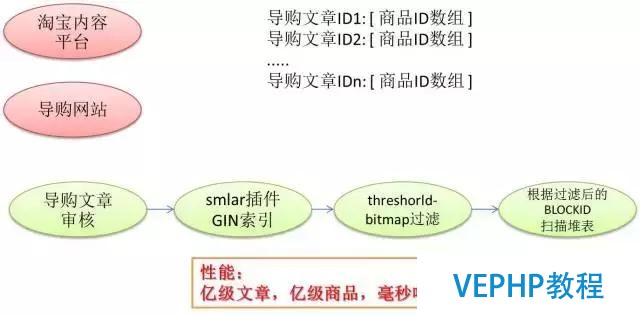

5、圖像辨認、AR紅包
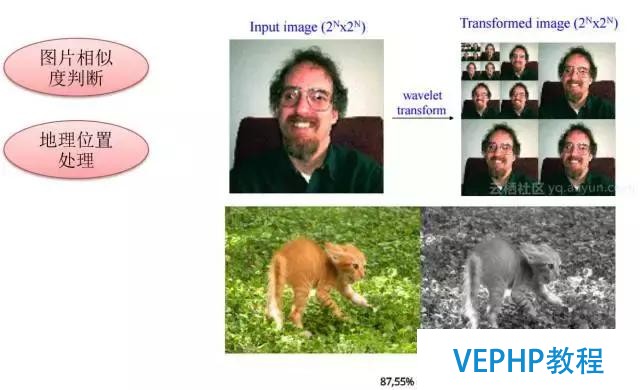
圖象識別比較有意思,你只要把圖像的特征傳入到數據庫里面,數據庫就可以幫你做這件事情.只要實現GIN或GIST索引里面特定的幾個接口就可以使用索引來檢索相似的圖片,包含圖像相似挖掘也是這樣的.這個效率也很高,我有測過大概是五千萬的圖片,查詢相似的圖片可以做到毫秒級的響應.
這個應用場景是比擬有意思的,特別是現在興起的圖搜,在看電視劇時發現包包挺好看的,拍下來搜一下,這個搜一下的過程就是采集這張圖片,然后把它的特征值根據數據庫反饋給我,告訴哪一個店在賣這個產品.
6、Real Sharding(無限制Sharding)
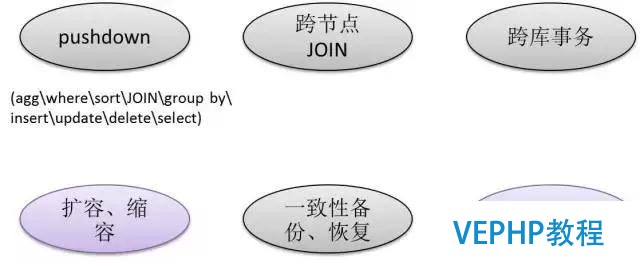
很多數據庫支持Sharding,但是并不是特別的完美,Sharding后的使用體驗與單機版本會不一樣.這也不能,那也不能,就像你原來的數據庫被閹割了一樣,對很多人來說很不爽.原來做什么都可以,現在Sharding是不能這樣干的,而PostgreSQL 10推出之后,在Sharding這一塊有特別多的增強.10做了幾件事情,一個是pushdown,就是在下面的數據庫里面計算,所以可以干跟原來一樣的事情,跨節點交易也是可以做的,包含一致性備份等等.
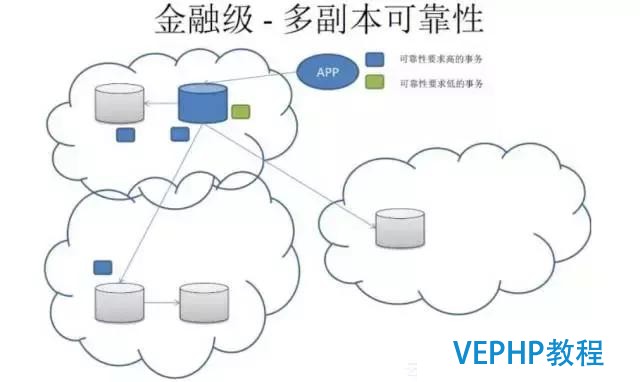
另外是多副本,基于事務這個級別,比如說A事務涉及到用戶的賬目信息,要保證兩個副本才可以告訴寫成功.而如果你這個事物是日志型的,要求RT比較低的,這時候你只要告訴他落到當地就可以的,這時候只需要寫一個副本.這個多副本的功能設計得非常靈活,可以滿足混合場景的需求.
