新一代大數(shù)據(jù)處理引擎 Apache Flink
《新一代大數(shù)據(jù)處理引擎 Apache Flink》要點(diǎn):
本文介紹了新一代大數(shù)據(jù)處理引擎 Apache Flink,希望對(duì)您有用。如果有疑問,可以聯(lián)系我們。
相關(guān)主題:apache配置
《新一代大數(shù)據(jù)處理引擎 Apache Flink》是否對(duì)您有啟發(fā),歡迎查看更多與《新一代大數(shù)據(jù)處理引擎 Apache Flink》相關(guān)教程,學(xué)精學(xué)透。維易PHP學(xué)院為您提供精彩教程。
大數(shù)據(jù)計(jì)算引擎的發(fā)展
這幾年大數(shù)據(jù)的飛速發(fā)展,出現(xiàn)了很多熱門的開源社區(qū),其中著名的有 Hadoop、Storm,以及后來的 Spark,他們都有著各自專注的應(yīng)用場景.Spark 掀開了內(nèi)存計(jì)算的先河,也以內(nèi)存為賭注,贏得了內(nèi)存計(jì)算的飛速發(fā)展.Spark 的火熱或多或少的掩蓋了其他分布式計(jì)算的系統(tǒng)身影.就像 Flink,也就在這個(gè)時(shí)候默默的發(fā)展著.
在國外一些社區(qū),有很多人將大數(shù)據(jù)的計(jì)算引擎分成了 4 代,當(dāng)然,也有很多人不會(huì)認(rèn)同.我們先姑且這么認(rèn)為和討論.
首先第一代的計(jì)算引擎,無疑就是 Hadoop 承載的 MapReduce.這里大家應(yīng)該都不會(huì)對(duì) MapReduce 陌生,它將計(jì)算分為兩個(gè)階段,分別為 Map 和 Reduce.對(duì)于上層應(yīng)用來說,就不得不想方設(shè)法去拆分算法,甚至于不得不在上層應(yīng)用實(shí)現(xiàn)多個(gè) Job 的串聯(lián),以完成一個(gè)完整的算法,例如迭代計(jì)算.
由于這樣的弊端,催生了支持 DAG 框架的產(chǎn)生.因此,支持 DAG 的框架被劃分為第二代計(jì)算引擎.如 Tez 以及更上層的 Oozie.這里我們不去細(xì)究各種 DAG 實(shí)現(xiàn)之間的區(qū)別,不過對(duì)于當(dāng)時(shí)的 Tez 和 Oozie 來說,大多還是批處理的任務(wù).
接下來就是以 Spark 為代表的第三代的計(jì)算引擎.第三代計(jì)算引擎的特點(diǎn)主要是 Job 內(nèi)部的 DAG 支持(不跨越 Job),以及強(qiáng)調(diào)的實(shí)時(shí)計(jì)算.在這里,很多人也會(huì)認(rèn)為第三代計(jì)算引擎也能夠很好的運(yùn)行批處理的 Job.
隨著第三代計(jì)算引擎的出現(xiàn),促進(jìn)了上層應(yīng)用快速發(fā)展,例如各種迭代計(jì)算的性能以及對(duì)流計(jì)算和 SQL 等的支持.Flink 的誕生就被歸在了第四代.這應(yīng)該主要表現(xiàn)在 Flink 對(duì)流計(jì)算的支持,以及更一步的實(shí)時(shí)性上面.當(dāng)然 Flink 也可以支持 Batch 的任務(wù),以及 DAG 的運(yùn)算.
或許會(huì)有人不同意以上的分類,我覺得其實(shí)這并不重要的,重要的是體會(huì)各個(gè)框架的差異,以及更適合的場景.并進(jìn)行理解,沒有哪一個(gè)框架可以完美的支持所有的場景,也就不可能有任何一個(gè)框架能完全取代另一個(gè),就像 Spark 沒有完全取代 Hadoop,當(dāng)然 Flink 也不可能取代 Spark.本文將致力描述 Flink 的原理以及應(yīng)用.
