獨家|一文讀懂Apache Kudu
《獨家|一文讀懂Apache Kudu》要點:
本文介紹了獨家|一文讀懂Apache Kudu,希望對您有用。如果有疑問,可以聯系我們。
相關主題:apache配置
維易PHP培訓學院每天發布《獨家|一文讀懂Apache Kudu》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。

前言
Apache Kudu是由Cloudera開源的存儲引擎,可以同時提供低延遲的隨機讀寫和高效的數據分析能力.Kudu支持水平擴展,使用Raft協議進行一致性保證,并且與Cloudera Impala和Apache Spark等當前流行的大數據查詢和分析工具結 合緊密.本文將為您介紹Kudu的一些基本概念和架構以及在企業中的應用,使您對Kudu有一個較為全面的了解.
一、為什么需要Kudu
Kudu這個名字聽起來可能有些奇怪,實際上,Kudu是一種非洲的大羚羊,中文名叫“捻角羚”,就是下圖這個樣子:

比擬有意思的是,同為Cloudera公司開源的另一款產品Impala,是另一種非洲的羚羊,叫做“黑斑羚”,也叫“高角羚”.不知道Cloudera公司為什么這么喜歡羚羊,也許是因為羚羊的速度快吧.
言歸正傳,現在提起大數據存儲,我們能想到的技術有很多,比如HDFS,以及在HDFS上的列式存儲技術Apache Parquet,Apache ORC,還有以KV形式存儲半結構化數據的Apache HBase和Apache Cassandra等等.既然有了如此多的存儲技術,Cloudera公司為什么要開發出一款全新的存儲引擎Kudu呢?
事實上,當前的這些存儲技術都存在著一定的局限性.對于會被用來進行分析的靜態數據集來說,使用Parquet或者ORC存儲是一種明智的選擇.但是目前的列式存儲技術都不能更新數據,而且隨機讀寫性能感人.而可以進行高效隨機讀寫的HBase、Cassandra等數據庫,卻并不適用于基于SQL的數據分析方向.
所以現在的企業中,經常會存儲兩套數據分別用于實時讀寫與數據分析,先將數據寫入HBase中,再定期通過ETL到Parquet進行數據同步.但是這樣做有很多缺點:
用戶需要在兩套系統間編寫和維護復雜的ETL邏輯.
時效性較差.因為ETL通常是一個小時、幾個小時甚至是一天一次,那么可供分析的數據就需要一個小時至一天的時間后才進入到可用狀態,也就是說從數據到達到可被分析之間是會存在一個較為明顯的“空檔期”的.
更新需求難以滿足.在實際情況中可能會有一些對已經寫入的數據的更新需求,這種情況往往需要對歷史數據進行更新,而對Parquet這種靜態數據集的更新操作,代價是非常昂貴的.
存儲資源浪費.兩套存儲系統意味著占用的磁盤資源翻倍了,造成了本錢的提升.
我們知道,基于HDFS的存儲技術,比如Parquet,具有高吞吐量連續讀取數據的能力;而HBase和Cassandra等技術適用于低延遲的隨機讀寫場景,那么有沒有一種技術可以同時具備這兩種優點呢?Kudu提供了一種“happy medium”的選擇:
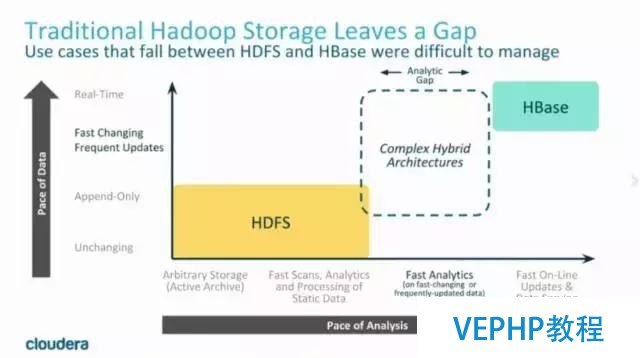
Kudu不但提供了行級的插入、更新、刪除API,同時也提供了接近Parquet性能的批量掃描操作.使用同一份存儲,既可以進行隨機讀寫,也可以滿足數據分析的要求.
