解析SQL與NoSQL的融合架構產品GBase UP
《解析SQL與NoSQL的融合架構產品GBase UP》要點:
本文介紹了解析SQL與NoSQL的融合架構產品GBase UP,希望對您有用。如果有疑問,可以聯系我們。
[來自IT168]
【IT168 專稿】本文根據【DTCC2016中國數據庫技術大會】現場演講嘉賓武新博士分享內容整理而成.錄音整理及筆墨編輯IT168@楊璐
講師簡介

武新博士
武新,博士,現任南大通用高級副總裁兼CTO.
第五批“國家千人計劃” 專家,2010年獲得中組部實施的國家“千人計劃”榮譽(海外高層次人才引進計劃);曾作為資深數據庫專家,在甲骨文公司(法國)任職11年;曾是法國 EKIP 軟件公司的技術負責人、法國電信軟件開發工程師.
武新博士自加入南大通用以來,主導設計和研發了GBase 8a 列存儲數據庫, GBase 8a MPP Cluster大規模并行數據庫集群等一系列產品.
正文
大家上午好,我是南大通用的CTO武新,非常高興也非常榮幸的代表公司來給大家報告請示一下我們下午即將發布的一款新產品,這里我提前把產品的一些細節分享給大家.
要發布的產品是面向企業和行業的用戶,我們認為是一款行業和企業用戶真正必要的大數據平臺產品.它的名字叫GBase UP,UP是Unified Platform,我們希望能把關系型數據庫和NoSQL的一些子系統和技術融合在一個產品里面.
我的報告請示大概分成四部分

行業IT面臨的一些痛點和問題
經過幾十年的發展,我們其實已經建立了很多很成熟的業務系統和應用系統.這些業務系統的建設其實過去一直是以事務型的方式在建設,也就是說,首先要滿足我們的業務需求,這種業務系統往往是以傳統數據庫,以交易型為主,其數據強調自身的、局部的完整性和一致性.
這就對我們本日的數據分析產生了一個矛盾的地方.因為每個業務系統只有我們這個企業的一部分數據,我們的數據分析需要的是在全局數據里面挖掘出信息.從大數據角度來說,我們認為可能是一個全視角的需求.
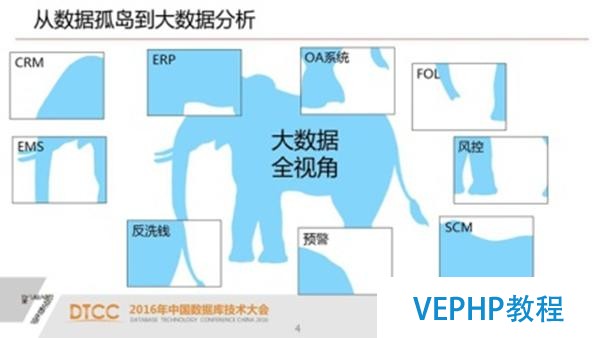
那么怎么把數據孤島打通,匯總在一起,真正在上面進行我們全視角的大數據分析,其實這是一個我們現在的業務系統和大數據分析的一個矛盾.
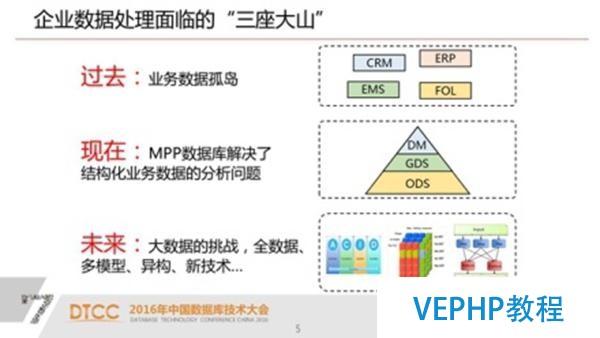
三座大山:1.我們過去建立了很多數據孤島,這些數據孤島我們還繼續在建設,因為我們的業務系統在企業里面基本上是按具體業務去設計,去應用的,他很少考慮全視角的建設;我們做這個數據分析的時候,我們就需要把這些數據孤島打通.過去一個辦法是做數據倉庫,已將近二十年歷史了.在做數據倉庫的時候常常面臨的性能問題,跟傳統數據庫的體系架構還是有關系的.
