NoSQL數據庫的主主備份
《NoSQL數據庫的主主備份》要點:
本文介紹了NoSQL數據庫的主主備份,希望對您有用。如果有疑問,可以聯系我們。
作者 | Dennis Anikin
翻譯 | 賀雨言
Tarantool DBMS的高性能應該很多人都聽說過,包含其豐富的工具套件和某些特定功能.比如,它擁有一個非常強大的on-disk存儲引擎Vinyl,并且知道怎樣處理JSON文檔.然而,大部分文章往往忽略了一個關鍵點:通常,Tarantool僅僅被視為存儲器,而實際上其最大特點是能夠在存儲器內部寫代碼,從而高效處理數據.如果你想知道我和igorcoding是怎樣在Tarantool內部建立一個系統的,請繼續往下看.
如果你用過Mail.Ru電子郵件服務,你應該知道它可以從其他賬號收集郵件.如果支持OAuth協議,那么在收集其他賬號的郵件時,我們就不必要讓用戶提供第三方服務憑證了,而是用OAuth令牌來代替.此外,Mail.Ru Group有很多項目要求通過第三方服務授權,并且必要用戶的OAuth令牌才能處理某些應用.因此,我們決定建立一個存儲和更新令牌的服務.
我猜大家都知道OAuth令牌是什么樣的,閉上眼睛回憶一下,OAuth結構由以下3-4個字段組成:

拜訪令牌(access_token)——允許你執行動作、獲取用戶數據、下載用戶的好友列表等等;
更新令牌(refresh_token)——讓你重新獲取新的access_token,不限次數;
過期時間(expires_in)——令牌到期時間戳或任何其他預定義時間,如果你的access_token到期了,你就不能繼續拜訪所需的資源.
現在我們看一下服務的簡單框架.設想有一些前端可以在我們的服務上寫入和讀出令牌,還有一個獨立的更新器,一旦令牌到期,就可以通過更新器從OAuth服務提供商獲取新的拜訪令牌.
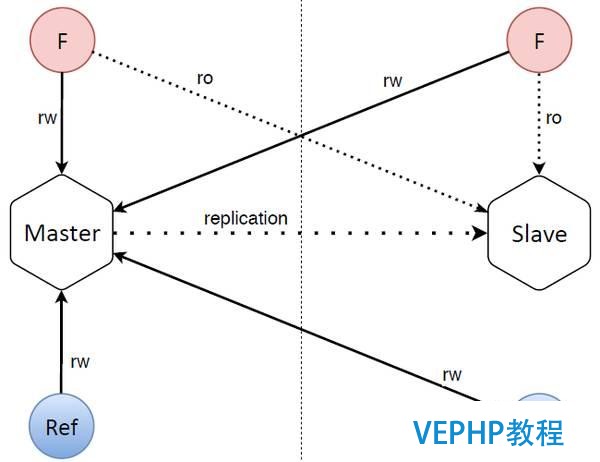
如上圖所示,數據庫的結構也十分簡單,由兩個數據庫節點(主和從)組成,為了說明兩個數據庫節點分別位于兩個數據中心,二者之間由一條垂直的虛線隔開,其中一個數據中心包含主數據庫節點及其前端和更新器,另一個數據中心包含從數據庫節點及其前端,以及拜訪主數據庫節點的更新器.
面臨的困難
我們面臨的主要問題在于令牌的使用期(一個小時).詳細了解這個項目之后,也許有人會問“在一小時內更新1000萬條記錄,這真的是高負載服務嗎?如果我們用一個數除一下,結果大約是3000rps”.然而,如果因為數據庫維護或故障,甚至服務器故障(一切皆有可能)導致一部分記錄沒有得到更新,那事情將會變得比擬麻煩.比如,如果我們的服務(主數據庫)因為某些原因持續中斷15分鐘,就會導致25%的服務中斷(四分之一的令牌變成無效,不能再繼續使用);如果服務中斷30分鐘,將會有一半的數據不能得到更新;如果中斷1小時,那么所有的令牌都將失效.假設數據庫癱瘓一個小時,我們重啟系統,然后整個1000萬條令牌都需要進行快速更新.這算不算高負載服務呢?
