PostgreSQL的9.6黑科技綻放算法索引
《PostgreSQL的9.6黑科技綻放算法索引》要點(diǎn):
本文介紹了PostgreSQL的9.6黑科技綻放算法索引,希望對(duì)您有用。如果有疑問,可以聯(lián)系我們。
相關(guān)主題:PostgreSQL教程
PostgreSQL 確實(shí)是學(xué)術(shù)界和工業(yè)界的璀璨明珠,它總是喜歡將學(xué)術(shù)界的一些玩意工業(yè)化,這次的bloom又是一個(gè)代表.
在PG很多的地方都能看到學(xué)術(shù)的影子,好比pgbench支持產(chǎn)生泊松分布,高斯分布的隨機(jī)值.
bloom filter是一個(gè)有損過濾器,使用有限的比特位存儲(chǔ)一些唯一值集合所發(fā)生的bits.
通過這些bits可以滿足這樣的場(chǎng)景需求,給定一個(gè)值,判斷這個(gè)值是否屬于這個(gè)集合.
例如
create table test(c1 int);
insert into test select trunc(random()*100000) from generate_series(1,10000);
使用所有的 test.c1 值,通過bloom filter算法生成一個(gè)值val.
然后給定一個(gè)值例如 100,判斷100是否在test.c1中.
select * from test where c1=100;
通過bloom filter可以快速得到,不必要遍歷表來得到.
判斷辦法是使用100和val以及統(tǒng)一的bloom算法.
可能得到的成果是true or false.
true表現(xiàn)100在這里面,false表現(xiàn)100不在這里面.
必須注意,由于bloom filter是有損過濾器,并且真的不必定為真,但是假的必定為假.
PostgreSQL 9.6使用custom access methods接口定義了一個(gè)索引接口bloom,使用到它的特性:真的不必定為真,但是假的必定為假.
目前已實(shí)現(xiàn)的場(chǎng)景是,支持=查詢,但是這個(gè)=會(huì)包括一些假的值,所以需要recheck.反過來,它如果要支持<>也是很方便的,并且不需要recheck.
使用PostgreSQL 函數(shù)接口也能實(shí)現(xiàn)bloom過濾器.
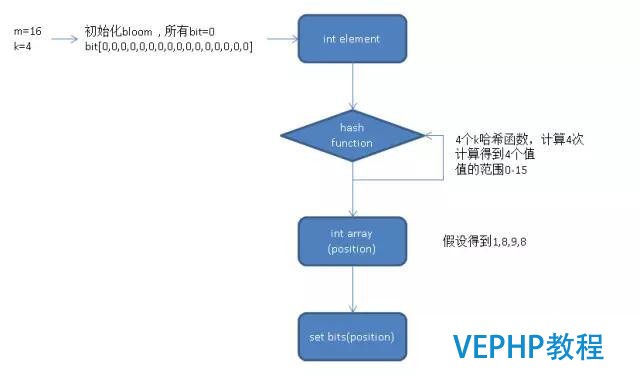
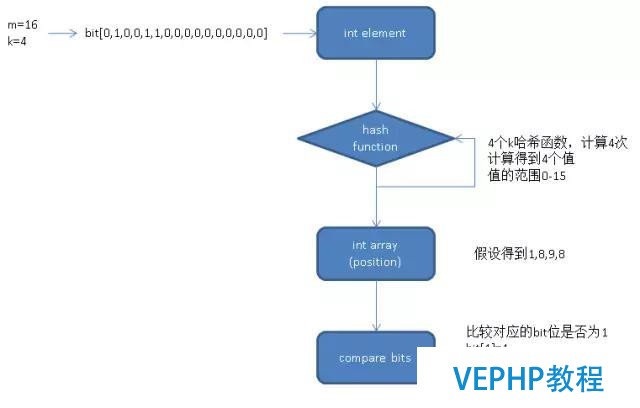
bloom必要m個(gè)bit位.
添加元素時(shí),必要k個(gè)hash函數(shù),通過每一個(gè)hash和傳入的值計(jì)算得到另一個(gè)值([0,m]).
得到的值用于設(shè)置對(duì)應(yīng)的bit位為1.
例子
創(chuàng)立一個(gè)類型,存儲(chǔ)bloom.
CREATE TYPE dumbloom AS (
m integer, -- bit 位數(shù)
k integer, -- hash 函數(shù)數(shù)量
-- Our bit array is actually an array of integers
bits integer[] -- bit
);
創(chuàng)立一個(gè)空的bloom ,設(shè)置false值異常設(shè)置為TRUE的概率p, 設(shè)置期望存儲(chǔ)多少個(gè)唯一值n .
