NoSQL對未來大數據發展的意義何在?
《NoSQL對未來大數據發展的意義何在?》要點:
本文介紹了NoSQL對未來大數據發展的意義何在?,希望對您有用。如果有疑問,可以聯系我們。
為了幫助IT從業者職業之路擁有更多收獲,在諸多C粉的殷切期待下,由CTO俱樂部打造的CTO線上講堂自登場以來獲得大家好評.本期邀請SequoiaDB巨杉數據庫聯合創始人王濤帶來“NoSQL對未來大數據發展的意義安在?”的創業主題分享.
想與業界大咖零距離溝通,歡迎參加CTO講堂微信群(8月13日,新一期講堂報名請拖至文末查看)

演講嘉賓:SequoiaDB巨杉數據庫聯合創始人 王濤
嘉賓簡介:王濤,SequoiaDB巨杉數據庫聯合創始人,他曾就職于IBM多倫多實驗室IBM TorontoLab(DB2 UDB Development Lab), 曾經是DB2領域的專家,作為IBM DB2全球最高技術專家小組的成員,參與IBM下一代大數據平臺的架構規劃,精通數據庫內核及體系結構.在IBM多倫多實驗室工作八年后,王濤選擇回國創業.目前擔任巨杉數據庫CTO及總架構師,成功研發了國內唯一一款開源新一代分布式數據庫——SequoiaDB(巨杉數據庫).作為公司創始人之一,王濤參與公司發展戰略規劃,負責整個數據庫研發項目的管理,包含數據庫系統的構建,管理公司的整體核心技術,組織制定和實施重大技術決策和技術方案等.目前,公司產品已經開源,客戶遍布互聯網、金融、電信等各大行業.
公司簡介:巨杉數據庫作為國內唯一一家完全不基于其他任何開源數據庫產品開發的新型商業數據庫,專注于新型NoSQL分布式數據庫的研發,核心軟件產品SequoiaDB(巨杉數據庫)(未使用任何開源數據庫引擎和代碼),由前IBM DB2資深研發成員在北美完成原型設計和內核開發.主要向政府、電信、金融、電力和互聯網等擁有海量業務數據的行業提供大數據基礎數據庫,主要客戶中已有多家世界500強企業,其中包含國內知名銀行、電信及互聯網企業.
以下是8月6日CTO講堂現場完整速記:
主持人:本日講堂開始了,首先歡迎王總介紹下自己.
王濤:大家好,我叫王濤,現在是SequoiaDB巨杉數據庫的創始人兼CTO :)我之前在北美的IBM DB2 Lab工作了很多年, 也是DB2核心的研發團隊的一員.
我們從2011年開始就在北美做數據庫的原型,到了2012年,我就帶著團隊回國創業,也便是創立了SequoiaDB巨杉數據庫.我們SequoiaDB是2012年正式成立的,并沒有基于其他的開源數據庫引擎.目前,我們SequoiaDB已經發布了8個正式版本,也成為了海內外業界一致認可的一款新型分布式數據庫產品,產品客戶也遍布互聯網、金融、電信等各大行業.
主持人:您是在什么樣情況下開始的創業之路呢?
王濤:IBM的近十年工作時間,我對整個數據庫技術和行業有了比較深刻的認識.而在IBM這樣的大公司當中,創新的阻力不只是來自于外部,公司內部對于顛覆性的創新也有很多阻礙.為了做出一款顛覆性的創新產品,我們還是決定本身創業,做本身的事業.
主持人:最初的創業方向選擇方面是怎么構想的?為什么選擇做國內第一款開源的NoSQL?
王濤:對于創業方向,一直以來因為也是在數據庫開發的前沿,所以其實對行業和技術看得也比擬清楚.當時2011年大數據這個概念在北美那邊已經成體系了,而NoSQL也就是非關系型的數據庫技術,前幾年興起的新型數據庫技術,目前在北美已經得到了廣泛的應用.比如MongoDB Cassandra這些大家都是耳熟能詳了.