一開始一切都還進展地比擬順利,但是兩年后,我們進行了邏輯擴展,增加了幾個指標,并且開始執行一些輔助邏輯…….總之,Tarantool耗盡了CPU資源.盡管所有資源都是遞耗資源,但這樣的結果確實讓我們大吃一驚.
幸運的是,系統管理員幫我們安裝了當時庫存中內存最大的CPU,解決了我們隨后6個月的CPU需求.但這只是權宜之計,我們必須想出一個解決方法.當時,我們學習了一個新版的Tarantool(我們的系統是用Tarantool 1.5寫的,這個版本除了在Mail.Ru Group,其他地方基本沒用過).Tarantool 1.6大力提倡主主備份,于是我們想:為什么不在連接主主備份的三個數據中心分別建立一個數據庫備份呢?這聽起來是個不錯的計劃.
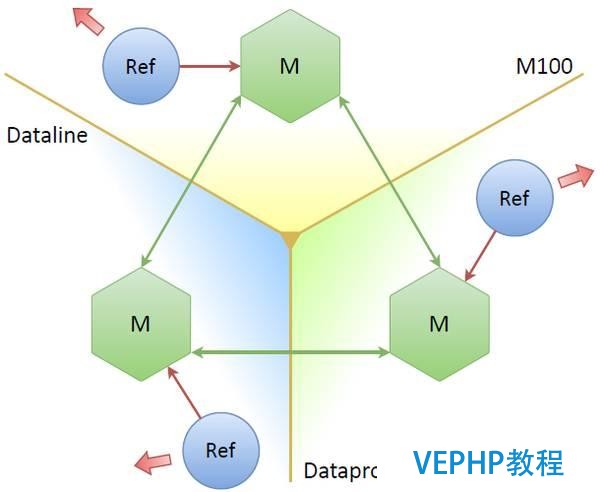
三個主機、三個數據中心和三個更新器,都分別連接自己的主數據庫.即使一個或者兩個主機癱瘓了,系統仍然照常運行,對吧?那么這個方案的缺點是什么呢?缺點就是,我們將一個OAuth服務提供商的哀求數量有效地增加到了三倍,也就是說,有多少個副本,我們就要更新幾乎相同數量的令牌,這樣不行.最直接的解決辦法就是,想辦法讓各個節點自己決定誰是leader,那樣就只需要更新存儲在leader上的節點了.
選擇leader節點
選擇leader節點的算法有很多,其中有一個算法叫Paxos,相當復雜,不知道怎樣簡化,于是我們決定用Raft代替.Raft是一個非常通俗易懂的算法,誰能通信就選誰做leader,一旦通信連接失敗或者其他因素,就重新選leader.具體實施方法如下:
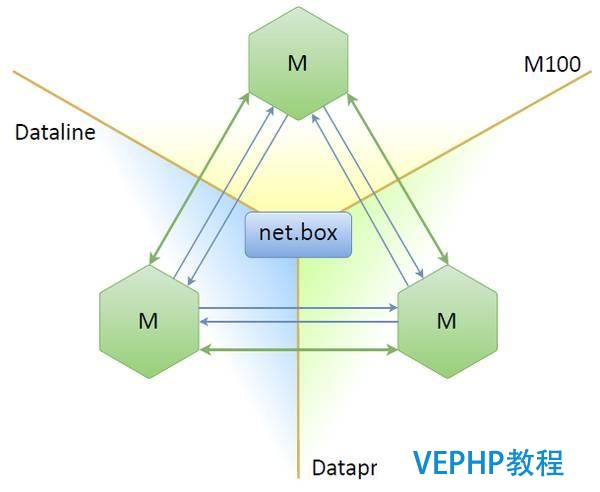
Tarantool外部既沒有Raft也沒有Paxos,但是我們可以使用net.box內置模式,讓所有節點連接成一個網狀網(即每一個節點連接剩下所有節點),然后直接在這些連接上用Raft算法選出leader節點.最后,所有節點要么成為leader節點,要么成為follower節點,或者二者都不是.