回頁首
Flink 簡介
很多人可能都是在 2015 年才聽到 Flink 這個(gè)詞,其實(shí)早在 2008 年,Flink 的前身已經(jīng)是柏林理工大學(xué)一個(gè)研究性項(xiàng)目, 在 2014 被 Apache 孵化器所接受,然后迅速地成為了 ASF(Apache Software Foundation)的頂級(jí)項(xiàng)目之一.Flink 的最新版本目前已經(jīng)更新到了 0.10.0 了,在很多人感慨 Spark 的快速發(fā)展的同時(shí),或許我們也該為 Flink 的發(fā)展速度點(diǎn)個(gè)贊.
Flink 是一個(gè)針對(duì)流數(shù)據(jù)和批數(shù)據(jù)的分布式處理引擎.它主要是由 Java 代碼實(shí)現(xiàn).目前主要還是依靠開源社區(qū)的貢獻(xiàn)而發(fā)展.對(duì) Flink 而言,其所要處理的主要場景就是流數(shù)據(jù),批數(shù)據(jù)只是流數(shù)據(jù)的一個(gè)極限特例罷了.再換句話說,Flink 會(huì)把所有任務(wù)當(dāng)成流來處理,這也是其最大的特點(diǎn).Flink 可以支持本地的快速迭代,以及一些環(huán)形的迭代任務(wù).并且 Flink 可以定制化內(nèi)存管理.在這點(diǎn),如果要對(duì)比 Flink 和 Spark 的話,Flink 并沒有將內(nèi)存完全交給應(yīng)用層.這也是為什么 Spark 相對(duì)于 Flink,更容易出現(xiàn) OOM 的原因(out of memory).就框架本身與應(yīng)用場景來說,Flink 更相似與 Storm.如果之前了解過 Storm 或者 Flume 的讀者,可能會(huì)更容易理解 Flink 的架構(gòu)和很多概念.下面讓我們先來看下 Flink 的架構(gòu)圖.
圖 1. Flink 架構(gòu)圖
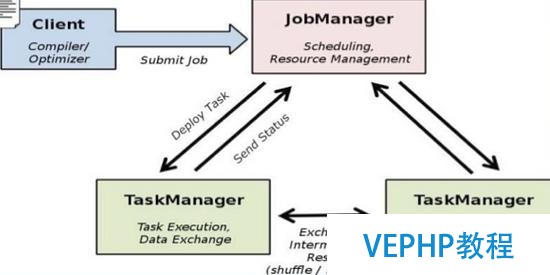
如圖 1 所示,我們可以了解到 Flink 幾個(gè)最基礎(chǔ)的概念,Client、JobManager 和 TaskManager.Client 用來提交任務(wù)給 JobManager,JobManager 分發(fā)任務(wù)給 TaskManager 去執(zhí)行,然后 TaskManager 會(huì)心跳的報(bào)告請(qǐng)示任務(wù)狀態(tài).看到這里,有的人應(yīng)該已經(jīng)有種回到 Hadoop 一代的錯(cuò)覺.確實(shí),從架構(gòu)圖去看,JobManager 很像當(dāng)年的 JobTracker,TaskManager 也很像當(dāng)年的 TaskTracker.然而有一個(gè)最重要的區(qū)別就是 TaskManager 之間是是流(Stream).其次,Hadoop 一代中,只有 Map 和 Reduce 之間的 Shuffle,而對(duì) Flink 而言,可能是很多級(jí),并且在 TaskManager 內(nèi)部和 TaskManager 之間都會(huì)有數(shù)據(jù)傳遞,而不像 Hadoop,是固定的 Map 到 Reduce.
回頁首
Flink 中的調(diào)度簡述
在 Flink 集群中,計(jì)算資源被定義為 Task Slot.每個(gè) TaskManager 會(huì)擁有一個(gè)或多個(gè) Slots.JobManager 會(huì)以 Slot 為單位調(diào)度 Task.但是這里的 Task 跟我們?cè)?Hadoop 中的理解是有區(qū)別的.對(duì) Flink 的 JobManager 來說,其調(diào)度的是一個(gè) Pipeline 的 Task,而不是一個(gè)點(diǎn).舉個(gè)例子,在 Hadoop 中 Map 和 Reduce 是兩個(gè)獨(dú)立調(diào)度的 Task,并且都會(huì)去占用計(jì)算資源.對(duì) Flink 來說 MapReduce 是一個(gè) Pipeline 的 Task,只占用一個(gè)計(jì)算資源.類同的,如果有一個(gè) MRR 的 Pipeline Task,在 Flink 中其也是一個(gè)被整體調(diào)度的 Pipeline Task.在 TaskManager 中,根據(jù)其所擁有的 Slot 個(gè)數(shù),同時(shí)會(huì)擁有多個(gè) Pipeline.
