LINUX實操:深度學習利器:TensorFlow與NLP模型
《LINUX實操:深度學習利器:TensorFlow與NLP模型》要點:
本文介紹了LINUX實操:深度學習利器:TensorFlow與NLP模型,希望對您有用。如果有疑問,可以聯系我們。
前言
自然語言處理(簡稱NLP),是研究計算機處理人類語言的一門技術,NLP技術讓計算機可以基于一組技術和理論,分析、理解人類的溝通內容.傳統的自然語言處理辦法涉及到了很多語言學本身的知識,而深度學習,是表征學習(representation learning)的一種辦法,在機器翻譯、自動問答、文本分類、情感分析、信息抽取、序列標注、語法解析等領域都有廣泛的應用.
2013年末谷歌發布的word2vec工具,將一個詞表示為詞向量,將文字數字化,有效地應用于文天職析.2016年谷歌開源自動生成文本摘要模型及相關TensorFlow代碼.2016/2017年,谷歌發布/升級語言處理框架SyntaxNet,識別率提高25%,為40種語言帶來文天職割和詞態分析功能.2017年谷歌官方開源tf-seq2seq,一種通用編碼器/解碼器框架,實現自動翻譯.本文主要結合TensorFlow平臺,講解TensorFlow詞向量生成模型(Vector Representations of Words);使用RNN、LSTM模型進行語言預測;以及TensorFlow自動翻譯模型.
Word2Vec數學原理簡介
我們將自然語言交給機器學習來處理,但機器無法直接理解人類語言.那么首先要做的事情就是要將語言數學化,Hinton于1986年提出Distributed Representation辦法,通過訓練將語言中的每一個詞映射成一個固定長度的向量.所有這些向量構成詞向量空間,每個向量可視為空間中的一個點,這樣就可以根據詞之間的距離來判斷它們之間的相似性,并且可以把其應用擴展到句子、文檔及中文分詞.
Word2Vec中用到兩個模型,CBOW模型(Continuous Bag-of-Words model)和Skip-gram模型(Continuous Skip-gram Model).模型示例如下,是三層結構的神經網絡模型,包含輸入層,投影層和輸出層.
(點擊放年夜圖像)
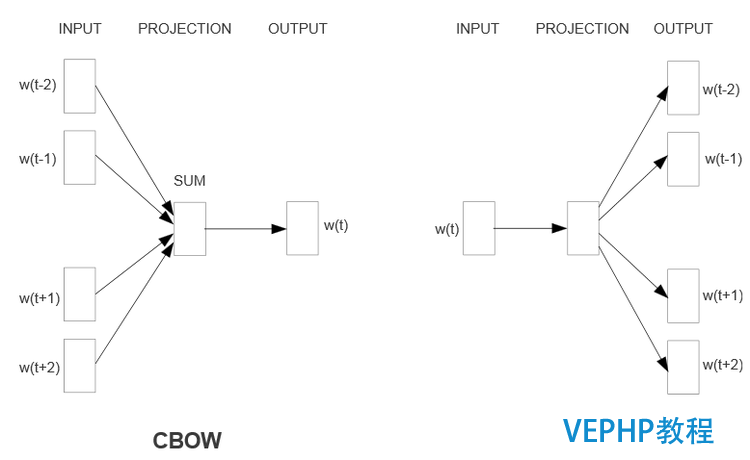

(點擊放年夜圖像)

其中score(wt, h),表現在的上下文環境下,預測結果是的概率得分.上述目標函數,可以轉換為極大化似然函數,如下所示:
(點擊放年夜圖像)
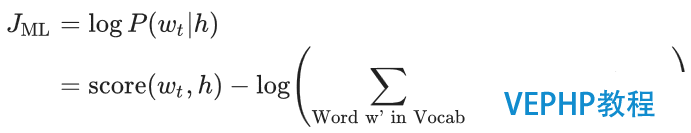
求解上述概率模型的計算成本是非常昂揚的,需要在神經網絡的每一次訓練過程中,計算每個詞在他的上下文環境中出現的概率得分,如下所示:
(點擊放年夜圖像)
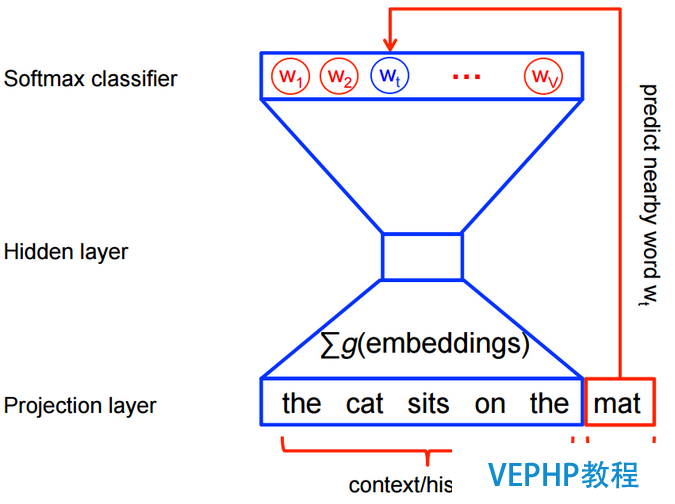
