大數據協作框架—Sqoop介紹
《大數據協作框架—Sqoop介紹》要點:
本文介紹了大數據協作框架—Sqoop介紹,希望對您有用。如果有疑問,可以聯系我們。
概述
本日給大家一個福利,私信我可免費獲取java資源,Dubbo、Redis、Netty、zookeeper、Spring cloud 等你來領取!!!
一丶年夜數據協作框架是Hadoop 2.x生態系統中幾個輔助框架.最為常見的是以下幾個:
數據轉換工具Sqoop
文件收集庫框架Flume
任務調劑框架Oozie
年夜數據web工具Hue
Flume,抽取系統日志文件進入HDFS.Sqoop,完成關系型數據庫和Hdfs的數據抽取.Oozie:ETL作業管理,實現多任務的定時調度和多任務之間的依賴調度.Hue提供了一個web界面,管理年夜數據框架的所有組件.
由于Hadoop生態框架的分歧組件在使用時,可能會出現一些兼容性的問題(分歧組件來自于分歧的公司,并貢獻給Apache基金會),所以在學習Sqoop、Hbase、Oozie等框架如果再使用Apache的原生態版本會出現很多問題.
二丶安裝CDH版本hadoop:
選擇版本、下載解壓安裝文件:
首先選取一個CDH版本,下載對應的安裝包,我選用5.3.6,根據這個版本選各個組件就可以了.下載地址
下載 XX.tar.gz版本,并下載,解壓.
$ tar zxf hadoop-2.5.0-cdh5.3.6.tar.gz -C /opt/modules/$ tar zxf hive-0.13.1-cdh5.3.6.tar.gz -C /opt/modules/$ tar zxf sqoop-1.4.5-cdh5.3.6.tar.gz -C /opt/modules/$ tar zxf zookeeper-3.4.5-cdh5.3.6.tar.gz -C /opt/modules/
改動hadoop配置文件:
hadoop的配置文件都在 /opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoop 下
(1)配置env文件:
ls env.sh 找到必要修改的文件, 有如下幾個:hadoop-env.sh、mapred-env.sh 、yarn-env.sh. 添加java環境變量.
export JAVA_HOME=/opt/modules/jdk1.7.0_67
(2)改動*.xml文件.
必要修改以下文件:core-site.xml、hdfs-site.xml、yarn-site.xml 和 slaves文件:
core-site.xml:
<configuration><property> <name>fs.defaultFS</name> <value>hdfs://hadoop-senior01.pmpa.com:8020</value></property><property> <name>hadoop.tmp.dir</name> <value>/opt/modules/hadoop-2.5.0-cdh5.3.6/data</value></property></configuration>
hdfs-site.xml:
<configuration><property> <name>dfs.replication</name> <value>3</value></property><property> <name>dfs.namenode.http-address</name> <value>hadoop-senior01.pmpa.com:50070</value></property><property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop-senior03.pmpa.com:50090</value></property><property> <name>dfs.permissions.enabled</name> <value>true</value></property></configuration>
yarn-site.xml:
<configuration><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-senior02.pmpa.com</value></property><property> <name>yarn.log-aggregation-enable</name> <value>true</value></property><property> <name>yarn.log-aggregation.retain-seconds</name> <value>86400</value></property></configuration>
mapred-site.xml
<configuration><property> <name>mapreduce.framework.name</name> <value>yarn</value></property><property> <name>mapreduce.jobhistory.address</name> <value>hadoop-senior03.pmpa.com:10020</value></property><property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-senior03.pmpa.com:19888</value></property></configuration>
slaves文件:
hadoop-senior01.pmpa.comhadoop-senior02.pmpa.comhadoop-senior03.pmpa.com
設置開機自啟動Hadoop相關服務(HDFS、Yarn、Zookeeper等).
設置開機自啟動,必要修改/etc/rc.local文件.由于hadoop相關組件使用natty用戶啟動,所以必要切換用戶,-c選項指定運行腳本(必要指定絕對路徑).(未生效)
#hadoop-senior01:su - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start namenodesu - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start datanodesu - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start nodemanagersu - natty -c /opt/modules/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start#hadoop-senior02:su - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start datanodesu - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start nodemanagersu - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start resourcemanagersu - natty -c /opt/modules/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start#hadoop-senior03:su - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start nodemanagersu - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/mr-jobhistory-daemon.sh start historyserversu - natty -c /opt/modules/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh startsu - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start datanodesu - natty -c /opt/modules/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start secondarynamenode
(3)改動環境變量:
切換root用戶,在senior01主機上改動/etc/profile文件
#HADOOP HOMEHADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6#HIVE HOMEHIVE_HOME=/opt/modules/hive-0.13.1-cdh5.3.6
(4)同步安裝目錄到別的服務器:
$ scp -r hadoop-2.5.0-cdh5.3.6/ natty@hadoop-senior02.pmpa.com:/opt/modules/$ scp -r hadoop-2.5.0-cdh5.3.6/ natty@hadoop-senior03.pmpa.com:/opt/modules/
(5)測試安裝:
a. 格局化namenode:
$ bin/hdfs namenode -format
b.啟動hdfs、 Yarn 、 jobhistory:
$ sbin/start-dfs.sh$ sbin/start-yarn.sh$ sbin/mr-jobhistory-daemon.sh start historyserver$ bin/hdfs dfs - mkdir /input$ bin/hdfs dfs -put etc/hadoop/core-site.xml /input$ bin/hdfs dfs -text /input/core-site.xml$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /input/core-site.xml /output
(6)配置Hive:
配置hive異常簡單,參考文章8.