在 Flink StandAlone 的部署模式中,這個(gè)還比擬容易理解.因?yàn)?Flink 自身也需要簡單的管理計(jì)算資源(Slot).當(dāng) Flink 部署在 Yarn 上面之后,Flink 并沒有弱化資源管理.也就是說這時(shí)候的 Flink 在做一些 Yarn 該做的事情.從設(shè)計(jì)角度來講,我認(rèn)為這是不太合理的.如果 Yarn 的 Container 無法完全隔離 CPU 資源,這時(shí)候?qū)?Flink 的 TaskManager 配置多個(gè) Slot,應(yīng)該會(huì)出現(xiàn)資源不公平利用的現(xiàn)象.Flink 如果想在數(shù)據(jù)中心更好的與其他計(jì)算框架共享計(jì)算資源,應(yīng)該盡量不要干預(yù)計(jì)算資源的分配和定義.
需要深度學(xué)習(xí) Flink 調(diào)度讀者,可以在 Flink 的源碼目錄中找到 flink-runtime 這個(gè)文件夾,JobManager 的 code 基本都在這里.
回頁首
Flink 的生態(tài)圈
一個(gè)計(jì)算框架要有長遠(yuǎn)的發(fā)展,必須打造一個(gè)完整的 Stack.不然就跟紙上談兵一樣,沒有任何意義.只有上層有了具體的應(yīng)用,并能很好的發(fā)揮計(jì)算框架自己的優(yōu)勢,那么這個(gè)計(jì)算框架才能吸引更多的資源,才會(huì)更快的進(jìn)步.所以 Flink 也在努力構(gòu)建自己的 Stack.
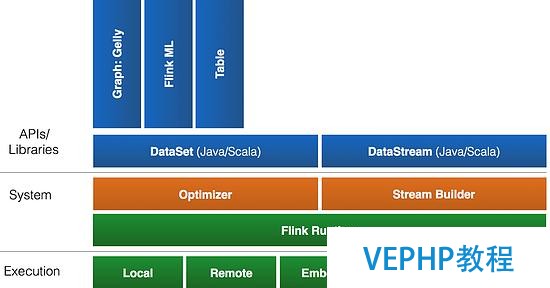
Flink 首先支持了 Scala 和 Java 的 API,Python 也正在測試中.Flink 通過 Gelly 支持了圖操作,還有機(jī)器學(xué)習(xí)的 FlinkML.Table 是一種接口化的 SQL 支持,也就是 API 支持,而不是文本化的 SQL 解析和執(zhí)行.對(duì)于完整的 Stack 我們可以參考下圖.
圖 2. Flink 的 Stack
Flink 為了更廣泛的支持大數(shù)據(jù)的生態(tài)圈,其下也實(shí)現(xiàn)了很多 Connector 的子項(xiàng)目.最熟悉的,當(dāng)然就是與 Hadoop HDFS 集成.其次,Flink 也宣布支持了 Tachyon、S3 以及 MapRFS.不過對(duì)于 Tachyon 以及 S3 的支持,都是通過 Hadoop HDFS 這層包裝實(shí)現(xiàn)的,也就是說要使用 Tachyon 和 S3,就必須有 Hadoop,而且要更改 Hadoop 的配置(core-site.xml).如果瀏覽 Flink 的代碼目錄,我們就會(huì)看到更多 Connector 項(xiàng)目,例如 Flume 和 Kafka.
回頁首
Flink 的部署
Flink 有三種部署模式,分別是 Local、Standalone Cluster 和 Yarn Cluster.對(duì)于 Local 模式來說,JobManager 和 TaskManager 會(huì)公用一個(gè) JVM 來完成 Workload.如果要驗(yàn)證一個(gè)簡單的應(yīng)用,Local 模式是最方便的.實(shí)際應(yīng)用中大多使用 Standalone 或者 Yarn Cluster.下面我主要介紹下這兩種模式.