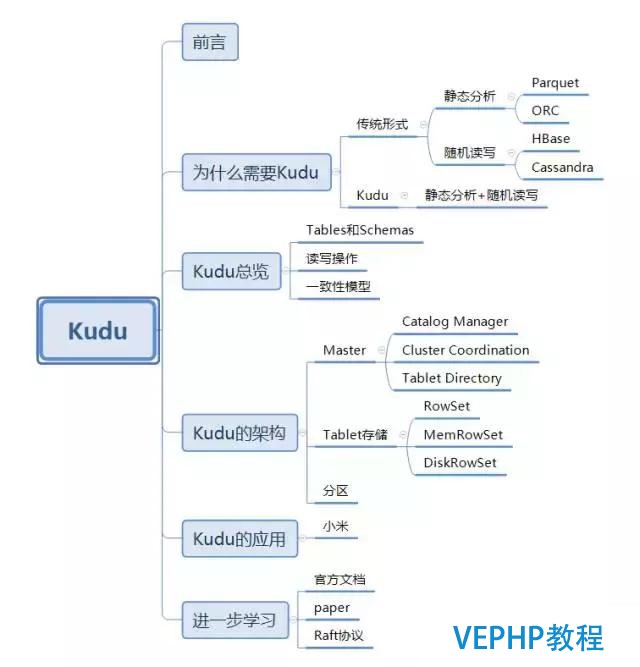
二、Kudu總覽
Tables和Schemas
從用戶角度來看,Kudu是一種存儲結構化數據表的存儲系統.在一個Kudu集群中可以定義任意數量的table,每個table都需要預先定義好schema.每個table的列數是確定的,每一列都需要有名字和類型,每個表中可以把其中一列或多列定義為主鍵.這么看來,Kudu更像關系型數據庫,而不是像HBase、Cassandra和MongoDB這些NoSQL數據庫.不過Kudu目前還不能像關系型數據一樣支持二級索引. Kudu使用確定的列類型,而不是類似于NoSQL的“everything is byte”.這可以帶來兩點好處:
確定的列類型使Kudu可以進行類型特有的編碼.
可以提供 SQL-like 元數據給其他上層查詢工具,比如BI工具.
讀寫操作
用戶可以使用 Insert,Update和Delete API對表進行寫操作.不論使用哪種API,都必須指定主鍵.但批量的刪除和更新操作需要依賴更高層次的組件(比如Impala、Spark).Kudu目前還不支持多行事務. 而在讀操作方面,Kudu只提供了Scan操作來獲取數據.用戶可以通過指定過濾條件來獲取本身想要讀取的數據,但目前只提供了兩種類型的過濾條件:主鍵范圍和列值與常數的比較.由于Kudu在硬盤中的數據采用列式存儲,所以只掃描需要的列將極大地提高讀取性能.
一致性模型
Kudu為用戶提供了兩種一致性模型.默認的一致性模型是snapshot consistency.這種一致性模型保證用戶每次讀取出來的都是一個可用的快照,但這種一致性模型只能保證單個client可以看到最新的數據,但不能保證多個client每次取出的都是最新的數據.
另一種一致性模型external consistency可以在多個client之間保證每次取到的都是最新數據,但是Kudu沒有提供默認的實現,需要用戶做一些額外工作.
為了實現external consistency,Kudu提供了兩種方式:
在client之間傳播timestamp token.在一個client完成一次寫入后,會得到一個timestamp token,然后這個client把這個token傳播到其他client,這樣其他client就可以通過token取到最新數據了.不過這個方式的復雜度很高.
通過commit-wait方式,這有些類似于Google的Spanner.但是目前基于NTP的commit-wait方式延遲實在有點高.不過Kudu相信,隨著Spanner的出現,未來幾年內基于real-time clock的技術將會逐漸成熟.
三、Kudu的架構
與HDFS和HBase相似,Kudu使用單個的Master節點,用來管理集群的元數據,并且使用任意數量的Tablet Server節點用來存儲實際數據.可以部署多個Master節點來提高容錯性.
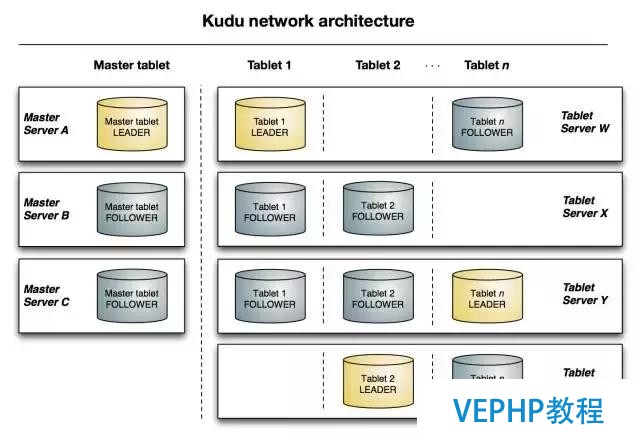
Master
Kudu的master節點負責整個集群的元數據管理和服務協調.它承擔著以下功能:
作為catalog manager,master節點管理著集群中所有table和tablet的schema及一些其他的元數據.
