Apache Spark的Lambda架構示例應用
《Apache Spark的Lambda架構示例應用》要點:
本文介紹了Apache Spark的Lambda架構示例應用,希望對您有用。如果有疑問,可以聯系我們。
【IT168 案例】目前,市場上很多玩家都已經成功構建了MapReduce工作流程,每天可以處理TB級的歷史數據,但是在MapReduce上跑數據分析真的太慢了.所以我們給大家介紹利用批處理和流處理方法的Lambda架構,本文中將利用Apache Spark(Core,SQL,Streaming),Apache Parquet,Twitter Stream等實時流數據快速拜訪歷史數據.
Apache Hadoop簡史
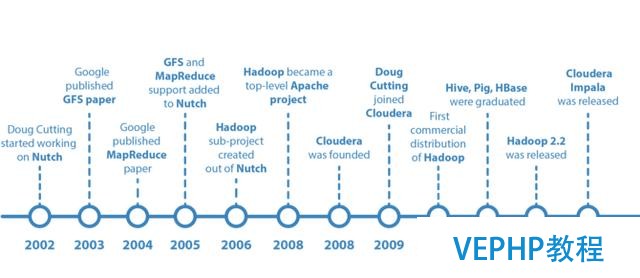
Apache Hadoop由 Apache Software Foundation 公司于 2005 年秋天作為Lucene的子項目Nutch的一部門正式引入.它受到最先由 Google Lab 開發的 Map/Reduce 和 Google File System(GFS) 的啟發.它成為一個獨立項目的時間已有10年.
目前已經有很多客戶實施了基于Hadoop的M / R管道,并勝利運行到現在:
Oozie的工作流每日運行處理150TB以上的數據并生成分析申報
Bash的工作流每日運行處理8TB以上的數據并生成分析申報
2016年來了!
2016年商業現實發生了變化,越快做出決策往往價值就會越大.另外,技術自己也在發展,Kafka,Storm,Trident,Samza,Spark,Flink,Parquet,Avro,云提供商等都成為了工程師們的流行語.
因此,現代基于Hadoop的M / R管道可能會是下圖所示的這樣:
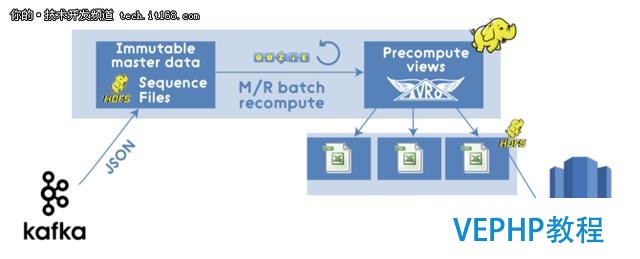
圖上的M/R通道看起來不錯,但其實它本色上還是一個傳統的批處理,有著傳統批處理的缺點,當新的數據源源不斷的進入系統中時,還是需要大量的時間來處理.
Lambda 架構
針對上面的問題,Nathan Marz提出了一個通用、可擴展和容錯性強的數據處理架構即Lambda架構,它是通過利用批處理和流處理辦法來處理大量數據的.Nathan Marz的書對從源碼的角度對Lambda架構進行了詳盡的介紹.
層布局
這是Lambda架構自上而下的層布局:
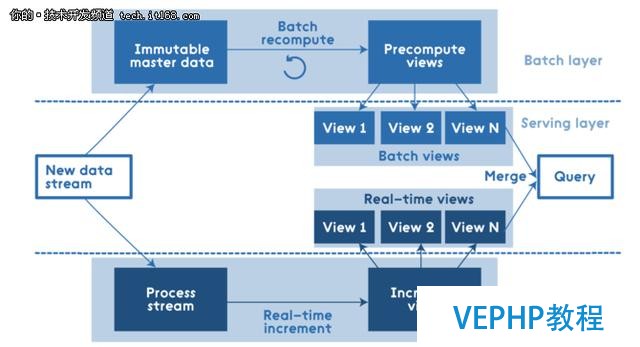
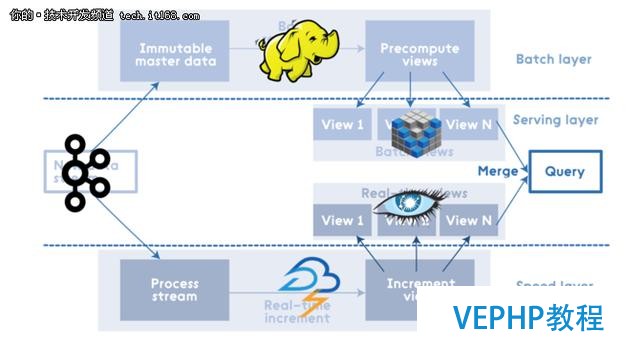
所有數據進入系統后都分派到批處理層和速度層進行處理.批處理層管理主數據集(一個不可變的,只可增加的原始數據集),并預先計算批處理視圖. 服務層對批視圖進行索引,以便可以進行低延遲的臨時查詢. 速度層僅處理最近的數據.所有的查詢結果都必需合并批處理視圖和實時視圖的查詢結果.
