Hive實(shí)戰(zhàn)—通過指定經(jīng)緯度點(diǎn)找出周圍的POI列表
《Hive實(shí)戰(zhàn)—通過指定經(jīng)緯度點(diǎn)找出周圍的POI列表》要點(diǎn):
本文介紹了Hive實(shí)戰(zhàn)—通過指定經(jīng)緯度點(diǎn)找出周圍的POI列表,希望對(duì)您有用。如果有疑問,可以聯(lián)系我們。
維易PHP培訓(xùn)學(xué)院每天發(fā)布《Hive實(shí)戰(zhàn)—通過指定經(jīng)緯度點(diǎn)找出周圍的POI列表》等實(shí)戰(zhàn)技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養(yǎng)人才。

Apache Hive Logo
Hive實(shí)戰(zhàn)-通過指定經(jīng)緯度點(diǎn)找出周圍的POI列表
需求描述:
有60多個(gè)店鋪,按經(jīng)緯度圈出周圍1公里內(nèi)所有POI列表
輸入:
店鋪1:116.123324,39.343313
店鋪2:116.34232423,40.3423423
店鋪3:116.4231,40.2343
店鋪4:116.2342,39.3433
......
店鋪65:.......
輸出結(jié)果:
excel表,表頭包含:店鋪id、POI名稱、一級(jí)分類、二級(jí)分類、經(jīng)緯度
數(shù)據(jù)描述:
aoipoi表
主要字段:name, category_id, lng, lat
name:aoi或poi名稱
type:name的類型(aoi或poi)
category_id:分類id.存儲(chǔ)格式為“一級(jí)分類id|二級(jí)分類id,一級(jí)分類id|二級(jí)分類id,一級(jí)分類id|二級(jí)分類id”,可為空字符
lng:經(jīng)度
lat:緯度
mst_dict表:
主要字段:id, name
id:分類的id
name:分類的名稱
思路:
分別得到每個(gè)店鋪周圍1公里內(nèi)的數(shù)據(jù),然后合并在一起,再把分類id轉(zhuǎn)化為中文存入HDFS文件.
(把id轉(zhuǎn)化放在后面可以減少需要轉(zhuǎn)化的id)
Hive SQL:
# 添加臨時(shí)函數(shù):指定點(diǎn)經(jīng)緯度1km內(nèi)的數(shù)據(jù)(下面的UDF在以后講UDF/UDAF/UDTF時(shí)一并貼出)
add jar /home/zyl/hive-udf-1.0-SNAPSHOT.jar;
create temporary function dis_lnglat as 'com.zyl.udf.CalculatedLnglatDistance';
# 查詢:店鋪ID、POI名稱、一級(jí)分類名稱、二級(jí)分類名稱、經(jīng)度、緯度
with q1 as
(
select name, category_id, lng, lat from zyl.aoipoi a where a.type='poi'
)
insert overwrite directory '/user/zyl/tmp_cpy_tab/20171017/lnglat'
select /*+mapjoin(b)*/concat_ws("\t", a.id, poiname, one_cate, coalesce(name, ''), lng, lat) line from (
select /*+mapjoin(b)*/a.id, poiname, coalesce(name, '') one_cate, two_cate, lng, lat from (
select name poiname, coalesce(split(category_id2,'\\|')[0], '') one_cate, coalesce(split(category_id2,'\\|')[1], '') two_cate, lng, lat, id from (
select name, category_id, lng, lat, '1' id from q1 where dis_lnglat(lng,lat,116.123324,39.343313)<=1000
union all
select name, category_id, lng, lat, '2' id from q1 where dis_lnglat(lng,lat,116.34232423,40.3423423)<=1000
union all
