一款強(qiáng)大的純PHP開發(fā)的爬蟲(蜘蛛)框架,讓采集更簡單一點(diǎn)
《一款強(qiáng)大的純PHP開發(fā)的爬蟲(蜘蛛)框架,讓采集更簡單一點(diǎn)》要點(diǎn):
本文介紹了一款強(qiáng)大的純PHP開發(fā)的爬蟲(蜘蛛)框架,讓采集更簡單一點(diǎn),希望對(duì)您有用。如果有疑問,可以聯(lián)系我們。

簡單、靈活、強(qiáng)年夜的PHP爬蟲框架,讓采集更簡單一點(diǎn).
官方下載地址:https://github.com/owner888/phpspider
官方開發(fā)文檔:http://doc.phpspider.org/
編寫PHP網(wǎng)絡(luò)爬蟲, 必要具備以下技能:
爬蟲采用PHP編寫
從網(wǎng)頁中抽取數(shù)據(jù)必要用XPath
當(dāng)然我們還可以使用CSS選擇器
很多情況下都會(huì)用到正則表達(dá)式
Chrome的開發(fā)者工具是神器, 很多AJAX哀求需要用它來分析
注意:本框架只能在命令行下運(yùn)行,命令行、命令行、命令行,重要的事情說三遍 ^_^
第一個(gè)demo
爬蟲采納PHP編寫, 下面以糗事百科為例, 來看一下我們的爬蟲長什么樣子:
$configs = array(
爬蟲的整體框架便是這樣, 首先定義了一個(gè)$configs數(shù)組, 里面設(shè)置了待爬網(wǎng)站的一些信息, 然后通過調(diào)用$spider = new phpspider($configs);和$spider->start();來配置并啟動(dòng)爬蟲.
運(yùn)行界面如下:
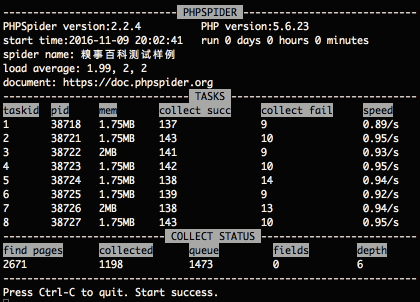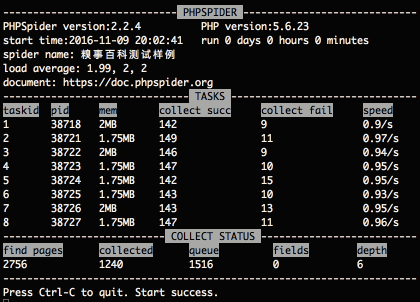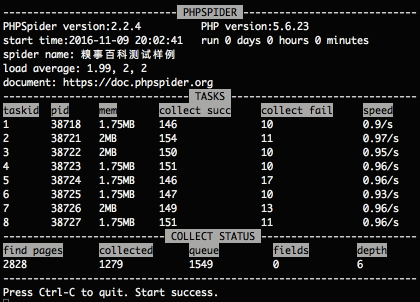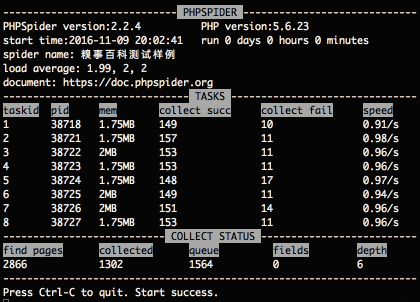
$configs對(duì)象如何界說, 請(qǐng)查看開發(fā)文檔.^_^
歡迎參與《一款強(qiáng)大的純PHP開發(fā)的爬蟲(蜘蛛)框架,讓采集更簡單一點(diǎn)》討論,分享您的想法,維易PHP學(xué)院為您提供專業(yè)教程。
轉(zhuǎn)載請(qǐng)注明本頁網(wǎng)址:
http://www.snjht.com/jiaocheng/9108.html
同類教程排行
- 為什么我們要用Laravel、Yii這樣
- 框架和編程語言市場(chǎng)份額和排名,PHP占到
- 盤點(diǎn)各種程序員最討厭的事情,看看你中招了
- 3分鐘快速入門php高性能框架Phalc
- 一款強(qiáng)大的純PHP開發(fā)的爬蟲(蜘蛛)框架
- 國產(chǎn)PHP框架之ThinkPHP各模塊開
- PHP框架——ThinkPHP模塊開發(fā)四
- 分享一款不錯(cuò)的PHP爬蟲框架Beanbu
- 二維碼高級(jí)在線生成器站點(diǎn) PHP 源碼
- Php框架之slim3.0應(yīng)用小實(shí)例
- PHP框架——ThinkPHP各模塊開發(fā)
- PHP 組件及框架推薦系列:PHP世界中
- yii2框架路由配置和url美化干貨,學(xué)
- 基于php的爬蟲程序推薦
- dedecms發(fā)手機(jī)短信的源碼,做旅游網(wǎng)