作為cluster coordinator,master節點追蹤著所有server節點是否存活,并且當server節點掛掉后協調數據的重新分布.
作為tablet directory,master跟蹤每個tablet的位置.
Catalog Manager
Kudu的master節點會持有一個單tablet的table——catalog table,但是用戶是不能直接拜訪的.master將內部的catalog信息寫入該tablet,并且將整個catalog的信息緩存到內存中.隨著現在商用服務器上的內存越來越大,并且元數據信息占用的空間其實并不大,所以master不容易存在性能瓶頸.catalog table保存了所有table的schema的版本以及table的狀態(創建、運行、刪除等).
Cluster Coordination
Kudu集群中的每個tablet server都需要配置master的主機名列表.當集群啟動時,tablet server會向master注冊,并發送所有tablet的信息.tablet server第一次向master發送信息時會發送所有tablet的全量信息,后續每次發送則只會發送增量信息,僅包括新創建、刪除或修改的tablet的信息. 作為cluster coordination,master只是集群狀態的觀察者.對于tablet server中tablet的副本位置、Raft配置和schema版本等信息的控制和修改由tablet server自身完成.master只需要下發命令,tablet server執行成功后會自動上報處理的結果.
Tablet Directory
因為master上緩存了集群的元數據,所以client讀寫數據的時候,肯定是要通過master才能獲取到tablet的位置等信息.但是如果每次讀寫都要通過master節點的話,那master就會變成這個集群的性能瓶頸,所以client會在本地緩存一份它需要拜訪的tablet的位置信息,這樣就不用每次讀寫都從master中獲取. 因為tablet的位置可能也會發生變化(比如某個tablet server節點crash掉了),所以當tablet的位置發生變化的時候,client會收到相應的通知,然后再去master上獲取一份新的元數據信息.
Tablet存儲
在數據存儲方面,Kudu選擇完全由本身實現,而沒有借助于已有的開源方案.tablet存儲主要想要實現的目標為:
快速的列掃描
低延遲的隨機讀寫
一致性的性能
RowSets
在Kudu中,tablet被細分為更小的單元,叫做RowSets.一些RowSet僅存在于內存中,被稱為MemRowSets,而另一些則同時使用內存和硬盤,被稱為DiskRowSets.任何一行未被刪除的數據都只能存在于一個RowSet中. 無論任何時候,一個tablet僅有一個MemRowSet用來保留最新插入的數據,并且有一個后臺線程會定期把內存中的數據flush到硬盤上. 當一個MemRowSet被flush到硬盤上以后,一個新的MemRowSet會替代它.而原有的MemRowSet會變成一到多個DiskRowSet.flush操作是完全同步進行的,在進行flush時,client同樣可以進行讀寫操作.
MemRowSet
MemRowSets是一個可以被并發拜訪并進行過鎖優化的B-tree,主要是基于MassTree來設計的,但存在幾點不同:
Kudu并不支持直接刪除操作,由于使用了MVCC,所以在Kudu中刪除操作其實是插入一條標志著刪除的數據,這樣就可以推遲刪除操作.
類似刪除操作,Kudu也不支持原地更新操作.
將tree的leaf鏈接起來,就像B+-tree.這一步關鍵的操作可以明顯地提升scan操作的性能.
沒有實現字典樹(trie樹),而是只用了單個tree,因為Kudu并不適用于極高的隨機讀寫的場景.
與Kudu中其他模塊中的數據結構不同,MemRowSet中的數據使用行式存儲.因為數據都在內存中,所以性能也是可以接受的,而且Kudu對在MemRowSet中的數據結構進行了一定的優化.
DiskRowSet
當MemRowSet被flush到硬盤上,就變成了DiskRowSet.當MemRowSet被flush到硬盤的時候,每32M就會形成一個新的DiskRowSet,這主要是為了保證每個DiskRowSet不會太大,便于后續的增量compaction操作.Kudu通過將數據分為base data和delta data,來實現數據的更新操作.Kudu會將數據按列存儲,數據被切分成多個page,并使用B-tree進行索引.除了用戶寫入的數據,Kudu還會將主鍵索引存入一個列中,并且提供布隆過濾器來進行高效查找.
Compaction
為了提高查詢性能,Kudu會定期進行compaction操作,合并delta data與base data,對標記了刪除的數據進行刪除,并且會合并一些DiskRowSet.