Standalone 模式
在搭建 Standalone 模式的 Flink 集群之前,我們需要先下載 Flink 安裝包.這里我們需要下載 Flink 針對(duì) Hadoop 1.x 的包.下載并解壓后,進(jìn)到 Flink 的根目錄,然后查看 conf 文件夾,如下圖.
圖 3. Flink 的目錄結(jié)構(gòu)
我們需要指定 Master 和 Worker.Master 機(jī)器會(huì)啟動(dòng) JobManager,Worker 則會(huì)啟動(dòng) TaskManager.因此,我們需要修改 conf 目錄中的 master 和 slaves.在配置 master 文件時(shí),需要指定 JobManager 的 UI 監(jiān)聽端口.一般情況下,JobManager 只需配置一個(gè),Worker 則須配置一個(gè)或多個(gè)(以行為單位).示例如下:
micledeMacBook-Pro:conf micle$ cat masters
localhost:8081
micledeMacBook-Pro:conf micle$ cat slaves
localhost
在 conf 目錄中找到文件 flink-conf.yaml.在這個(gè)文件中定義了 Flink 各個(gè)模塊的基本屬性,如 RPC 的端口,JobManager 和 TaskManager 堆的大小等.在不考慮 HA 的情況下,一般只需要修改屬性 taskmanager.numberOfTaskSlots,也就是每個(gè) Task Manager 所擁有的 Slot 個(gè)數(shù).這個(gè)屬性,一般設(shè)置成機(jī)器 CPU 的 core 數(shù),用來平衡機(jī)器之間的運(yùn)算性能.其默認(rèn)值為 1.配置完成后,使用下圖中的命令啟動(dòng) JobManager 和 TaskManager(啟動(dòng)之前,需要確認(rèn) Java 的環(huán)境是否已經(jīng)就緒).
圖 4. 啟動(dòng) StandAlone 模式的 Flink
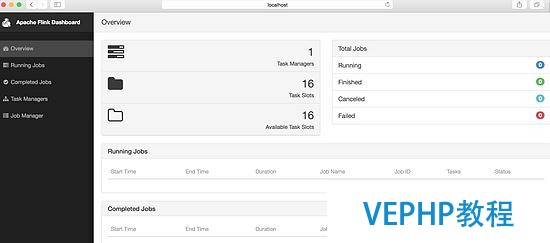
啟動(dòng)之后我們就可以登陸 Flink 的 GUI 頁面.在頁面中我們可以看到 Flink 集群的基本屬性,在 JobManager 和 TaskManager 的頁面中,可以看到這兩個(gè)模塊的屬性.目前 Flink 的 GUI,只提供了簡單的查看功能,無法動(dòng)態(tài)修改配置屬性.一般在企業(yè)級(jí)應(yīng)用中,這是很難被接受的.因此,一個(gè)企業(yè)真正要應(yīng)用 Flink 的話,估計(jì)也不得不加強(qiáng) WEB 的功能.
圖 5. Flink 的 GUI 頁面
Yarn Cluster 模式
在一個(gè)企業(yè)中,為了最大化的利用集群資源,一般都會(huì)在一個(gè)集群中同時(shí)運(yùn)行多種類型的 Workload.因此 Flink 也支持在 Yarn 上面運(yùn)行.首先,讓我們通過下圖了解下 Yarn 和 Flink 的關(guān)系.
圖 6. Flink 與 Yarn 的關(guān)系
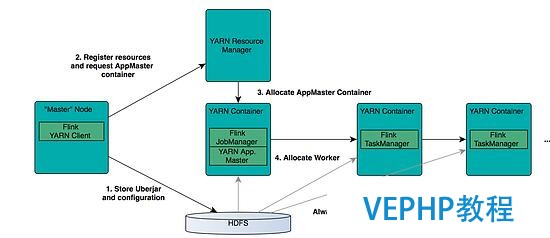
在圖中可以看出,Flink 與 Yarn 的關(guān)系與 MapReduce 和 Yarn 的關(guān)系是一樣的.Flink 通過 Yarn 的接口實(shí)現(xiàn)了本身的 App Master.當(dāng)在 Yarn 中部署了 Flink,Yarn 就會(huì)用本身的 Container 來啟動(dòng) Flink 的 JobManager(也就是 App Master)和 TaskManager.
