Apache Spark大數據分析入門(一)
《Apache Spark大數據分析入門(一)》要點:
本文介紹了Apache Spark大數據分析入門(一),希望對您有用。如果有疑問,可以聯系我們。
相關主題:apache配置
Apache Spark的出現讓普通人也具備了大數據及實時數據分析能力.鑒于此,本文通過動手實戰操作演示帶領大家快速地入門學習Spark.本文是Apache Spark入門系列教程(共四部門)的第一部門.
全文共包含四個部分:
- 第一部分:Spark入門,介紹如何使用Shell及RDDs
- 第二部分:介紹Spark SQL、Dataframes及如何結合Spark與Cassandra一起使用
- 第三部分:介紹Spark MLlib和Spark Streaming
- 第四部分:介紹Spark Graphx圖計算
本篇講解的就是第一部分
關于全部摘要和提綱部分,請登錄我們的網站 Apache Spark QuickStart for real-time data-analytics進行拜訪.
Spark 概述
Apache Spark是一個正在快速成長的開源集群計算系統,正在快速的成長.Apache Spark生態系統中的包和框架日益豐富,使得Spark能夠進行高級數據分析.Apache Spark的快速成功得益于它的強大功能和易于使用性.相比于傳統的MapReduce大數據分析,Spark效率更高、運行時速度更快.Apache Spark 提供了內存中的分布式計算能力,具有Java、 Scala、Python、R四種編程語言的API編程接口.Spark生態系統如下圖所示:
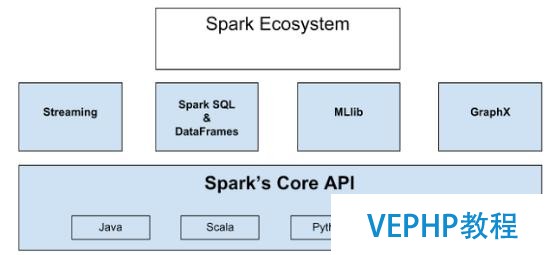
整個生態系統構建在Spark內核引擎之上,內核使得Spark具備快速的內存計算能力,也使得其API支持Java、Scala,、Python、R四種編程語言.Streaming具備實時流數據的處理能力.Spark SQL使得用戶使用他們最擅長的語言查詢結構化數據,DataFrame位于Spark SQL的核心,DataFrame將數據保留為行的集合,對應行中的各列都被命名,通過使用DataFrame,可以非常方便地查詢、繪制和過濾數據.MLlib為Spark中的機器學習框架.Graphx為圖計算框架,提供結構化數據的圖計算能力.以上便是整個生態系統的概況.
Apache Spark的發展歷史
- 最初由加州伯克利大學(UC Berkeley) AMP lab實驗室開發并于2010年開源,目前已經成為阿帕奇軟件基金會(Apache Software Foundation)的頂級項目.
- 已經有12,500次代碼提交,這些提交來自630個源碼貢獻者(參見 Apache Spark Github repo)
- 大部分代碼使用 Scala語言編寫.
- Apache Spark的Google興趣搜索量( Google search interests)最近呈井噴式的增長,這表明其關注度之高(Google廣告詞工具顯示:僅七月就有多達108,000次搜索,比Microservices的搜索量多十倍)
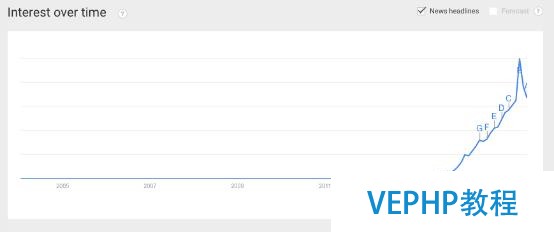
- 部分Spark的源碼貢獻者(distributors)分別來自IBM、Oracle、DataStax、BlueData、Cloudera……
- 構建在Spark上的應用包含:Qlik、Talen、Tresata、atscale、platfora……
- 使用Spark的公司有: VerizonVerizon、NBC、Yahoo、Spotify……
大家對Apache Spark如此感興趣的原因是它使得普通的開發具備Hadoop的數據處理能力.較之于Hadoop,Spark的集群配置比Hadoop集群的配置更簡單,運行速度更快且更容易編程.Spark使得大多數的開發人員具備了大數據和實時數據分析能力.鑒于此,鑒于此,本文通過動手實戰操作演示帶領大家快速地入門學習Apache Spark.