CREATE FUNCTION dumbloom_empty (
-- 2% false probability
p float8 DEFAULT 0.02,
-- 100k expected uniques
n integer DEFAULT 100000
) RETURNS dumbloom AS
$$
DECLARE
m integer;
k integer;
i integer;
bits integer[];
BEGIN
-- Getting m and k from n and p is some math sorcery
-- See: https://en.wikipedia.org/wiki/Bloom_filter#Optimal_number_of_hash_functions
m := abs(ceil(n * ln(p) / (ln(2) ^ 2)))::integer;
k := round(ln(2) * m / n)::integer;
bits := NULL;
-- Initialize all bits to 0
FOR i in 1 .. ceil(m / 32.0) LOOP
bits := array_append(bits, 0);
END LOOP;
RETURN (m, k, bits)::dumbloom;
END;
$$
LANGUAGE 'plpgsql' IMMUTABLE;
創(chuàng)立一個(gè)指紋函數(shù),存儲(chǔ)使用K個(gè)哈希函數(shù)得到的值,存入數(shù)組.
CREATE FUNCTION dumbloom_fingerprint (
b dumbloom,
item text
) RETURNS integer[] AS
$$
DECLARE
h1 bigint;
h2 bigint;
i integer;
fingerprint integer[];
BEGIN
h1 := abs(hashtext(upper(item)));
-- If lower(item) and upper(item) are the same, h1 and h2 will be identical too,
-- let's add some random salt
h2 := abs(hashtext(lower(item) || 'yo dawg!'));
finger := NULL;
FOR i IN 1 .. b.k LOOP
-- This combinatorial approach works just as well as using k independent
-- hash functions, but is obviously much faster
-- See: http://www.eecs.harvard.edu/~kirsch/pubs/bbbf/esa06.pdf
fingerprint := array_append(fingerprint, ((h1 + i * h2) % b.m)::integer);
END LOOP;
RETURN fingerprint;
END;
$$
LANGUAGE 'plpgsql' IMMUTABLE;
添加元素的函數(shù)
同樣也是設(shè)置對(duì)應(yīng)的bit為1
CREATE FUNCTION dumbloom_add (
b dumbloom,
item text,
) RETURNS dumbloom AS
$$
DECLARE
i integer;
idx integer;
BEGIN
IF b IS NULL THEN
b := dumbloom_empty(); -- 生成空bloom
END IF;
FOREACH i IN ARRAY dumbloom_fingerprint(b, item) LOOP -- 設(shè)置k個(gè)哈希發(fā)生的值對(duì)應(yīng)的bit位為1
-- Postgres uses 1-indexing, hence the + 1 here
idx := i / 32 + 1;
b.bits[idx] := b.bits[idx] | (1 << (i % 32));
END LOOP;
RETURN b;
END;
$$
LANGUAGE 'plpgsql' IMMUTABLE;
是否包括某元素
CREATE FUNCTION dumbloom_contains (
b dumbloom,
item text
) RETURNS boolean AS
$$
DECLARE
i integer;
idx integer;
BEGIN
IF b IS NULL THEN
RETURN FALSE;
END IF;
FOREACH i IN ARRAY dumbloom_fingerprint(b, item) LOOP -- 計(jì)算k個(gè)哈希發(fā)生的值,判斷是否有非1的bit, 有則返回false,如果全部為1則返回true.
idx := i / 32 + 1;
IF NOT (b.bits[idx] & (1 << (i % 32)))::boolean THEN
RETURN FALSE;
END IF;
END LOOP;
RETURN TRUE;
END;
$$
LANGUAGE 'plpgsql' IMMUTABLE;
測(cè)試
CREATE TABLE t (
users dumbloom
);
INSERT INTO t VALUES (dumbloom_empty());
UPDATE t SET users = dumbloom_add(users, 'usmanm');
UPDATE t SET users = dumbloom_add(users, 'billyg');
UPDATE t SET users = dumbloom_add(users, 'pipeline');
-- This first three will return true
SELECT dumbloom_contains(users, 'usmanm') FROM t;
SELECT dumbloom_contains(users, 'billyg') FROM t;
SELECT dumbloom_contains(users, 'pipeline') FROM t;
-- This will return false because we never added 'unknown' to the Bloom filter
SELECT dumbloom_contains(users, 'unknown') FROM t;
以上例子來自pipelinedb文檔, 用C語言寫成聚合函數(shù),可以實(shí)現(xiàn)流式計(jì)算.
https://www.pipelinedb.com/blog/making-postgres-bloom
接下來是PostgreSQL 9.6的例子,9.6是將它做成了索引,而不是聚合.
