LINUX實戰:UUID簡史
《LINUX實戰:UUID簡史》要點:
本文介紹了LINUX實戰:UUID簡史,希望對您有用。如果有疑問,可以聯系我們。
今天,我們發布了KSUID,一款用于生成唯一ID的Golang庫.該產品借鑒了目前廣泛使用的UUID標準一些核心理念,增加了基于時間的排序功能,可提供更友好的表現格式.在針對該產品進行調研的過程中,我們發現UUID的背后其實還有一個極富吸引力的故事,想要借助本文分享給大家.
自從兩臺甚至更多計算機可以通過網絡交換信息那天起,它們就需要一種能夠體現唯一性的“身份”.
第一個符合目前我們所知這種定義的“網絡”,是1870年代建立的全球首個電話交換網.在此之前,電話線路完全是一種點對點鏈路.盡管在當時這有著劃時代的意義,但這種網絡很昂貴,不靈活,也不可靠.甚至導致各大主要城市街頭形成了電線交織而成的“蜘蛛網”.
(點擊放大圖像)

當時哪怕電報也只能被政府和企業用于傳遞重要信息,電話就更是一種奢侈品了.考慮到電報的速度,專門架設昂貴的電線來更快速的“聊天”,似乎是一種很夸張的做法.不過隨后的一個重要創新:可創建交換電路的電話總機,讓電話變得更實用.此時電話才真正深入尋常百姓家.而電話總機也為電話網絡引入了首個具備唯一性的身份:電話號碼.
幾十年后,計算機網絡出現了.突然之間,身份的粒度有了數量級的提升.
當時,通過電話線路傳輸數據是一種短暫執行的操作,網絡只起到管道作用.現在,按需存儲和獲取數據的做法已變得極為普遍,整個世界已淹沒在數量爆發式增長的數據海洋中.在這些新能力影響下,網絡身份對應的主體已由傳統計算機實體變為組成數據的邏輯片段.
這樣的網絡需要通過某種具備唯一性的方式對數據片段尋址,電話網絡時代那種需要集中控制的系統已無法滿足需求.從數學的角度來看,這種問題是不可避免的,畢竟網絡存儲和檢索數據的能力以及數據的規模都在線性增長著.這樣的規模在一定程度上還產生了些許混亂:各種故障和暫存的計算機也已經從牦牛剪毛(譯注:牦牛剪毛,Yak shaving,是指為了間接實現一個目標而做的次要,并且與目標無關的工作)問題變得稀疏平常.數據不再只安于一地,而是會在整個網絡內自由移動.
計算領域迎來網絡化時代
很快到了1980年代,當時使用計算機共享數據實際上意味著要共享整個實體計算機.各大機構會使用微型計算機,以及連接了幾百上千臺啞終端的高性能大型機交換信息.
換句話說,當時數據本身與計算工作是共存的.雖然個人計算機提供了革命性的計算能力,但由于缺乏網絡功能,當時的個人計算機實際上只是一種奢侈的計算器.
成立于1980年的Apollo Computer,曾是步入當時新興工作站市場的首批公司之一.工作站才是真正意義上的第一種可聯網計算機,使用“工作站”這個詞描述這種計算機聽起來似乎有點滑稽,但別忘了,目前我們習以為常的各種網絡技術在當時還處于萌芽狀態.與大型機相比,數據和計算功能分散在很多相互連接的計算機中,而此時“分布式計算”這個詞也開始進入主流視野.
(點擊放大圖像)

與同時代的Sun Microsystems類似,Apollo的產品也是全棧的.一切都需要從零開始來開發,因為當時軟硬件在設計方面與他們構想的用例還有些差異.網絡的異步性以及這些任務的本質需求需要功能更豐富的計算機.多任務、平安控制、網絡,以及海量存儲等特征對當時的個人計算機來說要么過于昂貴,要么不夠現實.不過在工作站的未來構想中,這些特征已成為了“標配”.
盡管工作站市場上的各類技術經歷了讓人印象深刻的爆發式增長,但當時的所有供應商都面臨一個共同障礙:缺乏精通網絡技術的開發者.為了給自己價格昂貴的工作站塑造一個切實可行的商業案例,他們需要一種編程環境.借此,開發者才能通過某種方式,輕松構建能幫助各家產品將網絡功能完全發揮出來的應用程序.