2.用新一代基于MPP架構的數據庫產品,我們其實辦理了大型數據倉庫的效率問題和規模問題.這樣我們可以把我們一些業務系統的數據真正匯總在一個平臺上進行全視角的分析.3.未來,其實未來也就是現在,面臨著大數據的挑戰,我們認為大數據不僅僅是關系型數據庫產生的數據,不僅僅是當前業務產生的數據,還有其他來源的數據.這些數據和我們的業務數據怎么進行關聯,這些數據可能需要不同的模型來處理,還有一些異構的技術,包括一些新的技術也層出不窮.其實這些都是我們企業今天面臨的挑戰.
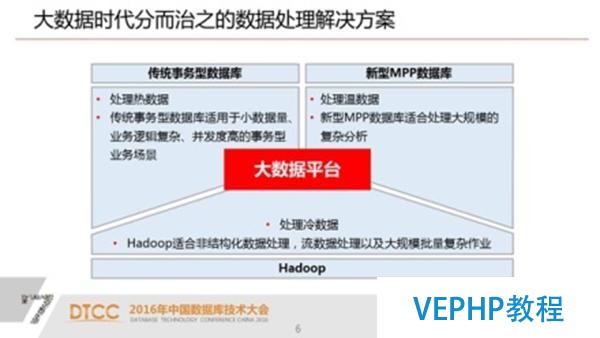
大數據時代分而治之的數據處理辦理方案
1. 傳統的事務型數據庫,這一類數據庫已非常成熟,也是目前在企業里交易系統最核心的數據庫產品.
2. 新型的MPP數據庫產品,是基于大規模并行計算和橫向擴展的架構這樣一類數據庫產品.
3. hadoop,hadoop長處是有些關系型數據庫辦理不了或者是處理不了的一些問題他能處理.
既然這三種技術之間目前還沒有一種技術能完全替代其他的技術,那么對大數據平臺的需求自然就是這三種技術融合在一起,這是我們的一個想法,也是我們針對這樣一個想法實現了我們這個產品.
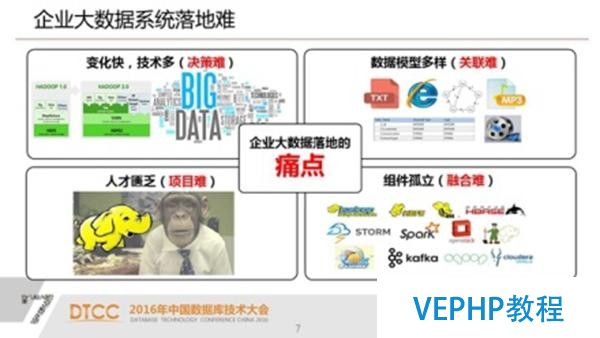
企業大數據系統落地難
1. 大數據的技術變化非常快,對于企業來說,必要一個穩定的平臺和技術支持生產系統.
2. 在大數據的視角下必要結構化數據和一些半結構化數據甚至非結構化數據提取出來進行各種各樣的關聯.
3. 越來越多的組件導致運維很困難.
4. 對于普通企業用戶來說,還有一個問題就是系統開發和技術支持方面的人才匱乏.
農業銀行與浙江移動大數據平臺案例
這是一個混搭的架構,左邊是農行主要核心業務系統,大概有兩百多個.那么這些核心業務系統都屬于一些孤島式的業務系統,他每個業務系統只是企業數據的一部分,通過我們現在這個MPP的平臺來把這些所有的數據匯總在一起,放在一個平臺上,建立ODS,然后進行一層一層的匯總,辦理了業務數據數據孤島的問題.