可是在國內,使用這些新型數據庫的企業、個人仍不多,更別說做相關開發的了.所以基于我們團隊的技術實力、再結合國內巨大的市場,我們決定做國內第一款開源的新型分布式數據庫.
主持人:請您談談國表里數據庫技術的目前格局以及市場情況.
王濤:在國外,新型分布式數據庫已經大大沖擊了傳統數據庫的市場,不管是互聯網企業應用還是企業大數據應用,在數據庫排行幫上MongoDB等幾款新型分布式數據庫早已躋身前十.
相比來說,國內對NoSQL這樣的新型數據庫應用仍處在發展期,但是隨著如今“國產化”進程的加快,國產的、開源的新型數據庫市場在近期已經呈現了飛速發展的趨勢.而巨杉數據庫也是目前這一市場當仁不讓的領導者.
主持人:那么您認為NoSQL技術對于未來大數據發展的意義體現在哪?
王濤:NoSQL靈活的存儲結構,根本上辦理了多樣化、非結構化數據存儲的問題.同時,分布式則辦理了數據容量的問題,同時大大降低了成本.可以說,NoSQL技術就是為了未來的大數據發展而生的.
好比說作為歷史數據平臺,很多企業都開始把過去存在帶庫里面的數據搬到大數據平臺上面.這樣的話數據不同時期可能隨著應用的升級,數據結構產生了變化.怎樣對于這些變化的數據有很好的管理和檢索方式,這就是新型數據庫擅長的地方.
主持人:請介紹一下巨杉數據庫目前的情況以及團隊構成.
王濤:經過近3年的發展,我們現在已經擁有了一支強大的研發團隊.團隊包含IBM DB2北美實驗室資深核心研發成員,甲骨文、華為等公司的數據庫架構師,還有騰訊、阿里巴巴等互聯網公司的數據庫開發工程師.
其實除了經驗豐富,更重要的是團隊成員們都對技術有著最大的熱情,這也是我們團隊最名貴的財富.
主持人:可否用一些具體案例來詳細介紹一下公司產品呢?
王濤:具體案例比擬多,比如在一些大型金融機構里面,大家在做大數據項目的時候第一個要做的就是對歷史數據從帶庫上面的搬遷,把原本不能用的數據用起來.這類系統可以衍生出回單查詢,用戶畫像等一系列對歷史數據分析和實時應用類型的案例出來.
另一大類型則是非結構化存儲,也就是替代傳統ECM企業內容管理軟件的.比如本來EMC的Documentum或者IBM的Filenet.
其他的還有一些dynamic schema的場景,和大數據Hadoop自己不一定相關,比如人口檔案庫,征信,產業鏈平臺等很難事先定義數據模型的場景.
主持人:我們來展開談談SDB的架構和存儲模式吧.
王濤:我們采取了文檔型的存儲模式,也便是JSON文檔的存儲方式.JSON的自描述特性,使得數據存儲既實現了非結構化的存儲,相比于KV等等結構,又更能體現數據的細節,更符合人類操作的思維.
另一個大的優勢就是存儲的數據對于輸入來說是自適應的.比如說傳統關系型數據庫一定要定義一個表模型才能放數據.每一條數據必須和表的定義一模一樣.但是在很多新興的應用中,事先定義一個完美的模型很難,所以數據庫自己對輸入數據的自適應非常重要.
從數據庫架構來看,SDB目前的架構使用的是典型的MPP架構,編目節點存儲元數據,協調節點負責分布式系統的任務分發,數據節點負責數據存儲和操作.數據節點可以動態的擴容.架構圖如下:
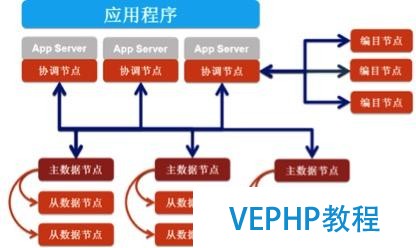
主持人:SDB有哪些突出的功能點呢?
王濤:我就直接列幾點吧:
- 1)靈活存儲布局;
- 2)容量水平擴張;
- 3)高可用特性(備份、讀寫分離、異地容災);
- 4)Spark/Hadoop深度集成(國內第一款深度集成Spark的數據庫);
- 5)事務功能、SQL語句執行、豐富的圖形化工具等等.