對此,Apollo提出了網絡計算系統(NCS)的概念.NCS借鑒了面向對象編程的某些思路,圍繞遠程過程調用(RPC)的概念構建.雖然這種方式目前已面臨淘汰,但在當時至少滿足了Apollo的需求:任何開發者都可以了解如何調用某一函數,并以面向對象的編程范式為主要特色.
在Network World雜志1989年發布的一篇有關RPC的文章中,Burlington Coat Factory的一位MIS總監提出了自己的觀點:“訓練有素的程序員只需要一天左右時間就能學會使用RPC構建分布式應用程序”.同樣是那一年,Apollo作價4.76億美元賣給了HP,考慮到通貨膨脹,這一價格約等于今天的10億美元.
NCS術語中所謂的“物件”(對象、接口、操作[方法]等)也就是“實體”,必須能在網絡化的環境中通過具備唯一性的身份進行尋址.在標準的馮·諾伊曼體系結構中這一點并不重要:內存或大容量存儲設備的地址即可承擔這一用途.但在分布式計算模型中,由于多臺計算機可以分別獨立運作,這就很重要了.考慮到具體用例的實際規模,跨越網絡進行協調的方式并不現實,因為速度太慢,并且非常容易出錯.
NCS引入了UID(Universal IDentifier,全局標識符)的概念,并使用UID作為實體身份主要且唯一的標識符.UID是一種64位數值,結合單調(Monotonic)時鐘與工作站硬件嵌入的永久性唯一主機ID生成.通過這種方式,每臺主機每秒鐘可以完成數千次標識符生成操作,并在所有時間內確保全局唯一性,在規模方面也不存在瓶頸.這種機制唯一需要進行的協調工作可以在Apollo的工廠中進行,只需為每臺計算機嵌入一個永久ID即可.
第一個UUID
當Apollo開始通過網絡計算架構(NCA)踐行自己標準化的NCS構想時,很快發現,只使用現有的UID還不夠.Apollo希望所有工作站供應商通過NCA實現標準化,都在自己的工作站中嵌入主機ID,而具體位長可由供應商自行決定.
Apollo使用了20位長度,很適合計算機總數約為100萬臺的情況.以今天的視角來看,這樣的規模實在是很可笑,但在當時,Apollo需要在整個體量小很多的市場中賣出總價值超過100億美元的硬件才能達成這樣的規模.
NCA引入了UUID的概念,UUID源自UID的設計基礎,但將地址空間擴展到128位,這樣就可以有更多供應商分別打造自己的產品.UUID就此誕生.這個概念是如此有用,以至于在NCA成為歷史,RPC逐漸退流行的今天,UUID依然維持著活力,并最終被ISO、IETF,以及ITU確定為標準.
(點擊放大圖像)
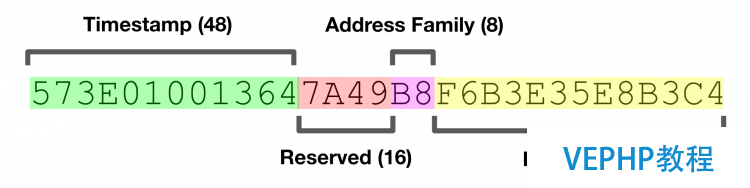
對UUID有所了解的讀者會發現,這個概念與目前廣泛使用的第4版UUID有些許差異.NCA UUID包含一個48位時間戳,16位預留位,一個8位網絡地址族指示符和一個56位主機ID.這些結合在一起,其實與目前成為IETF標準的第1版UUID概念極為類似.
這些歷史事件不禁讓我好奇UUID的具體實現,并有幸在網上找到了一些Apollo NCS源代碼.如果你和我有著類似想法,不妨一起讀讀這些幾十年前寫的源代碼.我在這些代碼中發現的第一個奇怪之處是:這種標識也像變量和函數名那樣使用了美元符號($).
void uuid_$gen(uuid)
uuid_$t *uuid;
{
#ifdef apollo
std_$call void uid_$gen();
struct uid_t uid;
uid_$gen(uid);
uuid_$from_uid((uid_$t *) &uid, uuid);
原來NCS使用了一種名為“Domain C”的語言,這種語言由Apollo開發,包含在他們的“Domain/OS”操作系統中.在Bitsavers的幫助下,我找到了一份1988年發布的PDF版參考手冊.Domain C通過多種方式對ANSI C進行了擴展,最重要的是可支持在任何標識符的首個字符之后使用$.