80%
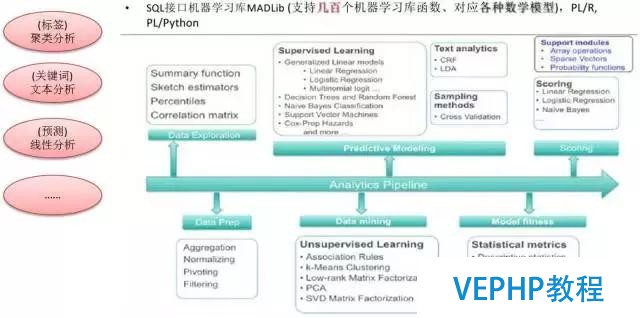
1、機器學習庫(MADlib)
再往后80%可以做機器學習,MADlib這個庫是MIT與Pivotal共同研發并開源的一個機器學習庫,使用起來是SQL的接口.你需要告訴它(UDF)訓練集表是哪個,輸出訓練結果到哪里,使用什么算法等.好比說做數據的分析,關健詞的分析等等都可以做.
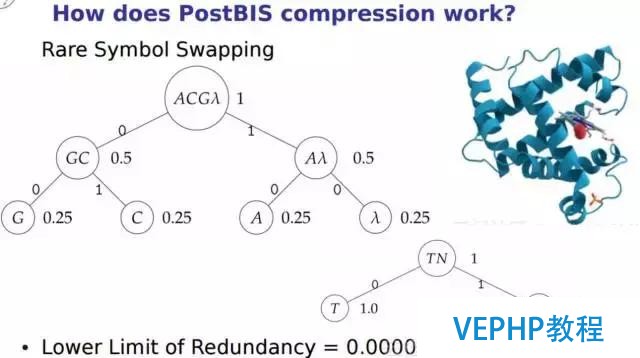
2、基因數據處置(存、取、檢索;類型、索引、操作符、函數、UDF)
接下來還有一些比擬奇特的,比如說在數據庫里面存基因,基因的數據有比擬單一的屬性(TOKEN),不同的DNA串,體系了不一樣的連接的順序.使用這個postbis存的話,可以做基因相似的查詢等等這樣的一些操作,所以也比擬有意思.
化學物品也可以存儲在數據庫中,在數據庫中可以模擬化學品的合成,化學品的闡發,約束等.
3、融合
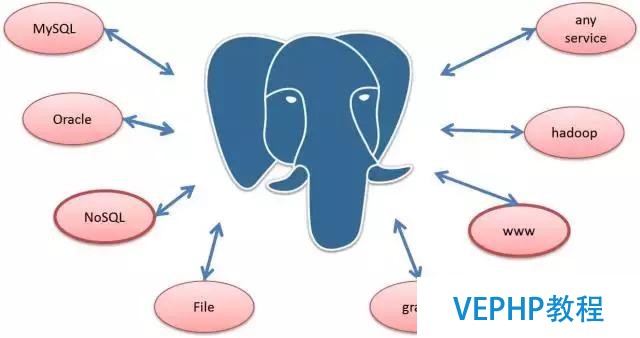
融合是指將不同的數據源打通,PostgreSQL的FDW接口,可以拜訪世界上幾乎任何一種的數據源,只要建立一個外部表就可以拜訪外部數據了,拜訪接口依舊是SQL接口.
FDW在云端有什么樣的用處?云端很多的數據是以很多其他的形式存在的,比如說阿里有一個對象的存儲OSS,把歷史的數據用來做分析,不需要每時每刻查,這些數據做的操作全部是分析型的操作,我們把這種數據存到OSS里面,這時候數據庫本身的存儲可以縮小,可以壓縮你的本錢.
100%

最后100%這里要表達的意思是你可以想象的功能都可以拓展出來.最后幾頁PPT是阿里云的一些比較大的客戶經典的應用場景.比如說這個場景是做網絡軌跡分析的,它的數據量達到幾百T,有大量數據存在OSS對象存儲里面,RDSPostgreSQL與HybridDB PostgreSQL連接OSS的通道是并行的,比如說HybridDB PostgreSQL有一百個節點,每一個節點都可以拜訪OSS,在做分析處理的時候,吞吐可以做到非常大.做到了計算與存儲的分離.