主持人:目前SDB的應用狀況是怎樣的呢?
王濤:目前SDB的應用覆蓋了多個行業,作為一款通用的大數據產品,SequoiaDB在大數據需求旺盛的傳統行業應用廣泛.包含中國銀行、民生銀行、中國移動、電信還有政府都得到大規模應用.在互聯網行業,也有途牛、多盟、藍港在線等企業在使用SequoiaDB.
主持人:那么巨杉選擇開源之路,收效如何?
王濤:現在我們是完全開源的產品,得到業界廣泛的認可.除了企業用戶的選擇,巨杉也獲得了中國開源軟件推進聯盟(COPU)發表的“2015年度優秀開源項目”獎.
同時,開源之后,我們也產生了一大批的個人用戶和技術“粉絲” :)目前我們的開源社區十分活躍,也有許多的資深開發者給我們開發了多種驅動和插件, python、C#驅動還有docker鏡像等等.近期我們nodejs驅動很快也會正式發布,這個也是由社區的朋友主導,我們從旁邊配合的. :)
主持人:下一階段公司的戰略中心和發展規劃會聚焦在哪些方面呢?
王濤:下一步,我們希望能在國內繼續推進新型分布式數據庫的影響力,讓廣大的開發者能更容易的運用“大數據”,辦理更多的問題.
此外,我們也會不斷的將我們本身的數據庫產品越做越好,也希望大家能多多關注巨杉.
主持人:請介紹一下巨杉是怎樣的工作氛圍和工作模式呢?
王濤:我們是一個年輕并充滿活力的大家庭,工作氛圍很自由開放,大家都會為了問題展開熱烈的討論.最重要的,是團隊成員們都對技術有著最大的熱情,這也是我們團隊最名貴的財富. 這也是帶領我們團隊前進的動力.比如我們現在基本每兩周都會租個場子大家一起打打球,晚上有個聚餐.
主持人:您在招人過程中,比擬看重新人的哪些特質呢?在提升技術團隊方面,有哪些思考和做法?
王濤:技術、經驗才能這些固然重要,但是我們更看重的是對我們所做的事業的熱情.我相信只要有熱情,加上個人的努力,每個人都可以成為資深的工程師.
技術團隊這方面我們每周都會組織一個技術交流,會有一個同事上來做一些分享.同時我們售前和開發團隊會經常在一起聊.
開發測試這邊也有個制度,所有人都要定期輪崗加入客戶現場的實施,第一手掌握現場工程師的在客戶這邊所面臨的問題,真正深入了解客戶需求.
另外我們也非常鼓勵大家參與開源項目,不管是使用開源項目,還是向開源項目里面貢獻本身的代碼,都是非常值得提倡的.
對于售前銷售來說,我們也鼓勵他們寫經驗分享等文檔,在內部形成一個知識庫供所有人查看.
主持人:公司主要通過哪些渠道引進人才?目前招人不易成為不少公司CTO頭疼的問題,在招人方面有過哪些探索和經驗分享?
王濤:引進渠道除了傳統的一些途徑,其實產品的開源也更能聚集喜好者.我想我們作為一個底層開源項目,在這塊最大的優勢就是能夠吸引社區喜好者粉絲的加盟 :)
我們現在實施團隊很多兄弟都是通過社區開始了解我們,從而對我們產生認同感的.
主持人:您對開發者們有什么建議和忠告嗎?
王濤:其實也談不上忠告.對于開發者,我也想從一個創業者的角度談談創業至今感觸最深的一點.
從有這個idea開始,我們的團隊就決定從頭到尾完全本身開發巨杉數據庫,而不是基于某一個開源的項目進行“改造”.
一方面,自主研發讓企業擁有真正的主動權,不需要受制于別的技術,更能夠形成本身獨特的平臺和生態圈;另一方面,我們作為擁有核心技術的廠商,也希望能通過這樣一款自主研發的優秀產品,徹底扭轉海內外業界對于國內技術領域特別是基礎軟件領域“沒有過硬技術產品”的論斷.