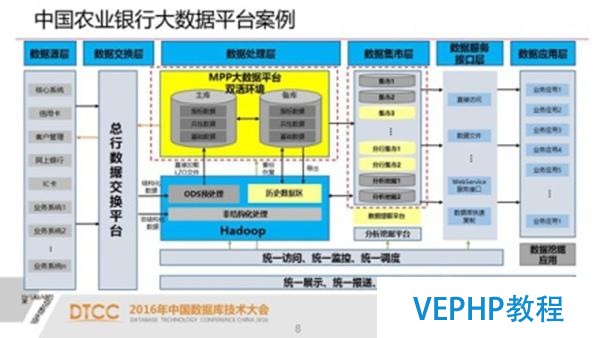
這個案例也用MPP數據庫替代了整個傳統的關系型數據庫,有多個集群,有三到四個MPP數據庫集群.從二十多個結點到三四十個結點這樣一個規模.
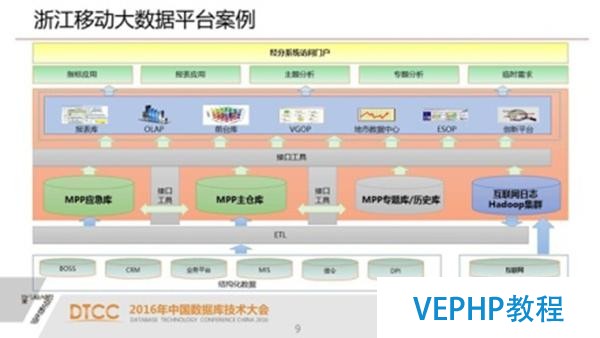
通過UP實現能進一步的降低hadoop和關系型數據庫之間融合應用的復雜度,給用戶帶來真正的價值.
IBM大數據平臺辦理方案展示
大家在把一些數據庫的引擎,包含SQL層嫁接到hadoop上來,主要是嫁接到HDFS上面來.但是缺點大于優點,一是效率問題,一是對事務的支撐能力較弱.第三是處理數據的密度.目前從MPP數據庫的角度來說,一個結點已經能夠管理一百TB的有效數據了.在用HDFS上架SQL這一層,現在他的密度還是遠遠低于這樣一個MPP數據庫的密度.
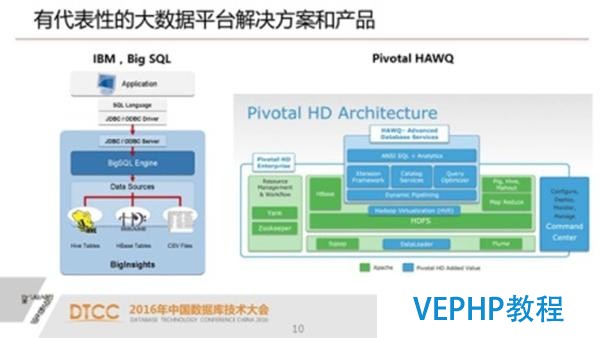
對于用戶價值更大一點的是SQL和hadoop,我們把這個成熟的關系型數據庫跟hadoop的生態融合在一個平臺上,這是我們UP設計的整體思想.
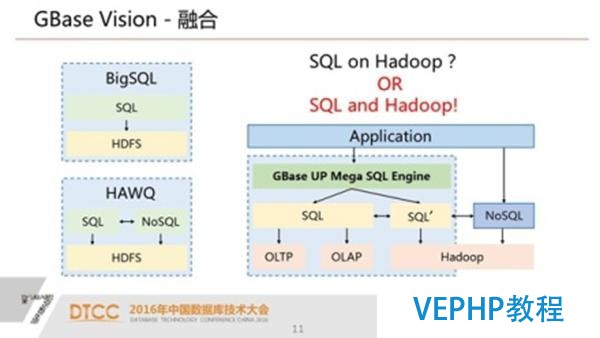
這樣大家用SQL來處理數據會越來越豐富,其實我們豐富了關系型數據庫,擴展他的疆域和能力,同時又可以利用hadoop的一些優點來達到大數據的處理效果,這是整體的設計思路.

GBase UP的整體架構和細節介紹
在企業開發應用,還是要用不同的產品.從應用的角度、從開發的角度來說,建立引擎之間的存儲和計算通道,是一個難題.
1.UP首先通過融合來簡化用戶的開發和使用.在幾個異構的引擎之間,上層包含統一的API和分布式調度、執行的統一SQL層,中間是異構的一些引擎,底層是數據通信總線.我們的統一SQL層,除了支持傳統的SOL數據庫意外,還對其他方面進行了擴展.