然而在使用word2vec辦法進行特性學習的時候,并不需要計算全概率模型.在CBOW模型和skip-gram模型中,使用了邏輯回歸(logistic regression)二分類辦法進行的預測.如下圖CBOW模型所示,為了提高模型的訓練速度和改善詞向量的質量,通常采用隨機負采樣(Negative Sampling)的辦法,噪音樣本w1,w2,w3,wk…為選中的負采樣.
(點擊放年夜圖像)
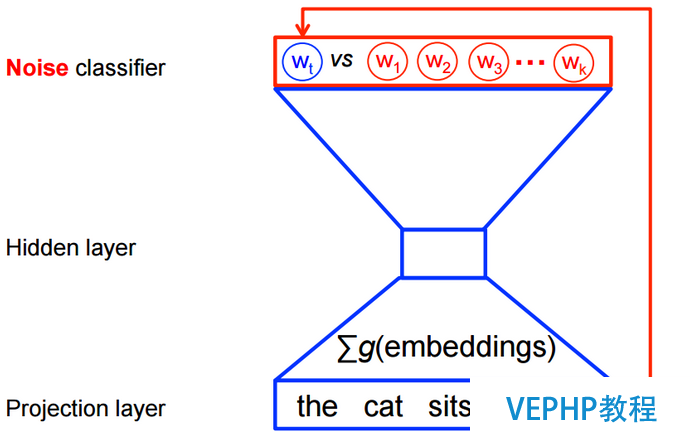
TensorFlow近義詞模型
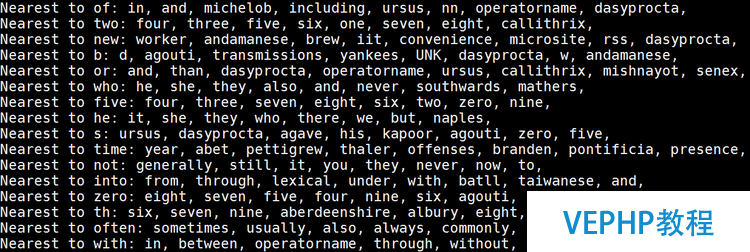
本章講解使用TensorFlow word2vec模型尋找近義詞,輸入數據是一大段英文文章,輸出是相應詞的近義詞.好比,通過學習文章可以得到和five意思相近的詞有: four, three, seven, eight, six, two, zero, nine.通過對大段英文文章的訓練,當神經網絡訓練到10萬次迭代,網絡Loss值減小到4.6左右的時候,學習得到的相關近似詞,如下圖所示:
(點擊放年夜圖像)
下面為TensorFlow word2vec API 使用闡明:
構建詞向量變量,vocabulary_size為字典大小,embedding_size為詞向量大小
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
定義負采樣中邏輯回歸的權重和偏置
nce_weights = tf.Variable(tf.truncated_normal ([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))) nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
定義訓練數據的接入
train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
定義根據訓練數據輸入,并尋找對應的詞向量
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
基于負采樣辦法計算Loss值
loss = tf.reduce_mean( tf.nn.nce_loss (weights=nce_weights, biases=nce_biases, labels=train_labels, inputs=embed, num_sampled=num_sampled, num_classes=vocabulary_size))
定義使用隨機梯度下降法執行優化操作,最小化loss值
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
通過TensorFlow Session Run的辦法執行模型訓練
for inputs, labels in generate_batch(...):
feed_dict = {train_inputs: inputs, train_labels: labels}