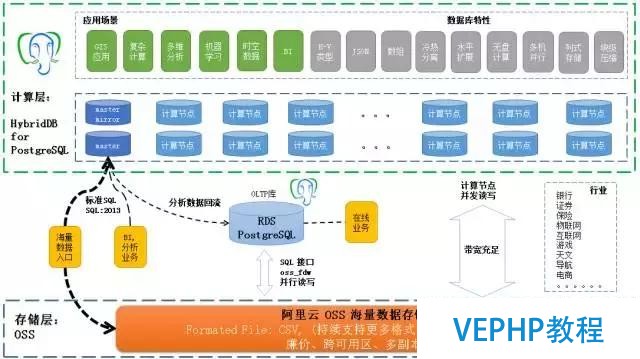
上面藍色和灰色的方框是說這個數據庫的計算能力有哪一些,能干什么事情,下面是數據庫的計算單元,再下面便是你外部存儲,你數據可以存在計算單元里面,也可以存儲在OSS對象存儲里面,取決于數據的熱度.當分析好之后,數據可以回流到OLTP數據庫中.
計算與分離,除了本錢上的優勢,另一個好處是擴容顯得更加從容,因為不再需要move數據了.
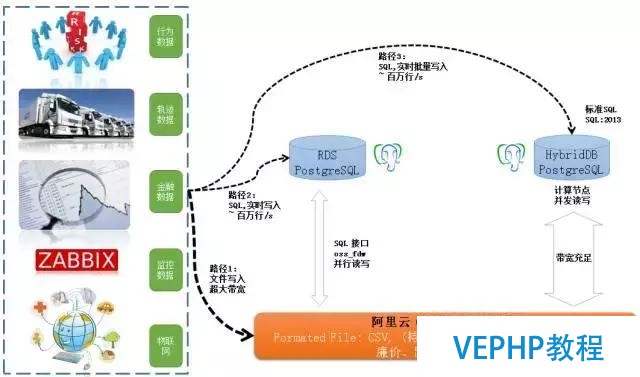
最后這張圖表現,數據的入庫通道,對應的帶寬和時延,用戶可以根據實際的需求選擇數據的通道.
Q&A
Q1:好比說我自拍一個再找相似度,是不存在的,會如何?
A1:關于圖片相似度的查詢,查詢條件中可以設置相似度的閾值,如果你拍的圖片根本不存在的話,通過閾值就可以排除,也便是說查詢不到結果.不管有沒有結果,都是走索引的,所以效率非常高.
Q2:把邏輯存放在數據里面,數據庫服務器的負載有時候并發量大的時候,負載是不是蒙受不起?
A2:不管邏輯放在數據庫里面還是外面,負載取決于業務量,而業務的增長是可以預估的,不會說突然就暴漲(除了搞活動,但是也能預估),我們回到邏輯放到庫里面的那張圖,達到的TPS實際上是更高的,如果邏輯在數據庫外面10萬的本錢達到30萬TPS,同樣的本錢放到數據庫里面可以達到100萬的TPS,實際上放在外面時引入了更多的損耗,所以你怎么看待這個問題呢?10萬塊錢已經幫你做了30多萬的事情.
End.
文章轉載自:DBAplus社群
中國統計網,是國內最早的大數據學習網站,歡迎關注!
<style> #pgc-card .pgc-card-href { text-decoration: none; outline: none; display: block; width: 100%; height: 100%; } #pgc-card .pgc-card-href:hover { text-decoration: none; } /*pc 樣式*/ .pgc-card { box-sizing: border-box; height: 164px; border: 1px solid #e8e8e8; position: relative; padding: 20px 94px 12px 180px; overflow: hidden; } .pgc-card::after { content: " "; display: block; border-left: 1px solid #e8e8e8; height: 120px; position: absolute; right: 76px; top: 20px; } .pgc-cover { position: absolute; width: 162px; height: 162px; top: 0; left: 0; background-size: cover; } .pgc-content { overflow: hidden; position: relative; top: 50%; -webkit-transform: translateY(-50%); transform: translateY(-50%); } .pgc-content-title { font-size: 18px; color: #222; line-height: 1; font-weight: bold; overflow: hidden; text-overflow: ellipsis; white-space: nowrap; } .pgc-content-desc { font-size: 14px; color: #444; overflow: hidden; text-overflow: ellipsis; padding-top: 9px; overflow: hidden; line-height: 1.2em; display: -webkit-inline-box; -webkit-line-clamp: 2; -webkit-box-orient: vertical; } .pgc-content-price { font-size: 22px; color: #f85959; padding-top: 18px; line-height: 1em; } .pgc-card-buy { width: 75px; position: absolute; right: 0; top: 50px; color: #406599; font-size: 14px; text-align: center; } .pgc-buy-text { padding-top: 10px; } .pgc-icon-buy { height: 23px; width: 20px; display: inline-block; background: url('https://s0.pstatp.com/pgc/v2/pgc_tpl/static/image/commodity_buy_f2b4d1a.png'); } </style>
<style> #pgc-card .pgc-card-href { text-decoration: none; outline: none; display: block; width: 100%; height: 100%; } #pgc-card .pgc-card-href:hover { text-decoration: none; } /*pc 樣式*/ .pgc-card { box-sizing: border-box; height: 164px; border: 1px solid #e8e8e8; position: relative; padding: 20px 94px 12px 180px; overflow: hidden; } .pgc-card::after { content: " "; display: block; border-left: 1px solid #e8e8e8; height: 120px; position: absolute; right: 76px; top: 20px; } .pgc-cover { position: absolute; width: 162px; height: 162px; top: 0; left: 0; background-size: cover; } .pgc-content { overflow: hidden; position: relative; top: 