基于php的爬蟲程序推薦
《基于php的爬蟲程序推薦》要點:
本文介紹了基于php的爬蟲程序推薦,希望對您有用。如果有疑問,可以聯系我們。
可能很多程序員會說:爬蟲我只認Python.小編還是覺得php是世界上最好的語言,沒有什么做不了的.

一、爬蟲框架:Beanbun
Beabbun是一個簡單可擴展的爬蟲框架,支持分布式,支持守護進程模式和普通模式,守護進程模式基于Workerman,下載器基于Guzzle.
特點:
1、支持守護進程和普通兩種模式(守護進程模式只支持Linux服務器)
2、默認使用guzzle進行爬取
3、支持分布式,內存,redis,自定義URL過濾,廣度優先和深度優先等
4、爬取網頁分為多步,每步均支持自定義動作
5、靈活的擴展機制,可方便的為框架制作插件:自定義隊列、自定義爬取方式...

二、采集工具:QueryList
QueryList是一個基于phpQuery的PHP通用列表采集類,得益于phpQuery,讓使用QueryList幾乎沒有任何學習本錢,只要會css3選擇器就可以輕松使用QueryList了,它讓PHP做采集像JQuery選擇元素一樣簡單.
特點:
1、只有一個核心的API,靜態辦法Query
2、用JQuery選擇器來選擇頁面元素
3、自帶過濾功能,可過濾掉無用內容
4、支持無限層級嵌套采集
5、支持擴展,通過擴展可以實現復雜的http操作、多線程批量采集、模擬登陸采集等功能
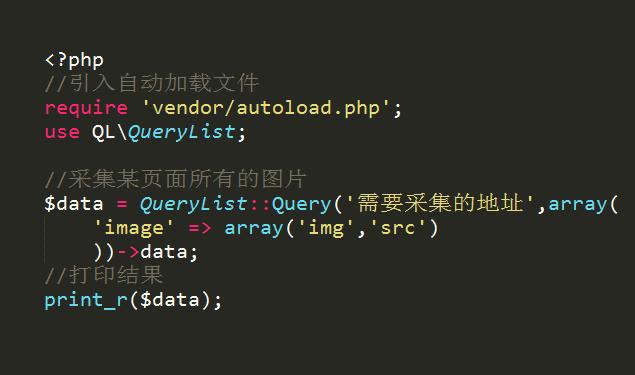
3、PHP采集類:Snoopy
Snoopy是一個PHP類,用來模擬瀏覽器的功能,可以獲取網頁內容,發送表單.
特點:
1、抓取網頁的內容:fetch;抓取網頁文本內容:fetchtext;抓取網頁的鏈接,表單:fetchlinks,fetchfrom
2、支持代理主機,支持基本的用戶名、暗碼驗證,支持設置user_agent,referer,cookies和header content
3、支持瀏覽器重定向,并能控制重定向深度
4、能把網頁中的鏈接擴展成高質量的url
5、提交數據并獲取返回值
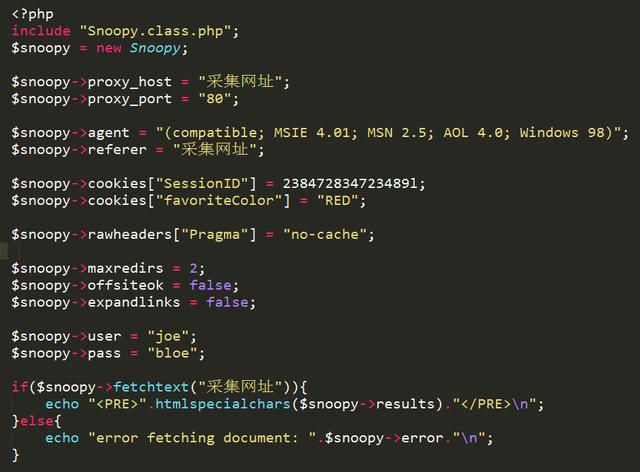
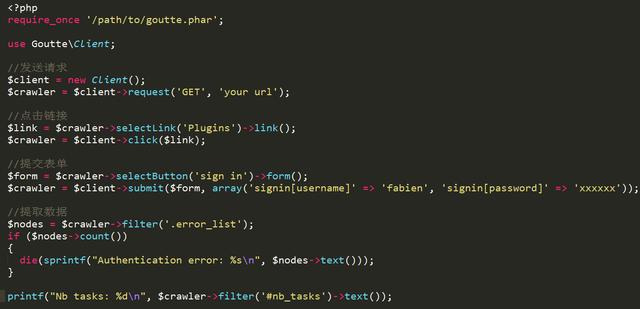
4、爬蟲庫:Goutte
Goutte是一個抓取網站數據的php庫.它提供了一個優雅的API,這使的從遠程頁面上選擇特定元素變得簡單.
其實最好用的還是適合本身的,根據本身的情況自行擴展.
《基于php的爬蟲程序推薦》是否對您有啟發,歡迎查看更多與《基于php的爬蟲程序推薦》相關教程,學精學透。維易PHP學院為您提供精彩教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9667.html
同類教程排行
- 為什么我們要用Laravel、Yii這樣
- 框架和編程語言市場份額和排名,PHP占到
- 盤點各種程序員最討厭的事情,看看你中招了
- 3分鐘快速入門php高性能框架Phalc
- 一款強大的純PHP開發的爬蟲(蜘蛛)框架
- 國產PHP框架之ThinkPHP各模塊開
- PHP框架——ThinkPHP模塊開發四
- 分享一款不錯的PHP爬蟲框架Beanbu
- 二維碼高級在線生成器站點 PHP 源碼
- Php框架之slim3.0應用小實例
- PHP框架——ThinkPHP各模塊開發
- PHP 組件及框架推薦系列:PHP世界中
- yii2框架路由配置和url美化干貨,學
- 基于php的爬蟲程序推薦
- dedecms發手機短信的源碼,做旅游網