_, cur_loss = session.run([optimizer, loss], feed_dict=feed_dict)
TensorFlow語言預測模型
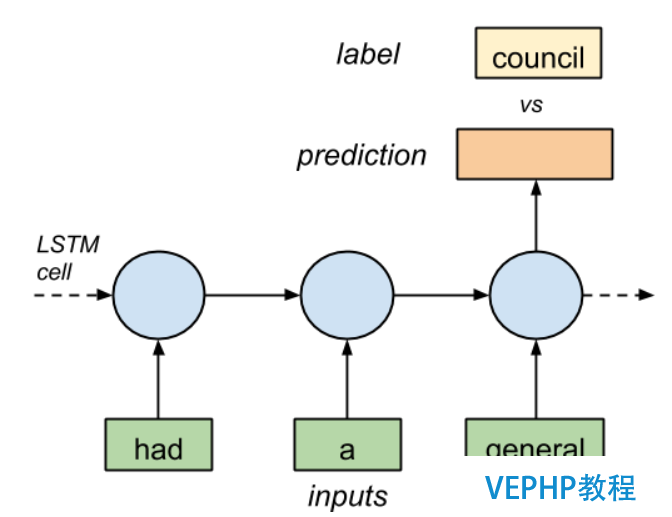
本章主要回顧RNN、LSTM技術原理,并基于RNN/LSTM技術訓練語言模型.也就是給定一個單詞序列,預測最有可能出現的下一個單詞.例如,給定[had, a, general] 3個單詞的LSTM輸入序列,預測下一個單詞是什么?如下圖所示:
(點擊放年夜圖像)
RNN技術原理
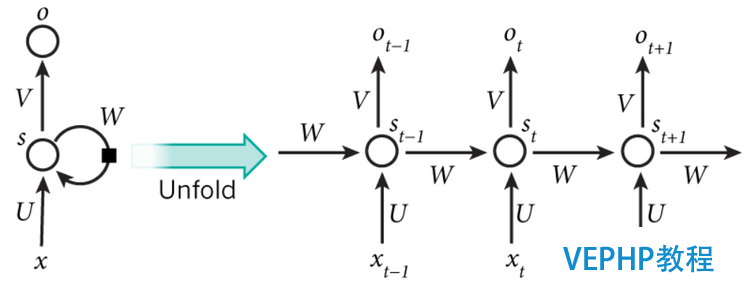
循環神經網絡(Recurrent Neural Network, RNN)是一類用于處理序列數據的神經網絡.和卷積神經網絡的區別在于,卷積網絡是適用于處理網格化數據(如圖像數據)的神經網絡,而循環神經網絡是適用于處理序列化數據的神經網絡.例如,你要預測句子的下一個單詞是什么,一般需要用到前面的單詞,因為一個句子中前后單詞并不是獨立的.RNN之所以稱為循環神經網路,即一個序列當前的輸出與前面的輸出也有關.具體的表現形式為網絡會對前面的信息進行記憶并應用于當前輸出的計算中,即暗藏層之間的節點不再無連接而是有連接的,并且暗藏層的輸入不僅包括輸入層的輸出還包括上一時刻暗藏層的輸出.如下圖所示:
(點擊放年夜圖像)

LSTM技術原理
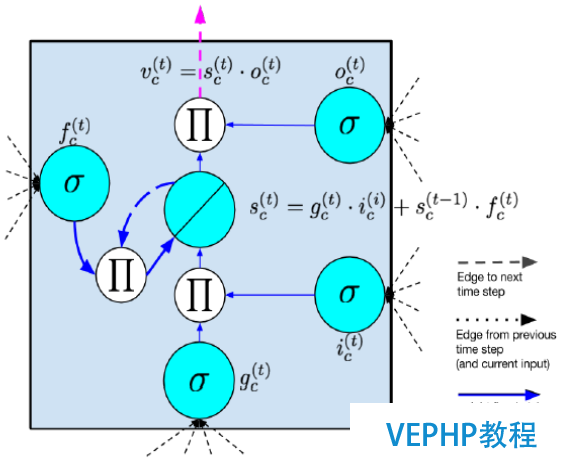
RNN有一問題,反向傳播時,梯度也會呈指數倍數的衰減,導致經過許多階段傳播后的梯度傾向于消失,不能處理長期依賴的問題.雖然RNN理論上可以處理任意長度的序列,但實習應用中,RNN很難處理長度超過10的序列.為了辦理RNN梯度消失的問題,提出了Long Short-Term Memory模塊,通過門的開關實現序列上的記憶功能,當誤差從輸出層反向傳播回來時,可以使用模塊的記憶元記下來.所以 LSTM 可以記住比較長時間內的信息.常見的LSTM模塊如下圖所示:
(點擊放年夜圖像)

(點擊放年夜圖像)
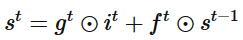
output gate類似于input gate同樣會發生一個0-1向量來控制Memory Cell到輸出層的輸出,如下公式所示:
(點擊放年夜圖像)
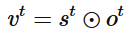
三個門協作使得 LSTM 存儲塊可以存取長期信息,比如說只要輸入門堅持關閉,記憶單元的信息就不會被后面時刻的輸入所覆蓋.
使用TensorFlow構建單詞預測模型
首先下載PTB的模型數據,該數據集大概包括10000個不同的單詞,并對不常用的單詞進行了標注.
首先必要對樣本數據集進行預處理,把每個單詞用整數標注,即構建詞典索引,如下所示:
讀取訓練數據