在當時,美元符號主要被一些不怎么時髦的編程語言充當一種變量語法,經濟領域用它代表貨幣單位,或者用它形容那些自我膨脹的音樂家.為了理解這個符號在現已滅絕的Apollo Computer世界中的實際用途,還需要繼續深入挖掘更多代碼和文檔.
在進一步展示我的發現之前,首先要說說自己發現的一個虎頭蛇尾的結論:雖然并沒有明說,但這似乎只是一種寫代碼的習慣._$之前的任何內容實際上代表某個特定模塊,_$t代表“默認類型”,例如上文出現的uuid_$t.此外借此也可以很方便地判斷哪些標識符隸屬于符合Apollo編程風格的庫.僅僅為了適應某種具體的編碼風格就對C進行擴展,Apollo的這種做法還是讓人感覺有些困惑的.
但我不同意.
NCA UUID最終成為了標準化后第1版UUID的基礎.需要重申一點:其中包含了一個高精度時間戳以及基于硬件的唯一主機標識符.毫無疑問,無法僅通過系統時鐘以可靠的方式生成具備唯一性的序列號,因為時鐘有可能不準確,甚至可能導致生成重復的時間戳.為此Apollo使用了一個全局文件(位于/tmp/last_uuid)對不同進程進行協調.
/* * C H E C K _ U U I D * * On a system wide basis, check to see if the passed UUID is the * same or older than the previously generated one. If it is, make sure * it becomes a little newer. Write the UUID back to the "last UUID" * storage in any case. In the case of systems using a file as * the storage, fall back to "per process" checking in the event of * the inability to safely access the storage. */
該文件可被任何用戶全局寫入,雖然并非特別平安,但Apollo向最終用戶銷售的工作站有些也被用在某些高可信網絡中,因此也可以將其理解為一種合理的決策.這種技術在UUID的IETF規范中也得到了進一步完善:
The following algorithm is simple, correct, and inefficient:
o Obtain a system-wide global lock
o From a system-wide shared stable store (e.g., a file), read the
UUID generator state: the values of the timestamp, clock sequence,
and node ID used to generate the last UUID.
o Get the current time as a 60-bit count of 100-nanosecond intervals
since 00:00:00.00, 15 October 1582.
o Get the current node ID.
o If the state was unavailable (e.g., non-existent or corrupted), or
the saved node ID is different than the current node ID, generate
a random clock sequence value.
o If the state was available, but the saved timestamp is later than
the current timestamp, increment the clock sequence value.
o Save the state (current timestamp, clock sequence, and node ID)
back to the stable store.
o Release the global lock.
o Format a UUID from the current timestamp, clock sequence, and node
ID values according to the steps in Section 4.2.2.
出乎意料的是,我找到的有關DCE的一個實現,具體源代碼竟然來自Apple.Apple似乎主要使用這種技術與微軟系統,如Active Directory和Windows文件服務器通信.這個實現包含開源軟件基金會的版權,并將實際的功能隱藏在一個名為UUID_NONVOLATILE_CLOCK的預處理器標記之后.
#ifdef UUID_NONVOLATILE_CLOCK
*clkseq = uuid__read_clock(); /* read nonvolatile clock */
if (*clkseq == 0) /* still not init'd ??? */
{
*clkseq = true_random(); /* yes, set random */
}
#else
/*
* with a volatile clock, we always init to a random number
*/
*clkseq = true_random();
#endif
我在網上沒找到任何可用于為DCE RPC的UUID生成過程實現非易失時鐘的代碼.然而大部分Linux發行版的程序包中提供的libuuid確實包含了一個可供使用的非易失UUID時鐘實現.與NCS類似,它會使用文件實現單調性(Monotonicity),但會將該文件放在更合理的/var/lib/libuuid/clock.txt中.雖然該技術會試圖通過略微更全面一些的方式來管理權限,但依然面臨相同的平安問題.