50%; -webkit-transform: translateY(-50%); transform: translateY(-50%); } .pgc-content-title { font-size: 18px; color: #222; line-height: 1; font-weight: bold; overflow: hidden; text-overflow: ellipsis; white-space: nowrap; } .pgc-content-desc { font-size: 14px; color: #444; overflow: hidden; text-overflow: ellipsis; padding-top: 9px; overflow: hidden; line-height: 1.2em; display: -webkit-inline-box; -webkit-line-clamp: 2; -webkit-box-orient: vertical; } .pgc-content-price { font-size: 22px; color: #f85959; padding-top: 18px; line-height: 1em; } .pgc-card-buy { width: 75px; position: absolute; right: 0; top: 50px; color: #406599; font-size: 14px; text-align: center; } .pgc-buy-text { padding-top: 10px; } .pgc-icon-buy { height: 23px; width: 20px; display: inline-block; background: url('https://s0.pstatp.com/pgc/v2/pgc_tpl/static/image/commodity_buy_f2b4d1a.png'); } </style>
<style> #pgc-card .pgc-card-href { text-decoration: none; outline: none; display: block; width: 100%; height: 100%; } #pgc-card .pgc-card-href:hover { text-decoration: none; } /*pc 樣式*/ .pgc-card { box-sizing: border-box; height: 164px; border: 1px solid #e8e8e8; position: relative; padding: 20px 94px 12px 180px; overflow: hidden; } .pgc-card::after { content: " "; display: block; border-left: 1px solid #e8e8e8; height: 120px; position: absolute; right: 76px; top: 20px; } .pgc-cover { position: absolute; width: 162px; height: 162px; top: 0; left: 0; background-size: cover; } .pgc-content { overflow: hidden; position: relative; top: 50%; -webkit-transform: translateY(-50%); transform: translateY(-50%); } .pgc-content-title { font-size: 18px; color: #222; line-height: 1; font-weight: bold; overflow: hidden; text-overflow: ellipsis; white-space: nowrap; } .pgc-content-desc { font-size: 14px; color: #444; overflow: hidden; text-overflow: ellipsis; padding-top: 9px; overflow: hidden; line-height: 1.2em; display: -webkit-inline-box; -webkit-line-clamp: 2; -webkit-box-orient: vertical; } .pgc-content-price { font-size: 22px; color: #f85959; padding-top: 18px; line-height: 1em; } .pgc-card-buy { width: 75px; position: absolute; right: 0; top: 50px; color: #406599; font-size: 14px; text-align: center; } .pgc-buy-text { padding-top: 10px; } .pgc-icon-buy { height: 23px; width: 20px; display: inline-block; background: url('https://s0.pstatp.com/pgc/v2/pgc_tpl/static/image/commodity_buy_f2b4d1a.png'); } </style>
歡迎參與《解讀數據庫《超體》PostgreSQL》討論,分享您的想法,維易PHP學院為您提供專業教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9203.html
同類教程排行
- 小白入門-新手學習-網絡基礎-ms17-
- 如何找對業務G點, 體驗酸爽?Postg
- 在Kubernetes部署可用的Post
- Oracle和PostgreSQL的最新
- 解讀數據庫《超體》PostgreSQL
- MySQL和PostgreSQL:國內外
- 針對PostgreSQL的最佳Java
- 為PostgreSQL討說法:淺析Ube
- PostgreSQL測試工具PGbenc
- go 語言操作數據庫 CRUD
- 白帽黑客教程2.5Metasploit中
- JIRA使用教程:連接數據庫-Postg
- 德歌:PostgreSQL獨孤九式搞定物
- 大數據最大難關之模糊檢索,Postgre
- 當物流調度遇見PostgreSQL-機器