2.在UP層元數據的統一.
3.平臺的擴展能力,一個是數據交換.我們實現了透明的引擎之間的數據關聯和交換;第二是實現全數據的管理,除了結構化數據以外,為半結構化,非結構化數據統一的視角下進行管理;最后是擴展,通過靈活的UDF機制,對平臺提供擴展功能.
4.數據生命周期管理實現透明和自動.我們看技術架構:

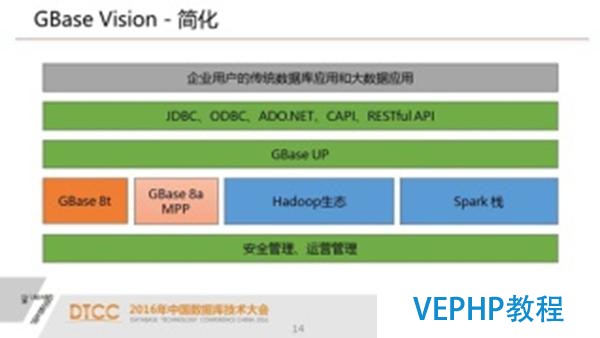
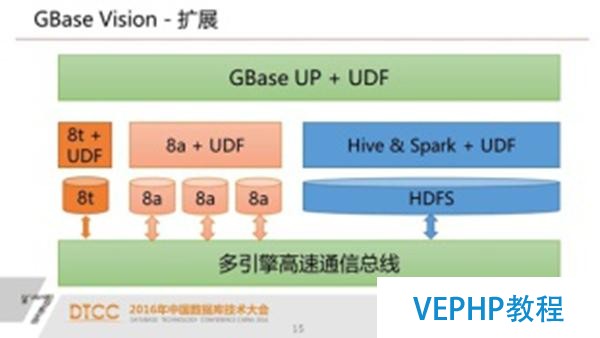
這不是一個簡單的路由器或者中間件,這是一個真正的類似MPP風格的分布式數據庫.我們上層是一個驅動層,解析從應用過來是SQL,包含標準的SQL和hadoop生態的方言.我們有DDL執行器,我們有DQL和DML優化機和執行器.最底層針對不同的引擎以插件的方式插入到我們這個平臺里面來,這樣的好處就是我們未來還可以很容易的擴展到其他引擎上面去.
GBase UP應用場景及案例分享
很多DBA對SQL比擬熟悉,因此這里用SOL來表達UP的一些能力.先來看看應用場景部分:
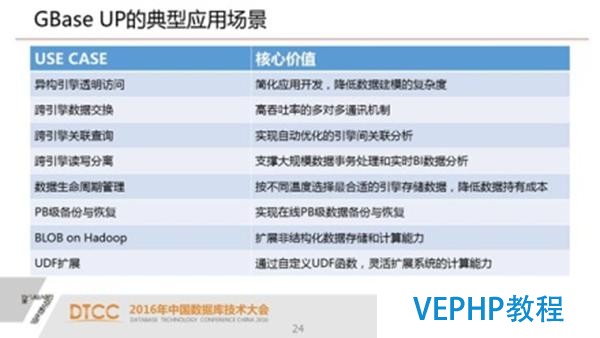
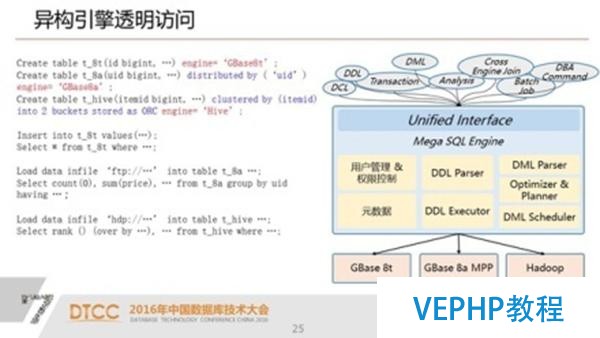
1.異構引擎透明拜訪 簡化應用開發,降低數據建模的復雜度
