大數(shù)據最大難關之模糊檢索,PostgreSQL如何攻克!
《大數(shù)據最大難關之模糊檢索,PostgreSQL如何攻克!》要點:
本文介紹了大數(shù)據最大難關之模糊檢索,PostgreSQL如何攻克!,希望對您有用。如果有疑問,可以聯(lián)系我們。
相關主題:PostgreSQL教程
活動要寫在最前面,因為本日的干貨文章實在太長了!:)提醒超過20000字了.只好刪減一些,詳細閱讀請看云棲社區(qū)頭條.
云棲社區(qū)也有”小金人“了!送給3月云棲社區(qū)2016年第2-10期在線培訓的8位CTO大神.目前,3月4日10:00-10:40,第2期《游族網絡:如何運維千臺以上游戲云服務器》正在火熱報名.轉發(fā)”小金人“到朋友圈,并在直播期間積極留言,我們將挑選優(yōu)秀留言提問者贈送技術冊本哦!

正文來了!感謝德哥的分享.重要的事情重復三遍:技術干貨,技術干貨,技術干貨!
作者:阿里云數(shù)據庫專家 德哥
來源:云棲社區(qū)
鏈接:https://yq.aliyun.com/articles/7444
轉載分享請帶上述版權聲明!
大數(shù)據正在向我們奔來.盡管業(yè)務場景不會完全相同,但在其中一個最典型場景——模糊檢索中,技術需求卻出奇的一致.
好比說:
物聯(lián)網,往往會產生大量的數(shù)據,除了數(shù)字數(shù)據,還有字符串類的數(shù)據,例如條形碼,車牌,手機號,郵箱,姓名等.假設用戶需要在大量的傳感數(shù)據中進行模糊檢索,甚至規(guī)則表達式匹配,有什么高效的辦法呢?
醫(yī)藥,市面上發(fā)現(xiàn)了一批藥品可能有問題,需要對藥品條碼進行規(guī)則表達式查找,找出復合條件的藥品流向.但怎么才能在如此復雜的系統(tǒng)中,用高效辦法來實現(xiàn)?
公安,偵查行動時,有可能需要線索的檢索.如用戶提供的殘缺的電話號碼,郵箱,車牌,IP地址,QQ號碼,微信號碼等進行交叉搜索,根據這些信息加上時間的疊加,模糊匹配和關聯(lián),最終找出罪犯.但這個流程,可有高效辦法?
相同的需求還有很多.幾乎每一個模糊匹配的場景下,都必要正則表達式匹配,這和人臉拼圖有點類似,我們已經看到強烈的需求已經產生.但技術方面,要怎么做更好?
在我看來:正則匹配和模糊匹配通常是搜索引擎的特長,但是如果你使用的是PostgreSQL數(shù)據庫照樣能實現(xiàn),而且性能不賴,加上分布式方案 (譬如 plproxy, pg_shard, fdw shard, pg-xc, pg-xl, greenplum),處理百億以上數(shù)據量的正則匹配和模糊匹配效果杠杠的,同時還不失數(shù)據庫固有的功能,絕對是一舉多得.
首先對應用場景進行一下分類,以及現(xiàn)有技術下能使用的優(yōu)化手段.
.1. 帶前綴的模糊查詢,例如 like 'ABC%',在PG中也可以寫成 ~ '^ABC'
可以使用btree索引優(yōu)化,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
.2. 帶后綴的模糊查詢,例如 like '%ABC',在PG中也可以寫成 ~ 'ABC$'
可以使用reverse函數(shù)btree索引,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
.3. 不帶前綴和后綴的模糊查詢,例如 like '%AB_C%',在PG中也可以寫成 ~ 'AB.C'
可以使用pg_trgm的gin索引,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
.4. 正則表達式查詢,例如 ~ '[\d]+def1.?[a|b|0|8]{1,3}'
可以使用pg_trgm的gin索引,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
PostgreSQL pg_trgm插件自從9.1開始支持模糊查詢使用索引,從9.3開始支持規(guī)則表達式查詢使用索引,大大提高了PostgreSQL在刑偵方面的才能.
代碼見 https://github.com/postgrespro/pg_trgm_pro
pg_trgm插件的原理,將字符串前加2個空格,后加1個空格,組成一個新的字符串,并將這個新的字符串依照每3個相鄰的字符拆分成多個token.
當使用規(guī)則表達式或者模糊查詢進行匹配時,會檢索出他們的近似度,再進行filter.
GIN索引的圖例:
從btree檢索到匹配的token時,指向對應的list, 從list中存儲的ctid找到對應的記錄.
因為一個字符串會拆成很多個token,所以沒插入一條記錄,會更新多條索引,這也是GIN索引必要fastupdate的原因.
正則匹配是怎么做到的呢?
詳見 https://raw.githubusercontent.com/postgrespro/pg_trgm_pro/master/trgm_regexp.c
實際上它是將正則表達式轉換成了NFA格式,然后掃描多個TOKEN,進行bit and|or匹配.
正則組合如果轉換出來的的bit and|or很多的話,就必要大量的recheck,性能也不能好到哪里去.
下面針對以上四種場景,實例講解如何優(yōu)化.
帶前綴的模糊查詢,例如 like 'ABC%',在PG中也可以寫成 ~ '^ABC'
可以使用btree索引優(yōu)化,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
例子,1000萬隨機發(fā)生的MD5數(shù)據的前8個字符.
帶前綴的模糊查詢,不使用索引必要5483毫秒.
帶前綴的模糊查詢,使用索引只必要0.5毫秒.