下載Spark并河演示如何使用交互式Shell命令行
動手實驗Apache Spark的最好方式是使用交互式Shell命令行,Spark目前有Python Shell和Scala Shell兩種交互式命令行.
可以從 這里下載Apache Spark,下載時選擇最近預編譯好的版本以便能夠立即運行shell.
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
運行Python Shell
cd spark-1.5.0-bin-hadoop2.4./bin/pyspark
在本節中不會使用Python Shell進行演示.
Scala交互式命令行由于運行在JVM上,能夠使用java庫.
運行Scala Shell
cd spark-1.5.0-bin-hadoop2.4./bin/spark-shell
執行完上述命令行,你可以看到下列輸出:
Scala Shell歡迎信息
Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 1.5.0 /_/Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_25)Type in expressions to have them evaluated.Type :help for more information.15/08/24 21:58:29 INFO SparkContext: Running Spark version 1.5.0
下面是一些簡單的練習以便贊助使用shell.也許你現在不能理解我們做的是什么,但在后面我們會對此進行詳細分析.在Scala Shell中,執行下列操作:
在Spark中使用README 文件創建textFileRDD
val textFile = sc.textFile("README.md")獲取textFile RDD的第一個元素
textFile.firstres3: String = # Apache Spark
對textFile RDD中的數據進行過濾操作,返回所有包括“Spark”關鍵字的行,操作完成后會返回一個新的RDD,操作完成后可以對返回的RDD的行進行計數
篩選出包含Spark關鍵字的RDD然后進行行計數
val linesWithSpark = textFile.filter(line => line.contains("Spark"))linesWithSpark.countres10: Long = 19要找出RDD linesWithSpark單詞出現最多的行,可以使用下列操作.使用map辦法,將RDD中的各行映射成一個數,然后再使用reduce辦法找出包含單詞數最多的行.
找出RDD textFile 中包括單詞數最多的行
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)res11: Int = 14返回結果注解第14行單詞數最多.
也可以引入其它java包,例如 Math.max辦法,因為map和reduce辦法接受scala函數字面量作為參數.
在scala shell中引入Java辦法
import java.lang.MathtextFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))res12: Int = 14我們可以很容易地將數據緩存到內存當中.
將RDD linesWithSpark 緩存,然后進行行計數
linesWithSpark.cacheres13: linesWithSpark.type = MapPartitionsRDD[8] at filter at <console>:23linesWithSpark.countres15: Long = 19
上面簡要地給大家演示的了如何使用Spark交互式命令行.
彈性分布式數據集(RDDs)
Spark在集群中可以并行地執行任務,并行度由Spark中的主要組件之一——RDD決定.彈性分布式數據集(Resilient distributed data, RDD)是一種數據表現方式,RDD中的數據被分區存儲在集群中(碎片化的數據存儲方式),正是由于數據的分區存儲使得任務可以并行執行.分區數量越多,并行越高.下圖給出了RDD的表現:
想像每列均為一個分區(partition ),你可以非常便利地將分區數據分配給集群中的各個節點.
為創建RDD,可以從外部存儲中讀取數據,例如從Cassandra、Amazon簡單存儲服務(Amazon Simple Storage Service)、HDFS或其它Hadoop支持的輸入數據格式中讀取.也可以通過讀取文件、數組或JSON格式的數據來創建RDD.另一方面,如果對于應用來說,數據是本地化的,此時你僅需要使用parallelize辦法便可以將Spark的特性作用于相應數據,并通過Apache Spark集群對數據進行并行化分析.為驗證這一點,我們使用Scala Spark Shell進行演示:
通過單詞列表集合創建RDD thingsRDD
val thingsRDD = sc.parallelize(List("spoon", "fork", "plate", "cup", "bottle"))thingsRDD: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[11] at parallelize at <console>:24計算RDD thingsRDD 中單的個數
thingsRDD.countres16: Long = 5
運行Spark時,需要創建Spark Context.使用Spark Shell交互式命令行時,Spark Context會自動創建.當調用Spark Context 對象的parallelize 辦法后,我們會得到一個經過分區的RDD,這些數據將被分發到集群的各個節點上.
使用RDD我們能夠做什么?
對RDD,既可以進行數據轉換,也可以對進行action操作.這意味著使用transformation可以改變數據格式、進行數據查詢或數據過濾操作等,使用action操作,可以觸發數據的改變、抽取數據、收集數據甚至進行計數.