如果你覺得Raft算法實施起來有困難,下面的Lua代碼可以幫到你:

現在我們給遠程服務器發送哀求(其他Tarantool副本)并計算來自每一個節點的票數,如果我們有一個quorum,我們就選定了一個leader,然后發送heartbeats,告訴其他節點我們還活著.如果我們在選舉中失敗了,我們可以發起另一場選舉,一段時間之后,我們又可以投票或被選為leader.
只要我們有一個quorum,選中一個leader,我們就可以將更新器指派給所有節點,但是只準它們為leader服務.
這樣我們就規范了流量,由于任務是由單一的節點派出,因此每一個更新器獲得大約三分之一的任務,有了這樣的設置,我們可以失去任何一臺主機,因為如果某臺主機出故障了,我們可以發起另一個選舉,更新器也可以切換到另一個節點.然而,和其他分布式系統一樣,有好幾個問題與quorum有關.
“廢棄”節點
如果各個數據中心之間失去聯系了,那么我們必要有一些適當的機制去維持整個系統正常運轉,還必要有一套機制能恢復系統的完整性.Raft成功地做到了這兩點:
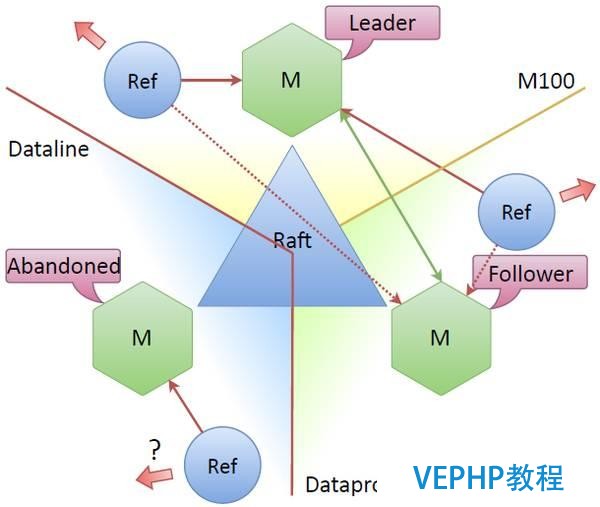
假設Dataline數據中心掉線了,那么該位置的節點就變成了“廢棄”節點,也就是說該節點就看不到其他節點了,集群中的其他節點可以看到這個節點丟失了,于是引發了另一個選舉,然后新的集群節點(即上級節點)被選為leader,整個系統仍然堅持運轉,因為各個節點之間仍然堅持一致性(大半部分節點仍然互相可見).
那么問題來了,與丟失的數據中心有關的更新器怎么樣了呢?Raft說明書沒有給這樣的節點一個單獨的名字,通常,沒有quorum的節點和不能與leader聯系的節點會被閑置下來.然而,它可以本身建立網絡連接然后更新令牌,一般來說,令牌都是在連接模式時更新,但是,也許用一個連接“廢棄”節點的更新器也可以更新令牌.一開始我們并不確定這樣做有意義,這樣不會導致冗余更新嗎?
這個問題我們必要在實施系統的過程中搞清楚.我們的第一個想法是不更新:我們有一致性、有quorum,丟失任何一個成員,我們都不應該更新.但是后來我們有了另一個想法,我們看一下Tarantool中的主主備份,假設有兩個主節點和一個變量(key)X=1,我們同時在每一個節點上給這個變量賦一個新值,一個賦值為2,另一個賦值為3,然后,兩個節點互相交換備份日志(就是X變量的值).在一致性上,這樣實施主主備份是很糟糕的(無意冒犯Tarantool開發者).
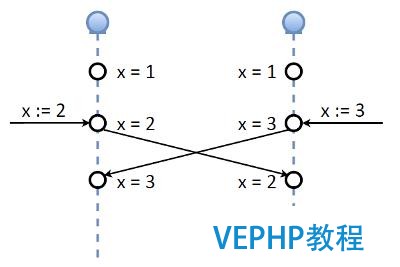
如果我們必要嚴格的一致性,這樣是行不通的.然而,回憶一下我們的OAuth令牌是由以下兩個重要因素組成:
更新令牌,本色上永久有效;
拜訪令牌,有效期為一個小時;
我們的更新器有一個refresh函數,可以從一個更新令牌獲取任意數量的拜訪令牌,一旦發布,它們都將保持一個小時內有效.