data = _read_words(filename) #依照單詞出現頻率,進行排序 counter = collections.Counter(data) count_pairs = sorted(counter.items(), key=lambda x: (-x1, x[0])) #構建詞典及詞典索引 words, _ = list(zip(*count_pairs)) word_to_id = dict(zip(words, range(len(words))))
接著讀取訓練數據文本,把單詞序列轉換為單詞索引序列,生成訓練數據,如下所示:
讀取訓練數據單詞,并轉換為單詞索引序列
data = _read_words(filename) data = [word_to_id[word] for word in data if word in word_to_id]
生成訓練數據的data和label,其中epoch_size為該epoch的訓練迭代次數,num_steps為LSTM的序列長度
i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue() x = tf.strided_slice(data, [0, i * num_steps], [batch_size, (i + 1) * num_steps]) x.set_shape([batch_size, num_steps]) y = tf.strided_slice(data, [0, i * num_steps + 1], [batch_size, (i + 1) * num_steps + 1]) y.set_shape([batch_size, num_steps])
構建LSTM Cell,其中size為暗藏神經元的數量
lstm_cell = tf.contrib.rnn.BasicLSTMCell(size, forget_bias=0.0, state_is_tuple=True)
如果為訓練模式,為保證訓練魯棒性,定義dropout操作
attn_cell = tf.contrib.rnn.DropoutWrapper(lstm_cell, output_keep_prob=config.keep_prob)
根據層數配置,定義多層RNN神經網絡
cell = tf.contrib.rnn.MultiRNNCell( [ attn_cell for _ in range(config.num_layers)], state_is_tuple=True)
根據詞典大小,定義詞向量
embedding = tf.get_variable("embedding",
[vocab_size, size], dtype=data_type())
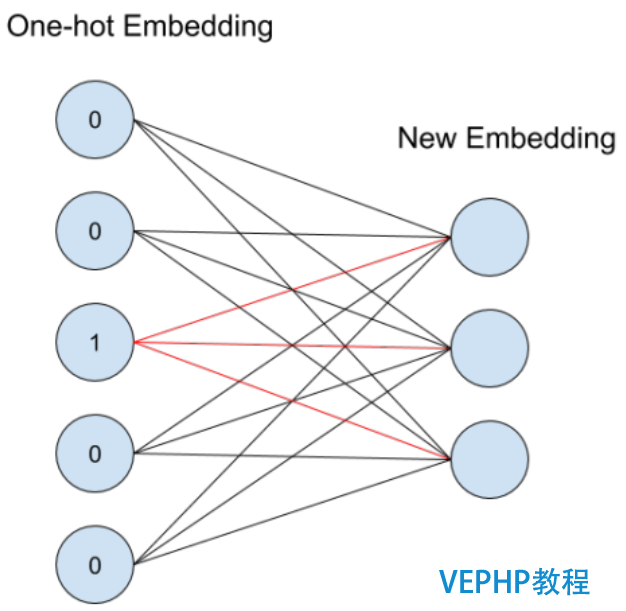
根據單詞索引,查找詞向量,如下圖所示.從單詞索引找到對應的One-hot encoding,然后紅色的weight就直接對應了輸出節點的值,也就是對應的embedding向量.