了解了 Flink 與 Yarn 的關(guān)系,我們就簡單看下部署的步驟.在這之前需要先部署好 Yarn 的集群,這里我就不做介紹了.我們可以通過以下的命令查看 Yarn 中現(xiàn)有的 Application,并且來檢查 Yarn 的狀態(tài).
yarn application –list
如果命令正確返回了,就說明 Yarn 的 RM 目前已經(jīng)在啟動(dòng)狀態(tài).針對(duì)不同的 Yarn 版本,Flink 有不同的安裝包.我們可以在 Apache Flink 的下載頁中找到對(duì)應(yīng)的安裝包.我的 Yarn 版本為 2.7.1.再介紹具體的步驟之前,我們需要先了解 Flink 有兩種在 Yarn 上面的運(yùn)行模式.一種是讓 Yarn 直接啟動(dòng) JobManager 和 TaskManager,另一種是在運(yùn)行 Flink Workload 的時(shí)候啟動(dòng) Flink 的模塊.前者相當(dāng)于讓 Flink 的模塊處于 Standby 的狀態(tài).這里,我也主要介紹下前者.
在下載和解壓 Flink 的安裝包之后,需要在環(huán)境中增加環(huán)境變量 HADOOP_CONF_DIR 或者 YARN_CONF_DIR,其指向 Yarn 的配置目錄.如運(yùn)行下面的命令:
export HADOOP_CONF_DIR=/etc/hadoop/conf
這是因?yàn)?Flink 實(shí)現(xiàn)了 Yarn 的 Client,因此需要 Yarn 的一些配置和 Jar 包.在配置好環(huán)境變量后,只需簡單的運(yùn)行如下的腳本,Yarn 就會(huì)啟動(dòng) Flink 的 JobManager 和 TaskManager.
yarn-session.sh –d –s 2 –tm 800 –n 2
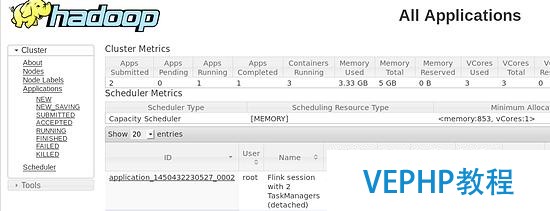
上面的命令的意思是,向 Yarn 申請(qǐng) 2 個(gè) Container 啟動(dòng) TaskManager(-n 2),每個(gè) TaskManager 擁有兩個(gè) Task Slot(-s 2),并且向每個(gè) TaskManager 的 Container 申請(qǐng) 800M 的內(nèi)存.在上面的命令成功后,我們就可以在 Yarn Application 頁面看到 Flink 的紀(jì)錄.如下圖.
圖 7. Flink on Yarn
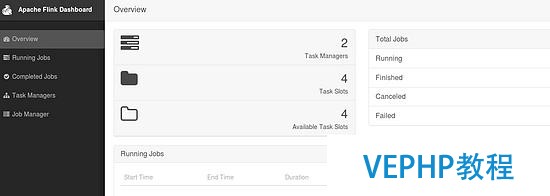
如果有些讀者在虛擬機(jī)中測試,可能會(huì)遇到錯(cuò)誤.這里需要注意內(nèi)存的大小,Flink 向 Yarn 會(huì)申請(qǐng)多個(gè) Container,但是 Yarn 的配置可能限制了 Container 所能申請(qǐng)的內(nèi)存大小,甚至 Yarn 自己所管理的內(nèi)存就很小.這樣很可能無法正常啟動(dòng) TaskManager,尤其當(dāng)指定多個(gè) TaskManager 的時(shí)候.因此,在啟動(dòng) Flink 之后,需要去 Flink 的頁面中檢查下 Flink 的狀態(tài).這里可以從 RM 的頁面中,直接跳轉(zhuǎn)(點(diǎn)擊 Tracking UI).這時(shí)候 Flink 的頁面如圖 8.