.2. 帶后綴的模糊查詢,例如 like '%ABC',在PG中也可以寫成 ~ 'ABC$'
可以使用reverse函數(shù)btree索引,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
帶后綴的模糊查詢,使用索引只必要0.5毫秒.
.3. 不帶前綴和后綴的模糊查詢,例如 like '%AB_C%',在PG中也可以寫成 ~ 'AB.C'
可以使用pg_trgm的gin索引,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
前后模糊查詢,使用索引只必要3.8毫秒.
.4. 正則表達式查詢,例如 ~ '[\d]+def1.?[a|b|0|8]{1,3}'
可以使用pg_trgm的gin索引,或者拆列用多列索引疊加bit and或bit or進行優(yōu)化(只適合固定長度的端字符串,例如char(8)).
前后模糊查詢,使用索引只必要108毫秒.
時間主要花費在排他上面.
檢索了14794行,remove了14793行.大量的時間花費在無用功上,但是比全表掃還是好很多.
優(yōu)化:
使用gin索引后,必要考慮性能問題,因為info字段被打散成了多個char(3)的token,從而涉及到非常多的索引條目,如果有非常高并發(fā)的插入,最好把gin_pending_list_limit設大,來提高插入效率,降低實時合并索引帶來的RT升高.
使用了fastupdate后,會在每次vacuum表時,自動將pengding的信息合并到GIN索引中.
還有一點,查詢不會有合并的動作,對于沒有合并的GIN信息是使用遍歷的方式搜索的.
壓測高并發(fā)的性能:
修改配置,讓數(shù)據庫的autovacuum快速迭代合并gin.
創(chuàng)建一個測試函數(shù),用來產生隨機的測試數(shù)據.依照這個速度,一天能支持超過40億數(shù)據入庫.
接下來對比一下字符串分離的例子,這個例子適用于字符串長度固定,并且很小的場景,如果字符串長度不固定,這種辦法沒用.
適用splict的辦法,測試數(shù)據不盡人意,所以還是用pg_trgm比較靠譜.(省略一圖)
大數(shù)據量性能測試:
模擬分區(qū)表,每小時一個分區(qū),每小時數(shù)據量5000萬,一天12億,一個月360億.
生成插入SQL
性能指標, 范圍掃描, 落到單表5000萬的數(shù)據量內, 毫秒級返回(詳細看圖).
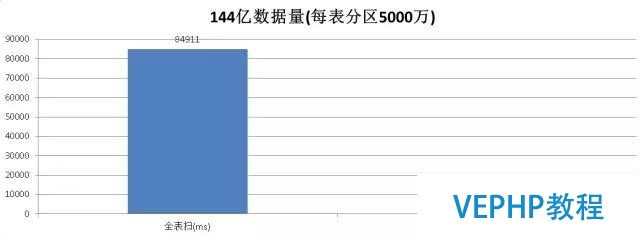
單表144億的正則和模糊查詢性能測試:
測試數(shù)據后續(xù)放出,分表后做到秒級是沒有問題的.信心從何而來呢?
因為瓶頸不在IO上,主要在數(shù)據的recheck, 把144億數(shù)據拆分成29個5億的表,并行執(zhí)行,秒出是有可能的.
來看一個單表5億的測試結果,秒出:
全表掃描必要,
性能對比圖表:
1000萬數(shù)據對比
5億數(shù)據對比
1000萬數(shù)據btree bit or|and與gin對比
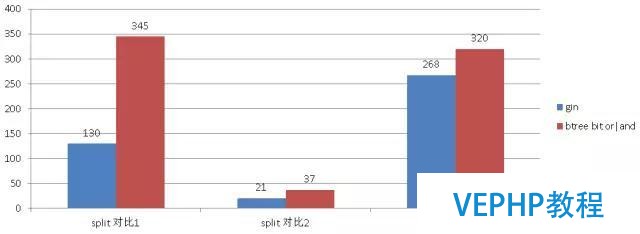
144億分區(qū)表對比
大數(shù)據量的優(yōu)化辦法,例如百億級別以上的數(shù)據量,如何能做到秒級的模糊查詢響應.
對于單機,可以使用分區(qū),同時使用并行查詢,充分使用CPU的功能.或者使用MPP, SHARDING架構,利用多機的資源.
原則,減少recheck,盡量掃描搜索到最終必要的結果(大量掃描,大量remove checked false row, 全表和索引都存在這種現(xiàn)象).
如果你能看到這行字,闡明是PG的真愛!云棲社區(qū)已經組建了 PG大牛群,2016學習PG技術,從社區(qū)開始,歡迎告訴我們你的需求!
歡迎參與《大數(shù)據最大難關之模糊檢索,PostgreSQL如何攻克!》討論,分享您的想法,維易PHP學院為您提供專業(yè)教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9209.html
同類教程排行
- 小白入門-新手學習-網絡基礎-ms17-
- 如何找對業(yè)務G點, 體驗酸爽?Postg
- 在Kubernetes部署可用的Post
- Oracle和PostgreSQL的最新
- 解讀數(shù)據庫《超體》PostgreSQL
- MySQL和PostgreSQL:國內外
- 針對PostgreSQL的最佳Java
- 為PostgreSQL討說法:淺析Ube
- PostgreSQL測試工具PGbenc
- go 語言操作數(shù)據庫 CRUD
- 白帽黑客教程2.5Metasploit中
- JIRA使用教程:連接數(shù)據庫-Postg
- 德歌:PostgreSQL獨孤九式搞定物
- 大數(shù)據最大難關之模糊檢索,Postgre
- 當物流調度遇見PostgreSQL-機器