我們考慮一下以下場景:兩個follower節點正在和一個leader節點交互,它們更新自己的令牌,接收第一個拜訪令牌,這個拜訪令牌被復制,于是現在每一個節點都有這個拜訪令牌,然后,連接中斷了,所以,其中一個follower節點變成了“廢棄”節點,它沒有quorum,既看不到leader也看不到其他follower,然而,我們允許我們的更新器去更新位于“廢棄”節點上的令牌,如果“廢棄”節點沒有連接網絡,那么整個方案都將停止運行.盡管如此,如果發生簡單的網絡拆分,更新器還是可以維持正常運行.
一旦網絡拆分結束,“廢棄”節點重新加入集群,就會引發另一場選舉或者數據交換.注意,第二和第三個令牌一樣,也是“好的”.
原始的集群成員恢復之后,下一次更新將只在一個節點上發生,然后備份.換句話來說,當集群拆分之后,被拆分的各個部分各自獨立更新,但是一旦重新整合,數據一致性也因此恢復.通常,需要N/2+1個活動節點(對于一個3節點集群,就是需要2個活動節點)去保持集群正常運轉.盡管如此,對我們而言,即使只有1個活動節點也足夠了,它會發送盡可能多的外部哀求.
重申一下,我們已經討論了哀求數量逐漸增加的情況,在網絡拆分或節點中斷時期,我們能夠提供一個單一的活動節點,我們會像平時一樣更新這個節點,如果出現絕對拆分(即當一個集群被分成最大數量的節點,每一個節點有一個網絡連接),如上所述,OAuth服務提供商的哀求數量將提升至三倍.但是,由于這個事件發生的時間相對短暫,所以情況不是太糟,我們可不希望一直工作在拆分模式.通常情況下,系統處于有quorum和網絡連接,并且所有節點都啟動運行的狀態.
分片
還有一個問題沒有解決:我們已經達到了CPU上限,最直接的解決方法就是分片.
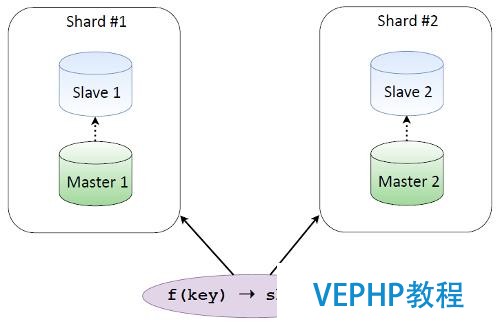
假設我們有兩個數據庫分片,每一個都有備份,有一個這樣的函數,給定一些key值,就可以計算出哪一個分片上有所必要的數據.如果我們通過電子郵件分片,一部分地址存儲在一個分片上,另一部分地址存儲在另一個分片上,我們很清楚我們的數據在哪里.
有兩種辦法可以分片.一種是客戶端分片,我們選擇一個返回分片數量的連續的分片函數,比如CRC32、Guava或Sumbur,這個函數在所有客戶端的實現方式都一樣.這種辦法的一個明顯優勢在于數據庫對分片一無所知,你的數據庫正常運轉,然后分片就發生了.
然而,這種辦法也存在一個很嚴重的缺陷.一開始,客戶端非常繁忙.如果你想要一個新的分片,你需要把分片邏輯加進客戶端,這里的最大的問題是,可能一些客戶端在使用這種模式,而另一些客戶端卻在使用另一種完全不同的模式,而數據庫本身卻不知道有兩種不同的分片模式.
我們選擇另一種辦法—數據庫內部分片,這種情況下,數據庫代碼變得更加復雜,但是為了折中我們可以使用簡單的客戶端,每一個連接數據庫的客戶端被路由到任意節點,由一個特殊函數計算出哪一個節點應該被連接、哪一個節點應該被控制.前面提到,由于數據庫變得更加復雜,因此為了折中,客戶端就變得更加簡單了,但是這樣的話,數據庫就要對其數據全權負責.此外,最困難的事就是重新分片,如果你有一大堆客戶端無法更新,相比之下,如果數據庫負責管理自己的數據,那重新分片就會變得非常簡單.