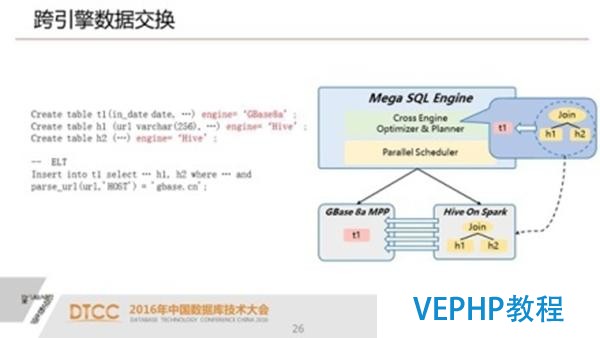
2.跨引擎數據交換 高吞吐率的多對多通訊機制
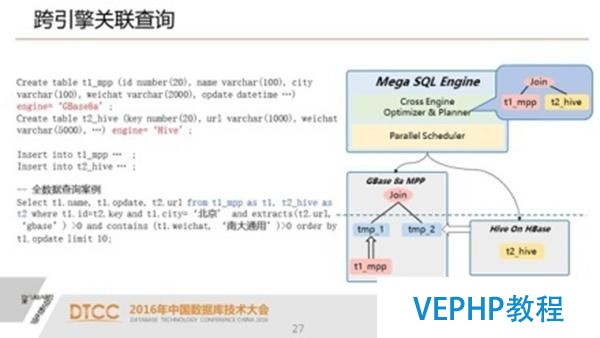
3.跨引擎關聯查詢 實現自動優化的引擎間關聯分析
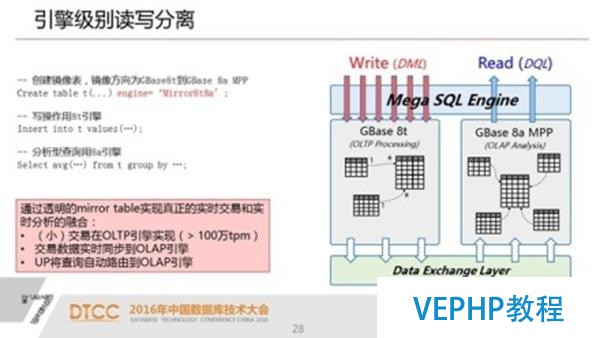
4.跨引擎讀寫分離 支撐大規模數據事務處理和實時BI數據分析
5.數據生命周期管理 跨引擎分區表 按不同溫度選擇最合適的引擎存儲數據 降低數據持有本錢

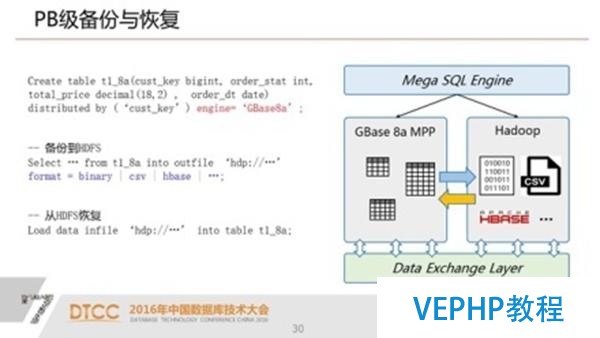
6.PB級備份與恢復 實現在線PB級數據備份與恢復
7.BLOB on Hadoop擴展非結構化數據存儲和計算能力
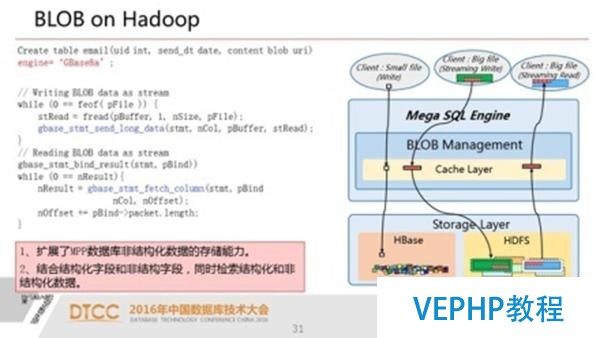
8.UDF擴展 通過自定義UDF函數 靈活擴展系統的計算能力
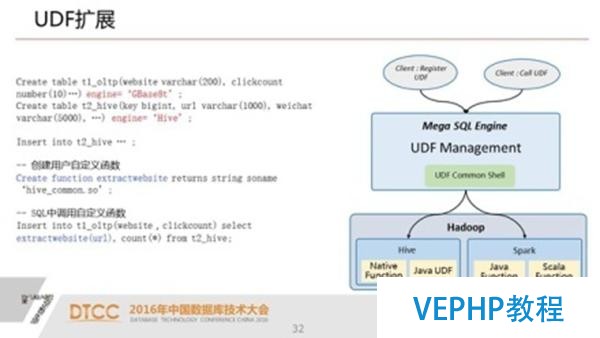
有了UP以后,我們在建表的時候,我們對SQL進行拓展.建這個表的過程中,他的META DATA(元數據)被我們的UP給存儲、管理起來了.對用戶來說就完成了,那么剩下的,無論是你做DML操作、數據的加載,還是查詢這都變成了完全透明.
