Apache Kylin查詢性能優(yōu)化
《Apache Kylin查詢性能優(yōu)化》要點:
本文介紹了Apache Kylin查詢性能優(yōu)化,希望對您有用。如果有疑問,可以聯(lián)系我們。
作者:周倚平
編輯:Sammi
Apache Kylin?是一個開源的分布式分析引擎,提供Hadoop之上的SQL查詢接口及多維分析(OLAP)能力以支持超大規(guī)模數(shù)據(jù),最初由eBay Inc. 開發(fā)并貢獻至開源社區(qū),可在亞秒內(nèi)查詢巨大的Hive表.
在Apache Kylin的實際部署過程中,SQL查詢有時并不能如預(yù)期在很短的時間內(nèi)完成,需要開發(fā)人員進行有針對性的分析和優(yōu)化.

在進行分析、優(yōu)化之前,我們需要先了解Apache Kylin查詢的整個生命周期.這一周期主要分為三個階段:第一階段的SQL解析階段,第二階段的SQL查詢階段,以及第三階段的數(shù)據(jù)集中和聚合階段.接下來,我們將分階段為大家解析應(yīng)如何分析和優(yōu)化Apache Kylin的查詢性能.
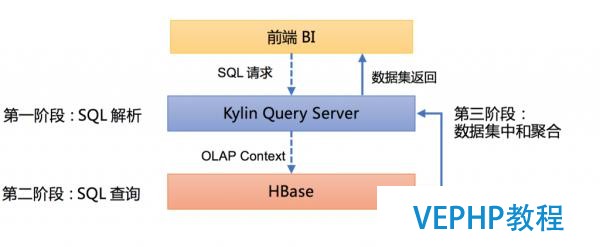
第一階段:SQL解析
在收到SQL哀求后,Kylin Query Server會調(diào)用Calcite對SQL語句進行解析,Calcite的工作流程如下圖.
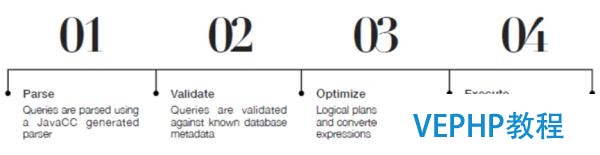
首先,Calcite會將SQL語句通過范式編譯器解析為一顆抽象語義樹(AST).
然后Calcite對這棵AST樹進行優(yōu)化,將Project(select部分)和Filter(where部分)Push down至Hadoop集群.

接著定義implement plan,共有兩種方式:HepPlanner(啟發(fā)式優(yōu)化)和VolcanoPlanner(基于代價的優(yōu)化).目前Kylin只啟用了一些必要的HepPlanner規(guī)則,大部分使用的是VolcanoPlanner.
第二階段:SQL查詢
針對子查詢,UNION等場景,Calcite將SQL分解為多個OLAPContext,同時執(zhí)行Filter Pushdown和Limit Pushdown等優(yōu)化手段,然后提交到HBase上執(zhí)行.
第三階段:數(shù)據(jù)集中和聚合
HBase上的查詢?nèi)蝿?wù)執(zhí)行完成后,數(shù)據(jù)返回至Kylin Query Server端,由Calcite聚合多個OLAP Context的查詢結(jié)果后,最后返回給前端BI.在了解Apache Kylin的查詢生命周期以后,碰到一些查詢速度較慢的情況,就能夠有針對性地進行分析和優(yōu)化了.
1、從模型設(shè)計角度,需要合理調(diào)整RowKey中維度的排列順序,原則是把過濾字段(例如PART_DT等日期型字段)和高基維(例如BUYER_ID,SELLER_ID等客戶字段)放在Rowkey的前列,這樣能夠顯著提升【第二階段SQL查詢】在HBase上數(shù)據(jù)掃描和I/O讀取的效率.
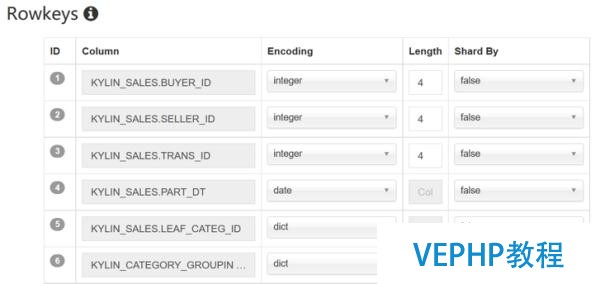
2、Kylin遵循的是“Scatter and gather”模式,而有的時候在【第二階段SQL查詢】時無法實現(xiàn)Filter Pushdown和Limit Pushdown等優(yōu)化手段,需要等待數(shù)據(jù)集中返回Kylin后再篩選數(shù)據(jù),這樣數(shù)據(jù)吞吐量會很大,影響查詢性能.優(yōu)化辦法是重寫SQL語句.
例如,該SQL查詢的篩選條件(斜體加粗部分)放在子查詢中,因此無法實現(xiàn)Filter Pushdown.
select KYLIN_SALES.PART_DT, sum(KYLIN_SALES.PRICE)from KYLIN_SALESinner join (select ACCOUNT_ID, ACCOUNT_BUYER_LEVEL from KYLIN_ACCOUNT whereACCOUNT_COUNTRY = 'US' ) as TTon KYLIN_SALES.BUYER_ID = TT.ACCOUNT_IDgroup by KYLIN_SALES.PART_DT
正確的寫法應(yīng)該是:
select KYLIN_SALES.PART_DT, sum(KYLIN_SALES.PRICE)from KYLIN_SALESinner join KYLIN_ACCOUNT as TT on KYLIN_SALES.BUYER_ID = TT.ACCOUNT_IDwhere TT.ACCOUNT_COUNTRY = 'US'group by KYLIN_SALES.PART_DT
如下圖所示,可以在日志中查看Filter Pushdown是否成功.