inputs = tf.nn.embedding_lookup(embedding, input_.input_data)
(點擊放大圖像)
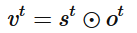
定義RNN網絡,此中state為LSTM Cell的狀態,cell_output為LSTM Cell的輸出
for time_step in range(num_steps): if time_step > 0: tf.get_variable_scope().reuse_variables() (cell_output, state) = cell(inputs[:, time_step, :], state) outputs.append(cell_output)
定義訓練的loss值就,如下公式所示.
(點擊放大圖像)
softmax_w = tf.get_variable("softmax_w", [size, vocab_size], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=data_type())
logits = tf.matmul(output, softmax_w) + softmax_b
Loss值
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [tf.reshape(input_.targets, [-1])], [tf.ones([batch_size * num_steps], dtype=data_type())])
定義梯度及優化操作
cost = tf.reduce_sum(loss) / batch_size tvars = tf.trainable_variables() grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), config.max_grad_norm) optimizer = tf.train.GradientDescentOptimizer(self._lr)
單詞困惑度eloss
perplexity = np.exp(costs / iters)
TensorFlow語言翻譯模型
本節主要講解使用TensorFlow實現RNN、LSTM的語言翻譯模型.基礎的sequence-to-sequence模型主要包括兩個RNN網絡,一個RNN網絡用于編碼Sequence的輸入,另一個RNN網絡用于產生Sequence的輸出.基礎架構如下圖所示
(點擊放年夜圖像)

上圖中的每個方框表現RNN中的一個Cell.在上圖的模型中,每個輸入會被編碼成固定長度的狀態向量,然后傳遞給解碼器.2014年,Bahdanau在論文“Neural Machine Translation by Jointly Learning to Align and Translate”中引入了Attention機制.Attention機制允許解碼器在每一步輸出時參與到原文的不同部分,讓模型根據輸入的句子以及已經產生的內容來影響翻譯結果.一個加入attention機制的多層LSTM sequence-to-sequence網絡結構如下圖所示:
(點擊放年夜圖像)
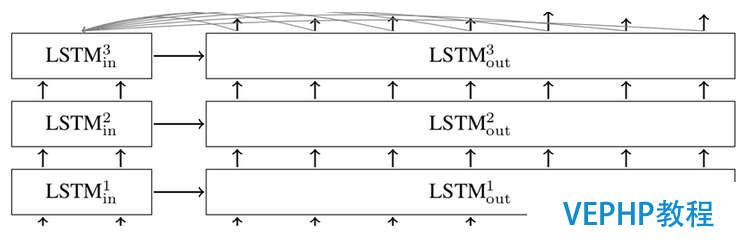
針對上述sequence-to-sequence模型,TensorFlow封裝成了可以直接調用的函數API,只必要幾百行的代碼就能實現一個初級的翻譯模型.tf.nn.seq2seq文件共實現了5個seq2seq函數:
-
basic_rnn_seq2seq:輸入和輸出都是embedding的形式;encoder和decoder用雷同的RNN cell,但不共享權值參數;
-
tied_rnn_seq2seq:同basic_rnn_seq2seq,但encoder和decoder共享權值參數;
-
embedding_rnn_seq2seq:同basic_rnn_seq2seq,但輸入和輸出改為id的形式,函數會在內部創立分別用于encoder和decoder的embedding矩陣;
-
embedding_tied_rnn_seq2seq:同tied_rnn_seq2seq,但輸入和輸出改為id形式,函數會在內部創立分別用于encoder和decoder的embedding矩陣;
-
embedding_attention_seq2seq:同embedding_rnn_seq2seq,但多了attention機制;