具體怎樣實施呢?
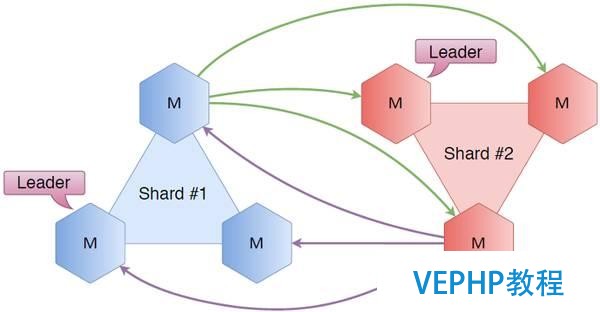
六邊形代表Tarantool實體,有3個節點組成分片1,另一個3節點集群作為分片2,如果我們將所有節點互相連接,結果會怎樣呢?根據Raft,我們可以知道每一個集群的狀態,誰是leader服務器誰是follower服務器也一目了然,由于是集群內連接,我們還可以知道其他分片(例如它的leader分片或者follower分片)的狀態.總的來說,如果拜訪第一個分片的用戶發現這并不是他需要的分片,我們很清楚地知道應該指導他往哪里走.
我們來看一些簡單的例子:
假設用戶向駐留在第一個分片上的key發出哀求,該哀求被第一個分片上的某一個節點接收,這個節點知道誰是leader,于是將哀求重新路由到分片leader,反過來,分片leader對這個key進行讀或寫,并且將結果反饋給用戶.
第二個場景:用戶的哀求到達第一個分片中的相同節點,但是被哀求的key卻在第二個分片上,這種情況也可以用類似的方法處理,第一個分片知道第二個分片上誰是leader,然后把哀求送到第二個分片的leader進行轉發和處理,再將結果返回給用戶.
這個方案十分簡單,但也存在必定的缺陷,其中最大的問題就是連接數,在二分片的例子中,每一個節點連接到其他剩下的節點,連接數是6*5=30,如果再加一個3節點分片,那么連接數就增加到72,這會不會有點多呢?
我們該如何解決這個問題呢?我們只需要增加一些Tarantool實例,我們叫它代理,而不叫分片或數據庫,用代理去解決所有的分片問題:包括計算key值和定位分片領導.另一方面,Raft集群保持自包含,只在分片內部工作.當用戶拜訪代理時,代理計算出所需要的分片,如果需要的是leader,就對用戶作相應的重定向,如果不是leader,就將用戶重定向至分片內的任意節點.
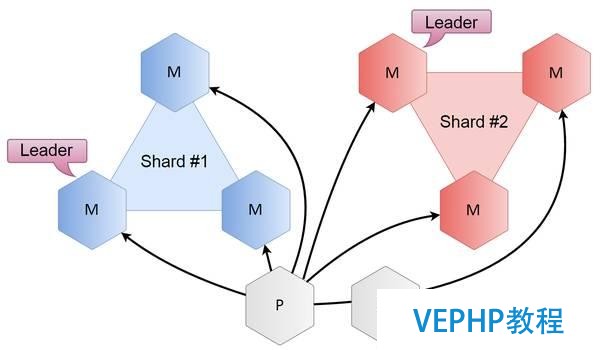
由此產生的復雜性是線性的,取決于節點數量.現在一共3個節點,每個節點3個分片,連接數少了幾倍.
代理方案的設計考慮到了進一步規模擴展(當分片數量大于2時),當只有2個分片時,連接數不變,但是當分片數量增加時,連接數會劇減.分片列表存儲在Lua配置文件中,所以,如果想要獲取新列表,我們只必要重載代碼就好了.
綜上所述,首先,我們進行主主備份,應用Raft算法,然后加入分片和代理,最后我們得到的是一個單塊,一個集群,所以說,目前這個方案看上去是比擬簡單的.
剩下的就是只讀或只寫令牌的的前端了,我們有更新器可以更新令牌,獲得更新令牌后把它傳到OAuth服務提供商,然后寫一個新的拜訪令牌.