分區
和許多分布式存儲系統一樣,Kudu的table是水平分區的.BigTable只提供了range分區,Cassandra只提供hash分區,而Kudu提供了較為靈活的分區方式.當用戶創建一個table時,可以同時指定table的的partition schema,partition schema會將primary key映射為partition key.一個partition schema包含0到多個hash-partitioning規則和一個range-partitioning規則.通過靈活地組合各種partition規則,用戶可以創造適用于自己業務場景的分區方式.
四、Kudu的應用
Kudu的應用場景很廣泛,比如可以進行實時的數據分析,用于數據可能會存在變化的時序數據應用等,甚至還有人探討過使用Kudu替代Kafka的可行性(詳情請戳 http://blog.rodeo.io/2016/01/24/kudu-as-a-more-flexible-kafka.html).不過Kudu最有名和最成功的應用案例,還是國內的小米.小米公司不僅使用Kudu,還深度參與了Kudu的開發.Kudu項目在2012年10月由Cloudera公司發起,2015年10月對外頒布,2015年12月進入Apache孵化器,但是小米公司早在2014年9月就加入到Kudu的開發中了. 下面我們可以跟隨Cloudera在宣傳Kudu時使用的ppt來看一看Kudu在小米的使用.

從上圖中我們可以看到,Kudu在小米主要用來對手機app和后端服務的RPC調用事件進行追蹤,以及對服務進行監控.在小米的使用場景下,Kudu集群已經達到每天200億次寫入,并且還在增長. Kudu除了優秀的性能,更為重要的是可以簡化數據處理的流程.
在使用Kudu以前,小米的數據處理流程是這樣的:
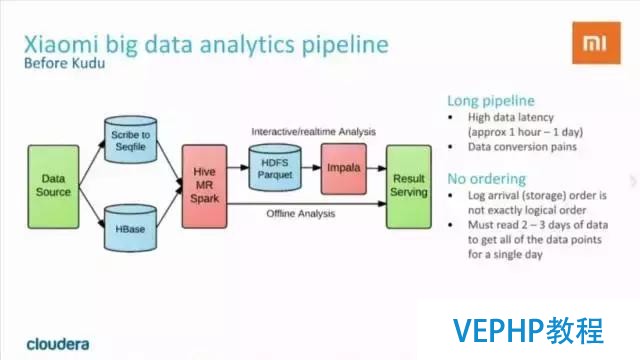
可以看到,數據處理的流程很長.這種處理模式不但較為復雜,而且latency較高,通常需要等待較長的時間(1 hour - 1day)才能得到分析結果.
下面再來看看使用Kudu以后的數據處理流程是怎樣的:
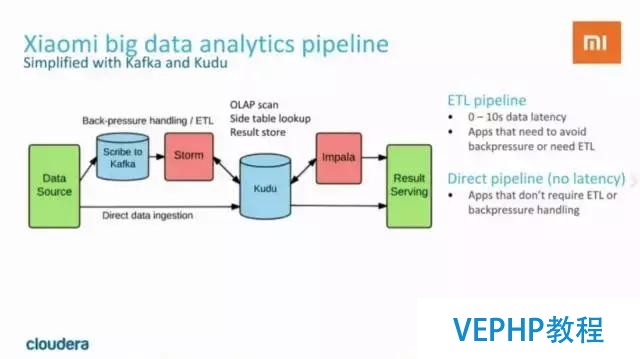
使用Kudu以后,數據處理的鏈路被簡化了,而且得益于Kudu對隨機讀寫和數據分析操作的支持都很好,可以直接對Kudu中的數據進行交互式分析,降低了系統復雜度,并且latency被大大縮短(0 ~ 10s).
五、進一步學習
如果您看了本文的介紹后想進一步學習Kudu,以下途徑可以贊助您快速入門:
Documentation(http://kudu.apache.org/docs/),官方文檔永遠是學習開源項目的最好去處.
Paper(http://kudu.apache.org/kudu.pdf),Kudu的論文可以贊助您深入了解Kudu的設計思想.
Raft協議(https://raft.github.io/),雖然不屬于Kudu的內容,但是Kudu的一致性協議使用了Raft協議,了解Raft協議可以贊助您更好地了解Kudu及其他分布式開源系統.
Apache Kudu as a More Flexible And Reliable Kafka-style Queue (http://blog.rodeo.io/2016/01/24/kudu-as-a-more-flexible-kafka.html),
這篇博客也許能對您在如何使用Kudu的問題上有一些啟發.
比擬遺憾的是,由于Kudu還很年輕,所以并沒有比擬好的相關書籍出版.計算機是一門實踐性較強的學科,所以動手實踐是成為Kudu專家的必經之路:github地址(https://github.com/apache/kudu).