要點
許多工程師認為Lambda架構就只包括層結構和定義數據流程,但是Nathan Marz的書中為我們介紹了其它幾個比較重要的點:
分布式思想
避免增量布局
數據的不變性
創建重新計算算法
數據的相關性
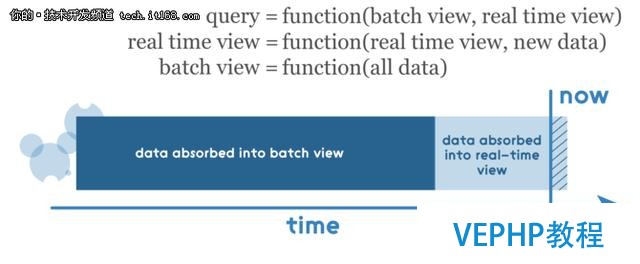
如前所述,任何查詢結果都必需通過合并來自批處理視圖和實時視圖的結果,因此這些視圖必需是可合并的.在這里要注意的一點是,實時視圖是前一個實時視圖和新數據增量的函數,因此這里使用增量算法,批處理視圖是所有數據的函數,因此應該使用重新計算算法.
權衡
世間萬物都是在不斷妥協和權衡中發展的,Lambda結構也不例外.通常,我們需要辦理幾個主要的權衡:
完全重新計算 vs.部門重新計算
在有些情況下,可以使用Bloom過濾器來避免完全重新計算
重計算算法 vs. 增量算法
增量算法其實很具吸引力,但是有時根據指南,我們必需使用重計算算法,即便它很難得到相同的結果
加法算法 vs. 近似算法
雖然Lambda架構能夠與加法算法很好地協同工作,但是在有些情況下更適合使用近似算法,例如使用HyperLogLog處置count-distinct問題.
實現
實現Lambda架構的辦法有很多,因為每個層的底層解決方案是獨立的.每個層需要底層實現的特定功能,有助于做出更好的選擇并避免過度決策:
批量層:一次寫入,批量讀取多次
服務層:支持隨機讀取但不支持隨機寫入; 批量計算和批量寫入
速度層:隨機讀寫; 增量計算
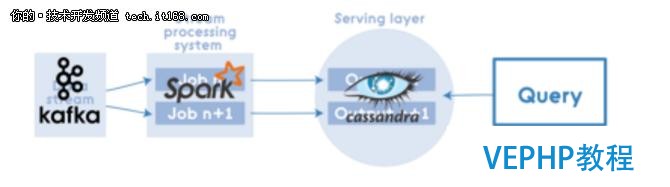
例如,其中一個實現(使用Kafka,Apache Hadoop,Voldemort,Twitter Storm,Cassandra)可能如下所示:
Apache Spark
Apache Spark被視為在所有Lambda架構層上進行處理的集成辦理方案. 其中Spark Core包含了高級API和支持常規執行圖的優化引擎,SparkSQL用于SQL和結構化數據處理,Spark Streaming支持實時數據流的可擴展,高吞吐量,容錯流處理. 當然,使用Spark進行批處理的價格可能比較高,而且也不是所有的場景和數據都適合.但是,總體來說Apache Spark是對Lambda架構的合理實現.
示例應用
我們創建一個示例應用法式來演示Lambda架構.這個示例的主要目的統計從某個時刻到現在此刻的#morningatlohika tweets哈希標簽.
批處置視圖
為了簡單起見,假設我們的主數據集包括自時間開始以來的所有tweets. 此外,我們實現了一個批處理,創建了我們的業務目標所需的批處理視圖,因此我們有一個預計算的批處理視圖,其中包括與#morningatlohika一起使用的所有主題標記的統計信息:

因為數字便利記憶,所以我使用對應標簽的英文單詞的字母數目作為編號.
實時視圖
當應用法式啟動并運行時,有人發出了如下的tweet:

在這種情況下,正確的實時視圖應包括以下標簽及其統計信息(在我們的示例中為1,因為相應的hash標簽只使用了一次):

查詢
當終端用戶查詢hash標簽的統計結果時,我們只必要將批量視圖與實時視圖合并起來. 所以輸出應該如下所示:

場景
示例場景的簡化步調如下:
1.通過Apache Spark創建批處置視圖(.parquet)
2.在Apache Spark中緩存批處置視圖
3.流應用法式連接到Twitter
4.實時監控#morningatlohika tweets
5.構建增量實時視圖
6.查詢,即合并批處置視圖和實時視圖
技術細節
源代碼基于Apache Spark 1.6.x,(在引入布局化流之前). Spark Streaming架構是純微型批處理架構:
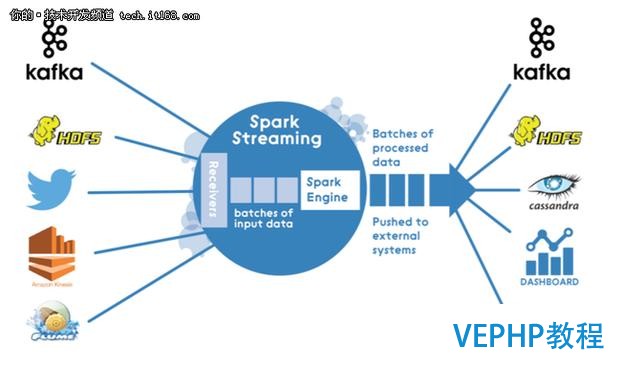
所以處理流應用法式時,我使用DStream連接使用TwitterUtils的Twitter:

在每個微批次(使用可配置的批處置間隔),對新的tweets中hashtags的統計信息的計算,并使用updateStateByKey()狀態轉換函數更新實時視圖的狀態. 為了簡單起見,使用臨時表將實時視圖存儲在存儲器中.
查詢服務反映批處置和實時視圖的合并:

輸出
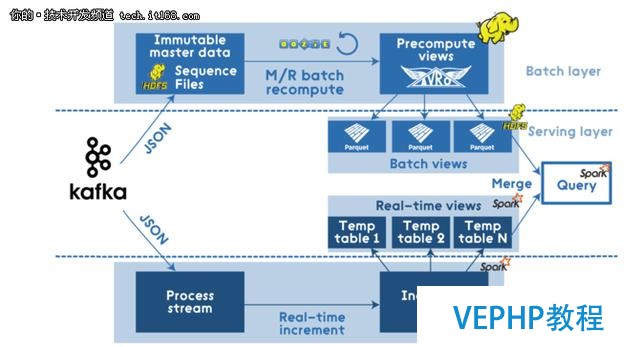
文章開頭提到的基于Hadoop的M/R管道使用Apache Spark來優化:
跋文:
正如之前提到的Lambda Architecture有其優點和缺點,所以支持者和反對者都有.有些人說批處理視圖和實時視圖有很多重復的邏輯,因為最終他們必要從查詢角度創建可合并的視圖.所以他們創建了一個Kappa架構,并稱其為Lambda架構的簡化版.Kappa架構系統是刪除了批處理系統,取而代之的是通過流系統快速提供數據:
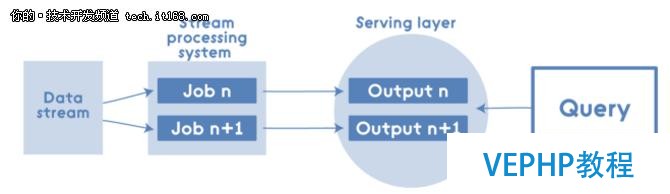
但即使在這種情況下,Kappa Architecture中也可以應用Apache Spark,例如流處置系統:
維易PHP培訓學院每天發布《Apache Spark的Lambda架構示例應用》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