前面說過我們的一些輔助邏輯耗盡了CPU資源,現在我們將這些輔助資源移到另一個集群上.
輔助邏輯主要和地址簿有關,給定一個用戶令牌,就會有一個對應的地址簿,地址簿上的數據量和令牌一樣,為了不耗盡一臺機器上的CPU資源,我們顯然需要一個與副原形同的集群,只需要加一堆更新地址簿的更新器就可以了(這個任務比較少見,因此地址簿不會和令牌一起更新).
最后,通過整合這兩個集群,我們得到一個相對簡單的完整結構:
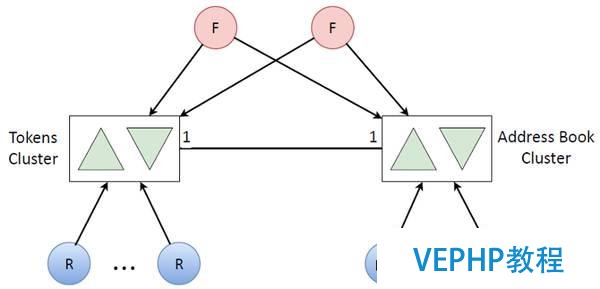
令牌更新隊列
為什么我們本可以使用標準隊列卻還要用本身的隊列呢?這和我們的令牌更新模型有關.令牌一旦發布,有效期就是一個小時,當令牌快要到期時,需要進行更新,而令牌更新必須在某個特定的時間點之前完成.
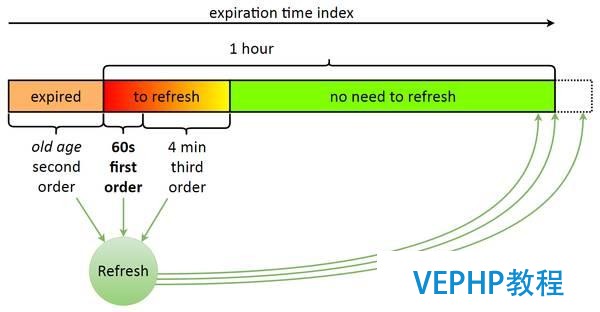
假設系統中斷了,但是我們有一堆已到期的令牌,而在我們更新這些令牌的同時,又有其他令牌陸續到期,雖然我們最后肯定能全部更新完,但是如果我們先更新那些即將到期的(60秒內),再用剩下的資源去更新已經到期的,是不是會更合理一些?(優先級別最低的是還有4-5分鐘才到期的令牌)
用第三方軟件來實現這個邏輯并不是件容易的事,然而,對于Tarantool來說卻不費吹灰之力.看一個簡單的方案:在Tarantool中有一個存儲數據的元組,這個元組的一些ID設置了基礎key值,為了得到我們必要的隊列,我們只必要添加兩個字段:status(隊列令牌狀態)和time(到期時間或其他預定義時間).
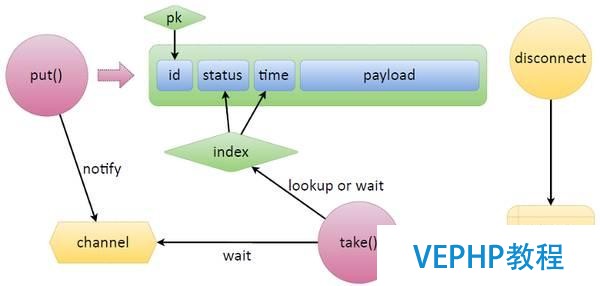
現在我們考慮一下隊列的兩個主要功能—put和take.put就是寫入新數據.給定一些負載,put時本身設置好status和time,然后寫數據,這就是建立一個新的元組.
至于take,是指建立一個基于索引的迭代器,挑出那些等待辦理的任務(處于就緒狀態的任務),然后核查一下是不是該接收這些任務了,或者這些任務是否已經到期了.如果沒有任務,take就切換到wait模式.除了內置Lua,Tarantool還有一些所謂的通道,這些通道本質上是互聯光纖同步原語.任何光纖都可以建立一個通道然后說“我在這等著”,剩下的其他光纖可以喚醒這個通道然后給它發送信息.