embedding_rnn_seq2seq函數接口使用闡明如下:
-
encoder_inputs:encoder的輸入
-
decoder_inputs:decoder的輸入
-
cell:RNN_Cell的實例
-
num_encoder_symbols,num_decoder_symbols:分別是編碼和解碼的年夜小
-
embedding_size:詞向量的維度
-
output_projection:decoder的output向量投影到詞表空間時,用到的投影矩陣和偏置項
-
feed_previous:若為True, 只有第一個decoder的輸入符號有用,所有的decoder輸入都依附于上一步的輸出;
outputs, states = embedding_rnn_seq2seq( encoder_inputs, decoder_inputs, cell, num_encoder_symbols, num_decoder_symbols, embedding_size, output_projection=None, feed_previous=False)
TensorFlow官方提供了英語到法語的翻譯示例,采用的是statmt網站提供的語料數據,主要包括:giga-fren.release2.fixed.en(英文語料,3.6G)和giga-fren.release2.fixed.fr(法文語料,4.3G).該示例的代碼結構如下所示:
- seq2seq_model.py:seq2seq的TensorFlow模型
采納了embedding_attention_seq2seq用于創建seq2seq模型.
- data_utils.py:對語料數據進行數據預處理,根據語料數據生成詞典庫;并基于詞典庫把要翻譯的語句轉換成用用詞ID表現的訓練序列.如下圖所示:
(點擊放大圖像)

- translate.py:主函數入口,執行翻譯模型的訓練
執行模型訓練
python translate.py --data_dir [your_data_directory] --train_dir [checkpoints_directory] --en_vocab_size=40000 --fr_vocab_size=40000
總結
隨著TensorFlow新版本的賡續發布以及新模型的賡續增加,TensorFlow已成為主流的深度學習平臺.本文主要介紹了TensorFlow在自然語言處理領域的相關模型和應用.首先介紹了Word2Vec數學原理,以及如何使用TensorFlow學習詞向量;接著回顧了RNN、LSTM的技術原理,講解了TensorFlow的語言預測模型;最后實例分析了TensorFlow sequence-to-sequence的機器翻譯 API及官方示例.
參考文獻
- http://www.tensorflow.org
- 深度學習利器:分布式TensorFlow及實例闡發
- 深度學習利器:TensorFlow使用實戰
- 深度學習利器:TensorFlow系統架構與高性能程序設計
- 深度學習利器:TensorFlow與深度卷積神經網絡
作者簡介
武維:IBM Spectrum Computing 研發工程師,博士,系統架構師,主要從事大數據,深度學習,云計算等領域的研發工作.
本文永遠更新鏈接地址:
學習更多LINUX教程,請查看站內專欄,如果有LINUX疑問,可以加QQ交流《LINUX實操:深度學習利器:TensorFlow與NLP模型》。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9051.html
同類教程排行
- LINUX入門:CentOS 7卡在開機
- LINUX實戰:Ubuntu下muduo
- LINUX教程:Ubuntu 16.04
- LINUX教程:GitBook 使用入門
- LINUX實操:Ubuntu 16.04
- LINUX教學:Shell、Xterm、
- LINUX教程:Linux下開源的DDR
- LINUX實戰:TensorFlowSh
- LINUX教學:Debian 9 'St
- LINUX實戰:Ubuntu下使用Vis
- LINUX教學:Linux 下 Free
- LINUX教學:openslide-py
- LINUX實操:Kali Linux安裝
- LINUX教學:通過PuTTY進行端口映
- LINUX教程:Ubuntu 16.04