圖 8. Flink 的頁面
對(duì)于 Flink 安裝時(shí)的 Trouble-shooting,可能更多時(shí)候需要查看 Yarn 相關(guān)的 log 來分析.這里就不多做介紹,讀者可以到 Yarn 相關(guān)的描述中查找.
回頁首
Flink 的 HA
對(duì)于一個(gè)企業(yè)級(jí)的應(yīng)用,穩(wěn)定性是首要要考慮的問題,然后才是性能,因此 HA 機(jī)制是必不可少的.另外,對(duì)于已經(jīng)了解 Flink 架構(gòu)的讀者,可能會(huì)更擔(dān)心 Flink 架構(gòu)背后的單點(diǎn)問題.和 Hadoop 一代一樣,從架構(gòu)中我們可以很明顯的發(fā)現(xiàn) JobManager 有明顯的單點(diǎn)問題(SPOF,single point of failure). JobManager 肩負(fù)著任務(wù)調(diào)度以及資源分配,一旦 JobManager 出現(xiàn)意外,其后果可想而知.Flink 對(duì) JobManager HA 的處理方式,原理上基本和 Hadoop 一樣(一代和二代).
首先,我們需要知道 Flink 有兩種部署的模式,分別是 Standalone 以及 Yarn Cluster 模式.對(duì)于 Standalone 來說,Flink 必須依賴于 Zookeeper 來實(shí)現(xiàn) JobManager 的 HA(Zookeeper 已經(jīng)成為了大部分開源框架 HA 必不可少的模塊).在 Zookeeper 的贊助下,一個(gè) Standalone 的 Flink 集群會(huì)同時(shí)有多個(gè)活著的 JobManager,其中只有一個(gè)處于工作狀態(tài),其他處于 Standby 狀態(tài).當(dāng)工作中的 JobManager 失去連接后(如宕機(jī)或 Crash),Zookeeper 會(huì)從 Standby 中選舉新的 JobManager 來接管 Flink 集群.
對(duì)于 Yarn Cluaster 模式來說,Flink 就要依靠 Yarn 自己來對(duì) JobManager 做 HA 了.其實(shí)這里完全是 Yarn 的機(jī)制.對(duì)于 Yarn Cluster 模式來說,JobManager 和 TaskManager 都是被 Yarn 啟動(dòng)在 Yarn 的 Container 中.此時(shí)的 JobManager,其實(shí)應(yīng)該稱之為 Flink Application Master.也就說它的故障恢復(fù),就完全依靠著 Yarn 中的 ResourceManager(和 MapReduce 的 AppMaster 一樣).由于完全依賴了 Yarn,因此不同版本的 Yarn 可能會(huì)有細(xì)微的差異.這里不再做深究.
回頁首
Flink 的 Rest API 介紹
Flink 和其他大多開源的框架一樣,提供了很多有用的 Rest API.不過 Flink 的 RestAPI,目前還不是很強(qiáng)大,只能支持一些 Monitor 的功能.Flink Dashboard 自己也是通過其 Rest 來查詢各項(xiàng)的結(jié)果數(shù)據(jù).在 Flink RestAPI 基礎(chǔ)上,可以比較容易的將 Flink 的 Monitor 功能和其他第三方工具相集成,這也是其設(shè)計(jì)的初衷.
在 Flink 的進(jìn)程中,是由 JobManager 來提供 Rest API 的服務(wù).因此在調(diào)用 Rest 之前,要確定 JobManager 是否處于正常的狀態(tài).正常情況下,在發(fā)送一個(gè) Rest 哀求給 JobManager 之后,Client 就會(huì)收到一個(gè) JSON 格式的返回結(jié)果.由于目前 Rest 提供的功能還不多,需要增強(qiáng)這塊功能的讀者可以在子項(xiàng)目 flink-runtime-web 中找到對(duì)應(yīng)的代碼.其中最關(guān)鍵一個(gè)類 WebRuntimeMonitor,就是用來對(duì)所有的 Rest 哀求做分流的,如果需要添加一個(gè)新類型的哀求,就需要在這里增加對(duì)應(yīng)的處理代碼.下面我例舉幾個(gè)常用 Rest API.