等待中的函數(等待發布任務、等待指定時間或其他)建立一個通道,給通道貼上適當的標簽,將通道放置在某個地方,然后進行監聽.如果我們收到一個緊急的更新令牌,put會給通道發出通知,然后take接收更新任務.
Tarantool有一個特殊的功能:如果一個令牌被意外發布,或者一個更新令牌被take接收,或者只是出現接收任務的現象,以上三種情況Tarantool都可以跟蹤到客戶端中斷.我們將每一個連接與指定給該連接的任務聯系起來,并將這些映射關系堅持在會話保存中.假設由于網絡中斷導致更新過程失敗,而且我們不知道這個令牌是否會被更新并被寫回到數據庫.于是,客戶端發生中斷了,搜索與失敗過程相關的所有任務的會話保存,然后自動將它們釋放.隨后,任意已發布的任務都可以用同一個通道給另一個put發送信息,該put會快速接收和執行任務.
實際上,具體實施方案并不必要太多代碼:

Put只是接收用戶想要插入隊列的所有數據,并將其寫入某個空間,如果是一個簡單的索引式FIFO隊列,設置好狀態和當前時間,然后返回該任務.
接下來要和take有點關系了,但仍然比擬簡單.我們建立一個迭代器,等待接收新任務.Taken函數只需要將任務標記成“已接收”,但有一點很重要,taken函數還能記住哪個任務是由哪個進程接收的.On_disconnect函數可以發布某個特定連接,或者發布由某個特定用戶接收的所有任務.
是否有可選方案
當然有.我們本可以使用任意數據庫,但是,不管我們選用什么數據庫,我們都要建立一個隊列用來處理外部系統、處理更新等等問題.我們不能僅僅按需更新令牌,因為那樣會產生不可預估的工作量,不管怎樣,我們需要堅持我們的系統充滿活力,但是那樣,我們就要將延期的任務也插入隊列,并且保證數據庫和隊列之間的一致性,我們還要被迫使用一個quorum的容錯隊列.此外,如果我們把數據同時放在RAM和一個(考慮到工作量)可能要放入內存的隊列中,那么我們就要消耗更多資源.
在我們的方案中,數據庫存儲令牌,隊列邏輯只必要占用7個字節(每個元組只必要7個額外的字節,就可以搞定隊列邏輯!),如果使用其他的隊列形式,必要占用的空間就多得多了,大概是內存容量的兩倍.
總結
首先,我們解決了連接中斷的問題,這個問題十分常見,使用上述的系統讓我們解脫了這個困擾.
分片贊助我們擴展內存,然后,我們將連接數從二次方減少到了線性,優化了業務任務的隊列邏輯:如果發生延期,更新我們所能更新的一切令牌,這些延期并非都是我們的故障引起的,有可能是Google、Microsoft或者其他服務端對OAuth服務提供商進行改造,然后導致我們這邊出現大量的未更新的令牌.
去數據庫內部運算吧,走近數據,你將擁有方便、高效、可擴展和靈活的運算體驗!
《NoSQL數據庫的主主備份》是否對您有啟發,歡迎查看更多與《NoSQL數據庫的主主備份》相關教程,學精學透。維易PHP學院為您提供精彩教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9594.html
同類教程排行
- 大數據學習——你知道Apache Cas
- 一張圖理清NoSQL、MPP和Hadoo
- 新思潮:NoSQL與DPDK、RDMA等
- CockroachDB 1.1發布 平均
- NoSQL的基本概念和分類比較 Redi
- 細數5款主流NoSQL數據庫到底哪家強?
- mongodb nosql 如何實現分頁
- mongodb NOSQL 各種查詢條件
- 解析SQL與NoSQL的融合架構產品GB
- NoSQL數據庫的分布式算法
- 2017年度全球“大數據企業50強”
- 騰訊十多個人管理一萬多臺NoSQL存儲服
- 如何學習及選擇大數據非關系型數據庫NoS
- SQL和NOSQL有區別嗎?
- No-SQL數據庫為什么能適應分布式數據