案例分享
下面幾個案例我們就是建了表了以后,我們通過上層的應用就可以很透明的穿透了UP去拜訪不同的引擎,然后我們可以進行數據的加載.
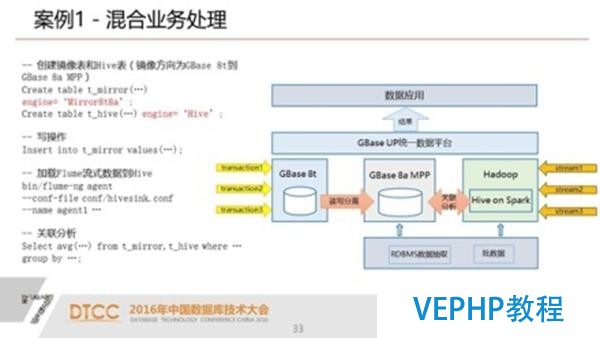
有了這樣的一個元數據之后,我們可以很容易的實現跨引擎的數據交換,當然,這種跨引擎數據交換目前沒有我們的UP也能做,用戶主要是通過ETL,通過復雜調度程序,好比說在hadoop里面先做一些預處理,把計算的結果導入數據倉庫里面去.
另外一個就是跨引擎的關聯查詢,因為我們建完表以后,用戶來說就是透明.例如:我們有一個關聯,這個關聯是在Spark上有兩個表,還有一個表是在數據倉庫MPP里面,這三個表之間進行了一個關聯.那么在這個關聯的過程中我們可以看一下,我們的執行計劃是在兩個集群上進行的并行計算,一個是在hadoop集群上進行計算.同時在MPP上也進行計算,當然兩者又都是并行計算.這樣我們大大的提升了整個集群的處理的效率.
關于實現跨引擎級別的讀寫分離,在很多的應用場景,不必定需要事務和讀的強一致性.
我們的事務操作要保證他的一致性,而在分析業務里面去讀剛放產生的數據,而在很多應用里頭,兩者是可以分開的.我們通過一種叫鏡像表的模式,就是同時在OLTP和OLAP兩個引擎里面建立,實現一個實時同步的機制.
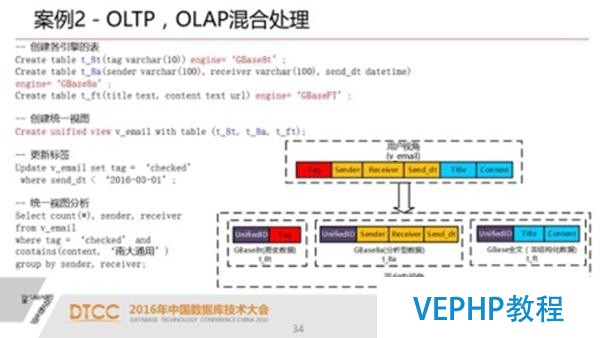
這就意味著我可以支撐非常高效的DML操作.這樣就可以實現比如說實時的高效交易處理和數據分析并存的業務場景.我們通過本身搭積木的方式也能實現這樣一個機制,但是從應用角度來說還是非常難的一件事情.