1.查詢 Flink 集群的基本信息: /overview.示例命令行格式以及返回結(jié)果如下:
$ curl http://localhost:8081/overview{"taskmanagers":1,"slots-total":16,
"slots-available":16,"jobs-running":0,"jobs-finished":0,"jobs-cancelled":0,"jobs-failed":0}
2.查詢當(dāng)前 Flink 集群中的 Job 信息:/jobs.示例命令行格式以及返回結(jié)果如下:
$ curl http://localhost:8081/jobs{"jobs-running":,"jobs-finished":
["f91d4dd4fdf99313d849c9c4d29f8977"],"jobs-cancelled":,"jobs-failed":}
3.查詢一個(gè)指定的 Job 信息: /jobs/jobid.這個(gè)查詢的結(jié)果會(huì)返回特別多的詳細(xì)的內(nèi)容,這是我在瀏覽器中進(jìn)行的測試,如下圖:
圖 9. Rest 查詢具體的 Job 信息
想要了解更多 Rest 哀求內(nèi)容的讀者,可以去 Apache Flink 的頁面中查找.由于篇幅有限,這里就不一一列舉.
回頁首
運(yùn)行 Flink 的 Workload
WordCount 的例子,就像是計(jì)算框架的 helloworld.這里我就以 WordCount 為例,介紹下如安在 Flink 中運(yùn)行 workload.
在安裝好 Flink 的環(huán)境中,找到 Flink 的目錄.然后找到 bin/flink,它就是用來提交 Flink workload 的工具.對(duì)于 WordCount,我們可以直接使用已有的示例 jar 包.如運(yùn)行如下的命令:
./bin/flink run ./examples/WordCount.jar hdfs://user/root/test hdfs://user/root/out
上面的命令是在 HDFS 中運(yùn)行 WordCount,如果沒有 HDFS 用本地的文件系統(tǒng)也是可以的,只需要將“hdfs://”換成“file://”.這里我們需要強(qiáng)調(diào)一種部署關(guān)系,就是 StandAlone 模式的 Flink,也是可以直接拜訪 HDFS 等分布式文件系統(tǒng)的.
回頁首
結(jié)束語
Flink 是一個(gè)比 Spark 起步晚的項(xiàng)目,但是并不代表 Flink 的前途就會(huì)暗淡.Flink 和 Spark 有很多類似之處,但也有很多明顯的差異.本文并沒有比擬這兩者之間的差異,這是未來我想與大家探討的.例如 Flink 如何更高效的管理內(nèi)存,如何進(jìn)一步的避免用戶程序的 OOM.在 Flink 的世界里一切都是流,它更專注處理流應(yīng)用.由于其起步晚,加上社區(qū)的活躍度并沒有 Spark 那么熱,所以其在一些細(xì)節(jié)的場景支持上,并沒有 Spark 那么完善.例如目前在 SQL 的支持上并沒有 Spark 那么平滑.在企業(yè)級(jí)應(yīng)用中,Spark 已經(jīng)開始落地,而 Flink 可能還需要一段時(shí)間的打磨.在后續(xù)文章中,我會(huì)詳細(xì)介紹如何開發(fā) Flink 的程序,以及更多有關(guān) Flink 內(nèi)部實(shí)現(xiàn)的內(nèi)容.
轉(zhuǎn)載請(qǐng)注明本頁網(wǎng)址:
http://www.snjht.com/jiaocheng/11773.html
同類教程排行
- apache常用配置指令說明
- Hive實(shí)戰(zhàn)—通過指定經(jīng)緯度點(diǎn)找出周圍的
- Apache2.2之httpd.conf
- apache怎么做rewrite運(yùn)行th
- 獨(dú)家|一文讀懂Apache Kudu
- Apache 崩潰解決 -- 修改堆棧大
- Apache 個(gè)人主頁搭建
- Apache OpenWhisk架構(gòu)概述
- 深入理解Apache Flink核心技術(shù)
- Apache自動(dòng)跳轉(zhuǎn)到 HTTPS
- Apache Kylin查詢性能優(yōu)化
- Apache Flink異軍突起受歡迎!
- Apache Flume 大數(shù)據(jù)ETL工
- Apache MADlib成功晉升為Ap
- apache常見錯(cuò)誤代碼