(如果有朋友想使用pipelinedb的bloom聚合,可以看看PIPELINEDB的代碼,PORT過來)
postgres=# create table test(id int);
CREATE TABLE
postgres=# insert into test select trunc(100000000*(random())) from generate_series(1,100000000);
INSERT 0 100000000
postgres=# create index idx_test_id on test using bloom(id);
CREATE INDEX
postgres=# select * from test limit 10;
id
----------
16567697
17257165
78384532
96331329
62449166
3965065
80439767
54772860
34960167
30594730
(10 rows)
位圖掃
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from test where id=16567697;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.test (cost=946080.00..946082.03 rows=2 width=4) (actual time=524.545..561.168 rows=3 loops=1)
Output: id
Recheck Cond: (test.id = 16567697)
Rows Removed by Index Recheck: 30870
Heap Blocks: exact=29846
Buffers: shared hit=225925
-> Bitmap Index Scan on idx_test_id (cost=0.00..946080.00 rows=2 width=0) (actual time=517.448..517.448 rows=30873 loops=1)
Index Cond: (test.id = 16567697)
Buffers: shared hit=196079
Planning time: 0.084 ms
Execution time: 561.535 ms
(11 rows)
全表掃
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from test where id=16567697;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Seq Scan on public.test (cost=0.00..1692478.00 rows=2 width=4) (actual time=0.017..8270.536 rows=3 loops=1)
Output: id
Filter: (test.id = 16567697)
Rows Removed by Filter: 99999997
Buffers: shared hit=442478
Planning time: 0.077 ms
Execution time: 8270.564 ms
(7 rows)
多個(gè)字段測(cè)試,16個(gè)字段,任意測(cè)試組合,速度和recheck有關(guān), recheck越少越好.
不僅僅支持and還支持or, 只是OR的條件是bitmap的, 會(huì)慢一些.
postgres=# create table test1(c1 int, c2 int, c3 int, c4 int, c5 int, c6 int ,c7 int, c8 int, c9 int, c10 int, c11 int, c12 int, c13 int, c14 int, c15 int, c16 int);
CREATE TABLE
postgres=# insert into test1 select i,i+1,i-1,i+2,i-2,i+3,i-3,i+4,i-4,i+5,i-5,i+6,i-6,i+7,i-7,i+8 from (select trunc(100000000*(random())) i from generate_series(1,10000000)) t;
INSERT 0 10000000
postgres=# create index idx_test1_1 on test1 using bloom (c1,c2,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c15);
CREATE INDEX
postgres=# \dt+ test1
List of relations
Schema | Name | Type | Owner | Size | Description
--------+-------+-------+----------+--------+-------------
public | test1 | table | postgres | 888 MB |
(1 row)
postgres=# \di+ idx_test1_1
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+-------------+-------+----------+-------+--------+-------------
public | idx_test1_1 | index | postgres | test1 | 153 MB |
(1 row)
postgres=# select * from test1 limit 10;
c1 | c2 | c3 | c4 | c5 | c6 | c7 | c8 | c9 | c10 | c11 | c12 | c13 | c14 | c15 | c16
----------+----------+----------+----------+----------+----------+----------+----------+----------+----------+----------+----------+----------+----------+----------+----------
68747916 | 68747917 | 68747915 | 68747918 | 68747914 | 68747919 | 68747913 | 68747920 | 68747912 | 68747921 | 68747911 | 68747922 | 68747910 | 68747923 | 68747909 | 68747924
36630121 | 36630122 | 36630120 | 36630123 | 36630119 | 36630124 | 36630118 | 36630125 | 36630117 | 36630126 | 36630116 | 36630127 | 36630115 | 36630128 | 36630114 | 36630129
72139701 | 72139702 | 72139700 | 72139703 | 72139699 | 72139704 | 72139698 | 72139705 | 72139697 | 72139706 | 72139696 | 72139707 | 72139695 | 72139708 | 72139694 | 72139709
35950519 | 35950520 | 35950518 | 35950521 | 35950517 | 35950522 | 35950516 | 35950523 | 35950515 | 35950524 | 35950514 | 35950525 | 35950513 | 35950526 | 35950512 | 35950527
15285103 | 15285104 | 15285102 | 15285105 | 15285101 | 15285106 | 15285100 | 15285107 | 15285099 | 15285108 | 15285098 | 15285109 | 15285097 | 15285110 | 15285096 | 15285111