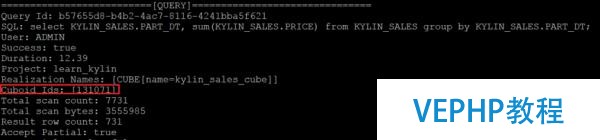
3、查看后臺日志,如果查詢擊中了Base Cuboid,則【第三階段數(shù)據(jù)集中和聚合】將會花費大量時間,優(yōu)化辦法是調(diào)整模型中聚合組,聯(lián)合維度,必要維度的設(shè)計.
相關(guān)優(yōu)化辦法可以參考以下技術(shù)文章:
Apache Kylin高級設(shè)置:聚合組(Aggregation Group)原理解析
Apache Kylin高級設(shè)置:聯(lián)合維度(Joint Dimension)原理解析
Apache Kylin高級設(shè)置:必要維度 (Mandatory Dimension)原理解析
在日志中可以看到查詢擊中的Cuboid組合,如下圖紅框中的131071,將其轉(zhuǎn)換為二進制數(shù)值是0x1 1111 1111 1111 1111,從右至左,共有17個1,表示該Cuboid中包括了17個維度(這里從右至左指代的維度的對應(yīng)順序是Cube模型中Rowkey中自下而上定義的維度),而Cube模型中所有維度的數(shù)量是17,說明擊中了Base Cuboid.
4、從Kylin Query Server處理效率角度,需要實時監(jiān)控Kylin節(jié)點的CPU占有率和內(nèi)存消耗,如果兩者很高的話可能導(dǎo)致【第一階段SQL解析】的效率下降,優(yōu)化辦法是增加Kylin節(jié)點CPU和JVM配置.
具體辦法是修改setenv.sh中的KYLIN_JVM_SETTINGS配置項.
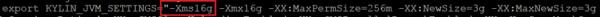
5、監(jiān)控BI前端,Kylin Query Server節(jié)點和Hadoop集群之間的網(wǎng)絡(luò)通信狀態(tài),大數(shù)據(jù)集傳輸可能引起網(wǎng)絡(luò)堵塞,尤其是在多并發(fā)查詢的情況下更容易發(fā)生網(wǎng)絡(luò)堵塞,進而對查詢性能產(chǎn)生顯著影響.優(yōu)化辦法是確保BI前端、Kylin節(jié)點、Hadoop集群之間的網(wǎng)絡(luò)通暢,一個簡單的辦法是用PING命令查看網(wǎng)絡(luò)之間的延遲.
6、對于一些復(fù)雜的SQL語句,如果包括子查詢的話,盡量避免Left Join操作,尤其是Join的兩個數(shù)據(jù)集都較大的情況下,會對查詢性能有顯著的影響.建議將SQL的數(shù)據(jù)處理邏輯放在ETL階段,而前端SQL邏輯保持簡單明了.
《Apache Kylin查詢性能優(yōu)化》是否對您有啟發(fā),歡迎查看更多與《Apache Kylin查詢性能優(yōu)化》相關(guān)教程,學(xué)精學(xué)透。維易PHP學(xué)院為您提供精彩教程。
轉(zhuǎn)載請注明本頁網(wǎng)址:
http://www.snjht.com/jiaocheng/13467.html
同類教程排行
- apache常用配置指令說明
- Hive實戰(zhàn)—通過指定經(jīng)緯度點找出周圍的
- Apache2.2之httpd.conf
- apache怎么做rewrite運行th
- 獨家|一文讀懂Apache Kudu
- Apache 崩潰解決 -- 修改堆棧大
- Apache 個人主頁搭建
- Apache OpenWhisk架構(gòu)概述
- 深入理解Apache Flink核心技術(shù)
- Apache自動跳轉(zhuǎn)到 HTTPS
- Apache Kylin查詢性能優(yōu)化
- Apache Flink異軍突起受歡迎!
- Apache Flume 大數(shù)據(jù)ETL工
- Apache MADlib成功晉升為Ap
- apache常見錯誤代碼