最重要的一點,便是我對我們的團隊和我們的技術擁有十足的信心.
然而,對于大數據產品,特別是數據庫這樣一款底層而對性能、穩定性都有嚴格要求的產品來說,想要從頭到尾完全自己研發,整個過程也絕不簡單,其中也遇到了無數的坑和各種令人沮喪的情況,加班熬夜是家常便飯,算法調整代碼重構也不少見,甚至還有砍掉或者重做整個模塊或功能.但是我們都沒有因此放棄,保持勇于探索,最終也成功開發出了SequoiaDB巨杉數據庫.
所以不管是開發,或者是創業,我相信保持創新、堅定信念,你的目標就一定可以實現.
現場互動:SDB與DB2相比有哪些優勢?
王濤:SDB和DB2自己從體系結構上來看,對外最大的不同點就是,DB2不能用內置盤存儲 :)
為啥呢?因為DB2每個分區沒有replicate的機制,這樣如果使用內置盤,當一個機器掉電后,有可能寫盤正寫到一半,會造成數據頁損壞無法修復.這樣就使得DB2/oracle這種數據庫必需使用SAN存儲,也就是不可能用PC服務器集群.
而SDB或者新型分布式數據庫,其核心就是數據必要在多個節點復制,這樣即使機器掉電造成磁盤損壞,也可以從另外的節點恢復回來.
這也就是為啥說DB2這種數據庫不能做到彈性擴張,因為他們必需依賴硬件的小機+存儲設備,而不能是PC服務器集群.
現場互動:SDB在事務處理方面有什么特點嗎?
王濤:事務處理SDB用的就是二段提交,和DB2沒啥區別.spanner架構必要硬件的支持,而且還有很多潛在的問題.所以我們也在用二段的主流方式.
現場互動:巨杉數據庫使用典型的MPP架構,那么性能怎么樣?好比對比Vertica.
王濤:性能上來看,Vertica主要是列存儲,適合的是數倉類分析.
SDB是行存儲機制,主要特點是數據自適應和彈性擴展,兩者針對的場景分歧.
如果你讓我在數倉上和vertica pk報表系統性能不如它,他在我們適合的ODS場景那便是我們的主場了.
現場互動:SDB中應該有任務協調器之類的功能,請問是否使用的是生產者-消費者模式?對于多進程的鎖如何處理?大體說下就行,給個思路.
王濤:用的不是hadoop那種每個任務還要去調度器里面拿個id.數據庫是每個連接下面會直接對應一個線程作為agent.你說的生產者-消費者模式一般在中間件比較常見,比如10000個連接下面跑200個線程來服務.但是對于數據庫這種追求高響應速度的,每個哀求直接通到特定的線程,沒有生產者消費者的調度.
基本上你看DB2/oracle/postgresql都是這種模式,一般業務會使用生產者消費者模式在中間件層做處理,把海量并發縮減到幾百個數據庫長連接.如果直接幾萬個上數據庫,估計沒有應用會這么開發的 :)
現場互動: SDB和MySQL有什么區別呢?
王濤:一個是傳統的不克不及再傳統的關系型數據庫,一個是大數據體系下面的非關系型數據庫.MySQL一般作為每個應用下面掛的數據庫,對應一個特定的應用.而SDB很多場景是作為大數據平臺這種級別存在的,適用于一套平臺對應多種類型應用,可以支持在線離線業務的同時運行.
可以說SDB和MongoDB是同一類型的數據庫,MySQL和Oracle是同一類型的數據庫.
現場互動:分布式處理這塊 SDB和Hadoop相好比何?
王濤:我們和Hadoop是互補的定位.Hadoop是純粹的為批處理做的平臺,分為HDFS 存儲和YARN調度層.
我們和Hadoop協同工作的場景不少,主要都是我們作為Hadoop底層的數據庫,這樣hive的查詢可以直接把查詢條件下壓到數據庫使用索引加速查詢性能.
不過我們一般保舉使用Spark作為上層的分析引擎,交互式性能會更好.
現場互動:我們現在用的有哪些產品是基于這個技術架構的?