43537916 | 43537917 | 43537915 | 43537918 | 43537914 | 43537919 | 43537913 | 43537920 | 43537912 | 43537921 | 43537911 | 43537922 | 43537910 | 43537923 | 43537909 | 43537924
38702018 | 38702019 | 38702017 | 38702020 | 38702016 | 38702021 | 38702015 | 38702022 | 38702014 | 38702023 | 38702013 | 38702024 | 38702012 | 38702025 | 38702011 | 38702026
59069936 | 59069937 | 59069935 | 59069938 | 59069934 | 59069939 | 59069933 | 59069940 | 59069932 | 59069941 | 59069931 | 59069942 | 59069930 | 59069943 | 59069929 | 59069944
6608034 | 6608035 | 6608033 | 6608036 | 6608032 | 6608037 | 6608031 | 6608038 | 6608030 | 6608039 | 6608029 | 6608040 | 6608028 | 6608041 | 6608027 | 6608042
35486917 | 35486918 | 35486916 | 35486919 | 35486915 | 35486920 | 35486914 | 35486921 | 35486913 | 35486922 | 35486912 | 35486923 | 35486911 | 35486924 | 35486910 | 35486925
(10 rows)
任意字段組合查詢都能用上這個(gè)索引
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from test1 where c8=68747920 and c10=68747921 and c16=68747924 and c7=68747913 and c5=68747914;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.test1 (cost=169609.00..169610.02 rows=1 width=64) (actual time=101.724..102.317 rows=1 loops=1)
Output: c1, c2, c3, c4, c5, c6, c7, c8, c9, c10, c11, c12, c13, c14, c15, c16
Recheck Cond: ((test1.c5 = 68747914) AND (test1.c7 = 68747913) AND (test1.c8 = 68747920) AND (test1.c10 = 68747921))
Rows Removed by Index Recheck: 425
Filter: (test1.c16 = 68747924)
Heap Blocks: exact=425
Buffers: shared hit=20033
-> Bitmap Index Scan on idx_test1_1 (cost=0.00..169609.00 rows=1 width=0) (actual time=101.636..101.636 rows=426 loops=1)
Index Cond: ((test1.c5 = 68747914) AND (test1.c7 = 68747913) AND (test1.c8 = 68747920) AND (test1.c10 = 68747921))
Buffers: shared hit=19608
Planning time: 0.129 ms
Execution time: 102.364 ms
(12 rows)
postgres=# explain (analyze,verbose,timing,costs,buffers) select * from test1 where c8=68747920 and c10=68747921 and c16=68747924 and c7=68747913 and c5=68747914 and c12=68747922;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.test1 (cost=194609.00..194610.03 rows=1 width=64) (actual time=54.702..54.746 rows=1 loops=1)
Output: c1, c2, c3, c4, c5, c6, c7, c8, c9, c10, c11, c12, c13, c14, c15, c16
Recheck Cond: ((test1.c5 = 68747914) AND (test1.c7 = 68747913) AND (test1.c8 = 68747920) AND (test1.c10 = 68747921) AND (test1.c12 = 68747922))
Rows Removed by Index Recheck: 27
Filter: (test1.c16 = 68747924)
Heap Blocks: exact=28
Buffers: shared hit=19636
-> Bitmap Index Scan on idx_test1_1 (cost=0.00..194609.00 rows=1 width=0) (actual time=54.667..54.667 rows=28 loops=1)
Index Cond: ((test1.c5 = 68747914) AND (test1.c7 = 68747913) AND (test1.c8 = 68747920) AND (test1.c10 = 68747921) AND (test1.c12 = 68747922))
Buffers: shared hit=19608
Planning time: 0.141 ms
Execution time: 54.814 ms
(12 rows)
如果使用其他的索引辦法,任意條件組合查詢,需要為每一種組合創(chuàng)建一個(gè)索引來支持.
而使用bloom索引辦法,只需要?jiǎng)?chuàng)建一個(gè)索引就夠了.http://www.postgresql.org/docs/9.6/static/bloom.html
更多深度技術(shù)內(nèi)容,請(qǐng)存眷云棲社區(qū)微信公眾號(hào):yunqiinsight.
維易PHP培訓(xùn)學(xué)院每天發(fā)布《PostgreSQL的9.6黑科技綻放算法索引》等實(shí)戰(zhàn)技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養(yǎng)人才。
轉(zhuǎn)載請(qǐng)注明本頁網(wǎng)址:
http://www.snjht.com/jiaocheng/11568.html
同類教程排行
- 小白入門-新手學(xué)習(xí)-網(wǎng)絡(luò)基礎(chǔ)-ms17-
- 如何找對(duì)業(yè)務(wù)G點(diǎn), 體驗(yàn)酸爽?Postg
- 在Kubernetes部署可用的Post
- Oracle和PostgreSQL的最新
- 解讀數(shù)據(jù)庫《超體》PostgreSQL
- MySQL和PostgreSQL:國內(nèi)外
- 針對(duì)PostgreSQL的最佳Java
- 為PostgreSQL討說法:淺析Ube
- PostgreSQL測(cè)試工具PGbenc
- go 語言操作數(shù)據(jù)庫 CRUD
- 白帽黑客教程2.5Metasploit中
- JIRA使用教程:連接數(shù)據(jù)庫-Postg
- 德歌:PostgreSQL獨(dú)孤九式搞定物
- 大數(shù)據(jù)最大難關(guān)之模糊檢索,Postgre
- 當(dāng)物流調(diào)度遇見PostgreSQL-機(jī)器