最后一點是UDF的擴展,我們知道在hadoop上,我們很容易擴展一些算法.而且這些算法在關系型數據庫里面其實很難實現,效率也不高,這點我們通過UP的擴展,也就是說我們在hadoop上面可以用任何語言寫一個函數.好比說寫一個算法,在我們的UP上進行注冊,那么我們這個函數和算法就可以用SQL來進行調用了,這樣大大擴展了我們關系型數據庫處理能力.
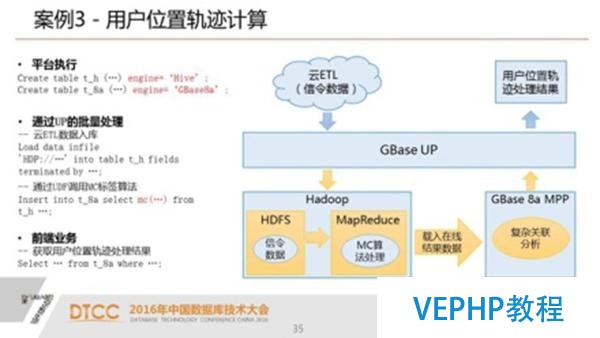
總結
關系型數據庫仍然是最成熟,處理數據效率最高的系統,是我們核心業務的支撐平臺.在可見的未來我相信這個也不會很快的改變.

另外SQL也作為應用使用最廣泛的數據處理語言,所以我們也看到了,除了關系型數據庫的SQL在繼續豐富外,我們現在把它拓展到hadoop的生態里面去了.
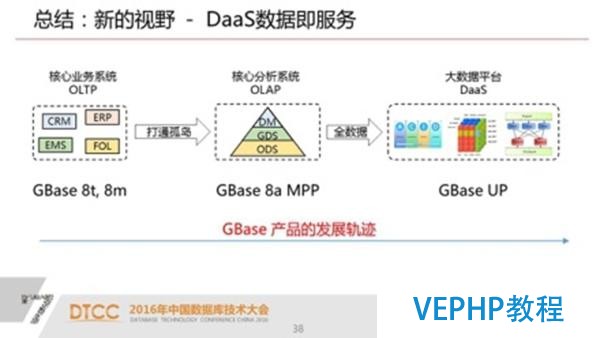
無論是什么類型的數據,包含一些非結構化的數據,我們把他的一些特征提取出來,就是常說的轉非.這些特征數據和其他的一些數據進行關聯分析也是最容易的,這也的確是我們面對的現狀.
最后一點就是大數據的處理就要滿足高效的數據采集和存儲,這跟事務是有關系的.同時要滿足全視角的數據分析,成熟的融合是大數據平臺的一個核心.從GBase角度來說我們希望最終給用戶提供完整的視角,其實用戶不必要關心用什么樣的技術去存儲和管理數據.用戶必要的是能不能高效存取,然后數據能有完整性和一致性,最終進行高效的各種各樣的關聯分析,這也是GBase UP這個產品要給用戶帶來的最終價值.
《解析SQL與NoSQL的融合架構產品GBase UP》是否對您有啟發,歡迎查看更多與《解析SQL與NoSQL的融合架構產品GBase UP》相關教程,學精學透。維易PHP學院為您提供精彩教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9588.html
同類教程排行
- 大數據學習——你知道Apache Cas
- 一張圖理清NoSQL、MPP和Hadoo
- 新思潮:NoSQL與DPDK、RDMA等
- CockroachDB 1.1發布 平均
- NoSQL的基本概念和分類比較 Redi
- 細數5款主流NoSQL數據庫到底哪家強?
- mongodb nosql 如何實現分頁
- mongodb NOSQL 各種查詢條件
- 解析SQL與NoSQL的融合架構產品GB
- NoSQL數據庫的分布式算法
- 2017年度全球“大數據企業50強”
- 騰訊十多個人管理一萬多臺NoSQL存儲服
- 如何學習及選擇大數據非關系型數據庫NoS
- SQL和NOSQL有區別嗎?
- No-SQL數據庫為什么能適應分布式數據