select name, category_id, lng, lat, '3' id from q1 where dis_lnglat(lng,lat,116.4231,40.2343)<=1000
union all
select name, category_id, lng, lat, '4' id from q1 where dis_lnglat(lng,lat,116.2342,39.3433)<=1000
) a LATERAL VIEW explode(split(category_id,'\\,')) myTable1 AS category_id2
) a left join zyl.mst_dict b on (a.one_cate = b.id)
) a left join zyl.mst_dict b on (a.two_cate = b.id)
group by a.id, poiname, one_cate, name, lng, lat
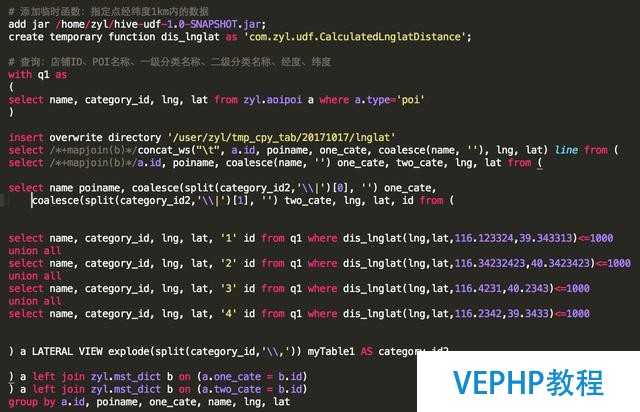
Hive SQL 脫敏后截圖

結(jié)果前10條脫敏后示例
講解
函數(shù):
coalesce()
split()
explode()
非空查找函數(shù): COALESCE
語法: COALESCE(T v1, T v2,…)
返回值: T
說明: 返回參數(shù)中的第一個(gè)非空值;如果所有值都為NULL,那么返回NULL
舉例:
select COALESCE(null,'is null','not null');
is null
select COALESCE(null, 0, 1);
0
select COALESCE('abc', 0, 1);
abc
分割字符串函數(shù): SPLIT
語法: split(string str, stringpat)
返回值: array
說明:按照pat字符串分割str,會(huì)返回分割后的字符串?dāng)?shù)組
舉例:
select split('abtcdtef','t');
["ab","cd","ef"]
select split('ab,cd,ef','\\,');
["ab","cd","ef"]
行拆列函數(shù):EXPLODE
explode(ARRAY) 列表中的每個(gè)元素生成一行.在本篇文章中用到了split之后為數(shù)組(ARRAY)交給explode處理.
explode(MAP) map中每個(gè)key-value對(duì),生成一行,key為一列,value為一列
限制:
1、No other expressions are allowed in SELECT
SELECT pageid, explode(adid_list) AS myCol... is not supported
2、UDTF's can't be nested
SELECT explode(explode(adid_list)) AS myCol... is not supported
3、GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY is not supported
SELECT explode(adid_list) AS myCol ... GROUP BY myCol is not supported
下面語法/功能在以后再講:
with q1 as table
union all
insert overwrite directory
LATERAL VIEW ... myTable AS ... alias
mapjoin
left join
轉(zhuǎn)義(\\|、\\,)
注冊(cè)函數(shù)
轉(zhuǎn)載請(qǐng)注明本頁網(wǎng)址:
http://www.snjht.com/jiaocheng/13464.html
同類教程排行
- apache常用配置指令說明
- Hive實(shí)戰(zhàn)—通過指定經(jīng)緯度點(diǎn)找出周圍的
- Apache2.2之httpd.conf
- apache怎么做rewrite運(yùn)行th
- 獨(dú)家|一文讀懂Apache Kudu
- Apache 崩潰解決 -- 修改堆棧大
- Apache 個(gè)人主頁搭建
- Apache OpenWhisk架構(gòu)概述
- 深入理解Apache Flink核心技術(shù)
- Apache自動(dòng)跳轉(zhuǎn)到 HTTPS
- Apache Kylin查詢性能優(yōu)化
- Apache Flink異軍突起受歡迎!
- Apache Flume 大數(shù)據(jù)ETL工
- Apache MADlib成功晉升為Ap
- apache常見錯(cuò)誤代碼