例如,我們可以使用Spark中的文本文件README.md創建一個RDD textFile,文件中包括了若干文本行,將該文本文件讀入RDD textFile時,其中的文本行數據將被分區以便能夠分發到集群中并被并行化操作.
根據README.md文件創建RDD textFile
val textFile = sc.textFile("README.md")行計數
textFile.countres17: Long = 98
README.md 文件中有98行數據.
得到的結果如下圖所示:
然后,我們可以將所有包括Spark關鍵字的行篩選出來,完成操作后會生成一個新的RDDlinesWithSpark:
創建一個過濾后的RDD linesWithSpark
val linesWithSpark = textFile.filter(line => line.contains("Spark"))在前一幅圖中,我們給出了 textFile RDD的表現,下面的圖為RDD linesWithSpark的表現:
值得注意的是,Spark還存在鍵值對RDD(Pair RDD),這種RDD的數據格式為鍵/值對數據(key/value paired data).例如下表中的數據,它表現水果與顏色的對應關系:
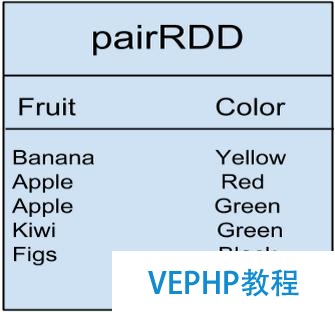
對表中的數據使用groupByKey轉換操作將得到下列結果:
groupByKey 轉換操作
pairRDD.groupByKeyBanana [Yellow]Apple [Red, Green] Kiwi [Green]Figs [Black]
該轉換操作只將鍵為Apple,值為Red和Green的數據進行了分組.這些是到目前為止給出的轉換操作例子.
當得到一個經過過濾操作后的RDD,可以collect/materialize相應的數據并使其流向應用程序,這是action操作的例子.經過此操作后, RDD中所有數據將消失,但我們仍然可以在RDD的數據上進行某些操作,因為它們仍然在內存當中.
Collect 或 materializelinesWithSpark RDD中的數據
linesWithSpark.collect
值得一提的是每次進行Spark action操作時,例如count action操作,Spark將重新啟動所有的轉換操作,計算將運行到最后一個轉換操作,然后count操作返回計算結果,這種運行方式速度會較慢.為辦理該問題和提高程序運行速度,可以將RDD的數據緩存到內存當中,這種方式的話,當你反復運行action操作時,能夠避免每次計算都從頭開始,直接從緩存到內存中的RDD得到相應的結果.
緩存RDDlinesWithSpark
linesWithSpark.cache
如果你想將RDD linesWithSpark從緩存中清除,可以使用unpersist辦法.
將linesWithSpark從內存中刪除
linesWithSpark.unpersist
如果不手動刪除的話,在內存空間緊張的情況下,Spark會采用最近最久未使用(least recently used logic,LRU)調度算法刪除緩存在內存中最久的RDD.
下面總結一下Spark從開始到結果的運行過程:
- 創建某種數據類型的RDD
- 對RDD中的數據進行轉換操作,例如過濾操作
- 在必要重用的情況下,對轉換后或過濾后的RDD進行緩存
- 在RDD上進行action操作,例如提取數據、計數、存儲數據到Cassandra等.
下面給出的是RDD的部分轉換操作清單:
- filter
- map
- sample
- union
- groupbykey
- sortbykey
- combineByKey
- subtractByKey
- mapValues
- Keys
- Values
下面給出的是RDD的部門action操作清單:
- collect
- count
- first
- countbykey
- saveAsTextFile
- reduce
- take(n)
- countBykey
- collectAsMap
- lookup(key)
關于RDD所有的操作清單和描述,可以參考 Spark documentation
結束語
本文介紹了Apache Spark,一個正在快速成長、開源的集群計算系統.我們給大家展示了部分能夠進行高級數據分析的Apache Spark庫和框架.對 Apache Spark為什么會如此成功的原因進行了簡要分析,具體表示為 Apache Spark的強大功能和易用性.給大家演示了 Apache Spark提供的內存、分布式計算環境,并演示了其易用性及易掌握性.
在本系列教程的第二部門,我們對Spark進行更深入的介紹.
歡迎參與《Apache Spark大數據分析入門(一)》討論,分享您的想法,維易PHP學院為您提供專業教程。