王濤:我們這邊主要的產品就是sequoiadb,企業版里面和社區版相比在平安方面有了增強,同時和spark有一個一體化的大數據解決方案.
現場互動:SDB和MSSQL比擬而言,有什么最大的優勢呢?MySQL 、MSSQL2014 、SDB 如果是大數據,仿真應用,該選擇哪個,為什么?
王濤:MSSQL實際上和MySQL差不多類型,都是屬于傳統關系型數據庫的.一般來說MSSQL不會有人用于大數據,這里我們指的大數據基本上是幾億記錄的數據量,可能會包括結構化和非結構化信息等.
現場互動:自動化的生產紀錄數據,能否也用SDB來玩呢?
王濤:您說的自動化,在我的理解是不是就是IOT這類傳感器數據?對于這類數據使用MSSQL可能會遇到一些坑,包括數據量很大檢索和存儲都很麻煩,而且硬件升級以后發送的信息可能包括新的內容,關系型數據庫還需要不停調整表結構,無法做到自適應數據.
我們一般見到的大部門IoT都會使用新型的分布式數據庫,就算不是SDB,可能也是cassandra MongoDB之類的.
想與業界大咖零距離溝通,歡迎參加CTO講堂微信群,參與CTO講堂!
【CTO講堂第13期預告】
分享主題:將“簡單快速”滲透到移動開發測試每個環節,從fir.im團隊說起
分享嘉賓:fir.im 創始人 王猛
嘉賓簡介:王猛,fir.im 創始人.最早是設計出身,后轉行Flash AS編程,曾經為路易威登做過全球網站.2008年開始從事iOS應用程序開發,是國內最早的一批開發者,、GitHub中國Objc Top 20.擅長從用戶體驗方面設計和改進應用,開發過的應用均一次通過App Store審核.
2014年4月在氪空間成立fir.im團隊,為開發者提供應用測試發布、瓦解分析等開發測試效率提升工具服務,目前fir.im已完成數輪融資.App Store中國榜Top 200中有80多款應用在使用 fir.im.
公司簡介:fir.im為開發者提供測試應用極速發布,應用崩潰實時分析、用戶反饋收集等一系列開發測試效率工具服務,贊助開發者將更多精力放在產品的開發與應用的優化上.
fir.im 追求簡潔極致的UI與用戶體驗,并因此受到國內外許多開發者的歡迎.截至目前,fir.im用一年的時間處理了387,000,000次下載哀求,幫助國內外開發者節省了約60000臺服務器資源、7,500,000分鐘(14年)的內測時間.
fir.im在亞太、北美部署了國際節點,且每個節點均為集群架構設置,可大幅提高應用上傳、下載速度.這樣,不論是必要海外測試的中國App開發團隊,還是必要中國測試的海外App開發團隊,都可使用fir.im進行跨國測試管理.
參加方式:掃描二維碼加“C粉兒小助手”好友,申請入群.
還不是CTO俱樂部成員的各公司技術負責人,歡迎立即參加俱樂部:cto.csdn.net.
《NoSQL對未來大數據發展的意義何在?》是否對您有啟發,歡迎查看更多與《NoSQL對未來大數據發展的意義何在?》相關教程,學精學透。維易PHP學院為您提供精彩教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9348.html
同類教程排行
- 大數據學習——你知道Apache Cas
- 一張圖理清NoSQL、MPP和Hadoo
- 新思潮:NoSQL與DPDK、RDMA等
- CockroachDB 1.1發布 平均
- NoSQL的基本概念和分類比較 Redi
- 細數5款主流NoSQL數據庫到底哪家強?
- mongodb nosql 如何實現分頁
- 解析SQL與NoSQL的融合架構產品GB
- mongodb NOSQL 各種查詢條件
- NoSQL數據庫的分布式算法
- 如何學習及選擇大數據非關系型數據庫NoS
- 騰訊十多個人管理一萬多臺NoSQL存儲服
- 科普|大數據技術原理與應用(第五章 No
- SQL和NOSQL有區別嗎?
- 2017年度全球“大數據企業50強”