NCS和libuuid實現都需要針對狀態文件獲得所需的鎖,但這種做法很容易造成各種討厭的問題.
while (flock(state_fd, LOCK_EX) < 0) {
if ((errno == EAGAIN) || (errno == EINTR))
continue;
libuuid實際上是一種守護進程,但令人費解地使用了uuidd這樣的名字,目的主要是為了提供一定程度的平安性.uuidd可以強有力地保證一切都符合自己的規則.通過將其與假定唯一的以太網MAC地址配合使用,即可在分布式系統內提供相當強的擔保.
然而在實踐中依然有很多問題需要考慮.基于文件的同步會因為各種問題導致同步失敗,基于守護進程的解決方案略好一些,但似乎從未得以普遍運用.而直接使用拆箱即用的系統,不進行任何額外的配置,這樣的做法就更為罕見了.
另外MAC地址也并非真正全局唯一的,因為用戶可以修改.因此UUID包含MAC地址,這種做法也可能威脅到隱私和安全.考慮到不透明這一本質,開發者開始趨向于不認為UUID可以包含用于識別具體機器的信息.九十年代末期影響大量Windows計算機的Melissa病毒的創作者,就是因為從病毒代碼中發現的UUID中包含了MAC地址而被確定身份的.隨著不可信賴的互聯網逐漸成為處于安排地位的網絡平臺,基于信任關系生成UUID的做法已經顯得落伍.所有這些顧慮最終導致人們放棄考慮在UUID中使用硬件標識符.
/*
* This is the generic front-end to uuid_generate_random and
* uuid_generate_time. It uses uuid_generate_random only if
* /dev/urandom is available, since otherwise we won't have
* high-quality randomness.
*/
void uuid_generate(uuid_t out)
{
if (have_random_source())
uuid_generate_random(out);
else
uuid_generate_time(out);
}
實際上,libuuid的默認路徑會避免在能夠通過/dev/(u?)random提供偽隨機數生成塊設備(Block device)的任何系統上使用基于時間的UUID,而自從1990年代起各大主流UNIX變體就已支持這種做法了.這也直接推動了第4版UUID的形成,該版本只包含隨機數據,共122位.簡化后的實現過程使得該技術也開始得以廣泛運用.
當兩個世界碰撞之后
當我首次遇到這些隨機的第4版UUID時,曾擔心過因為碰撞可能產生的威脅.雖然UUID的使用場景不應該由于碰撞造成平安威脅,但作為開發者,我希望能夠確信自己的系統不會在這方面遇到問題.糟糕的是,UUID的生成依然需要依賴一定程度的“信任”.
防碰撞方面最重要的一點在于熵的來源.請考慮這兩種常見情況:在可信賴的云環境中部署了一個現代化版本的Linux,以及一個不可信賴的移動設備.在云端的Linux方面,我們可以通過/dev/urandom獲得一個從密碼學角度來說較為平安的偽隨機數生成器(PRNG),這就是所謂的獲得“密碼學認可”且無阻塞的“熵的來源”.這種方式可將諸如硬件中斷生成的“噪音”以及I/O活動源數據等不同來源與密碼學函數結合在一起.
更多LINUX教程,盡在維易PHP學院專欄。歡迎交流《LINUX實戰:UUID簡史》!
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9050.html
同類教程排行
- LINUX入門:CentOS 7卡在開機
- LINUX實戰:Ubuntu下muduo
- LINUX教程:Ubuntu 16.04
- LINUX教程:GitBook 使用入門
- LINUX實操:Ubuntu 16.04
- LINUX教學:Shell、Xterm、
- LINUX教程:Linux下開源的DDR
- LINUX實戰:TensorFlowSh
- LINUX教學:Debian 9 'St
- LINUX實戰:Ubuntu下使用Vis
- LINUX教學:Linux 下 Free
- LINUX教學:openslide-py
- LINUX實操:Kali Linux安裝
- LINUX教學:通過PuTTY進行端口映
- LINUX教程:Ubuntu 16.04