三丶Sqoop介紹:
1.簡單介紹:
Sqoop : SQL-to-Hadoop
用途:把關系型數據庫的數據轉移到HDFS(Hive、Hbase)(重點使用的場景);Hadoop中的數據轉移到關系型數據庫中.Sqoop是java語言開發的,底層使用mapreduce.
2.版本
Sqoop有2個版本:Sqoop 1 和 Sqoop 2.然則目前企業使用的主要還是Sqoop 1,2版本還不穩定,使用時bug很多.
Sqoop2的改良:
1.引入server,集中化管理connnector.
2.多種拜訪方式: CLI、Web UI
3.引入基于角色的平安機制.
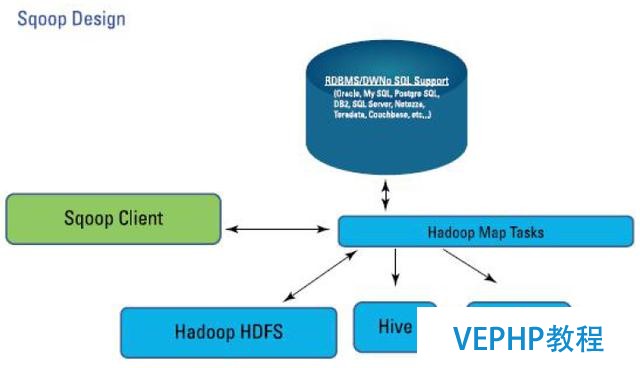
Sqoop設計
必要注意的是,Sqoop主要使用的是Map,是數據塊的轉移,沒有使用到reduce任務.
3.使用要點
下圖描述了Sqoop的主要使用命令:
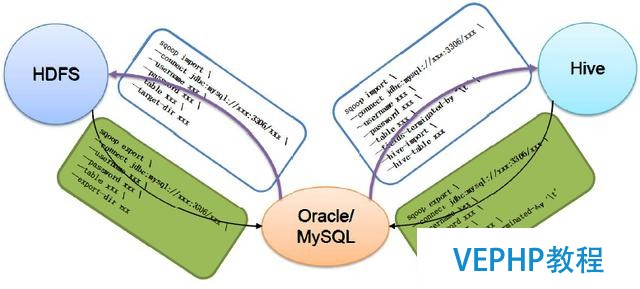
sqoop使用要點
上圖中,有2個主要的命令,即export 和 import,導入導出.
這里的導入和導出是相對于HDFS來講的.例如,從RDBMS中導入到Hive中,便是導入(import);從Hive導入到Mysql中,便是導出(export).
四丶Sqoop安裝配置和簡單使用:
1.sqoop安裝
Sqoop類似于Hive,只是一個客戶端,不必要在每個節點上都安裝.
(1)下載解壓安裝包.
(2)改動配置:
cd到目錄$SQOOP_HOME/conf,改動配置文件.
$ cp -a sqoop-env-template.sh sqoop-env.sh
改動配置文件sqoop-env.sh,配置以下選項:
#Set path to where bin/hadoop is availableexport HADOOP_COMMON_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6#Set path to where hadoop-*-core.jar is availableexport HADOOP_MAPRED_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6#Set the path to where bin/hive is availableexport HIVE_HOME=/opt/modules/hive-0.13.1-cdh5.3.6#Set the path for where zookeper config dir isexport ZOOCFGDIR=/opt/modules/zookeeper-3.4.5-cdh5.3.6/conf
2.sqoop使用
查看命令贊助:
$ bin/sqoop help
因為sqoop是使用JDBC連接關系型數據庫,并完成數據的轉移的,所以很明顯我們必要jdbc驅動,將jdbc驅動jar包復制到$SQOOP_HOME/lib下:
$ cp mysql-connector-java-5.1.27-bin.jar /opt/modules/sqoop-1.4.5-cdh5.3.6/lib/
查看某一個具體命令的贊助:
$ bin/sqoop list-databases --help
我們使用所有Sqoop命令都可以組合使用上邊2個help命令來定位該命令的使用辦法.
下面運行一個命令,來測試sqoop功能. list-databases,該命令展示mysql庫的所有數據庫.因為展示所有數據庫,所以JDBC url沒有指定庫.
$ bin/sqoop list-databases \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/ \--username root \--password 123456
五丶從mysql庫import數據到HDFS:
sqoop從mysql數據庫抽取數據到hive,使用import命令.主要需要2個步驟:(1)收集元數據;(2)提交只包括map的job.
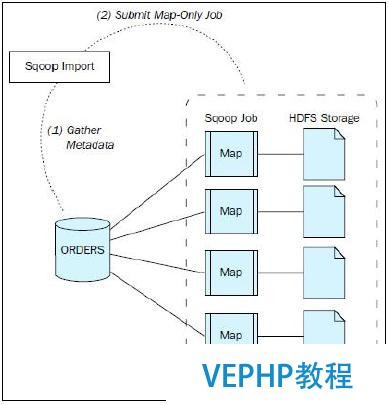
sqoop import步調
1.在mysql創立測試表并準備數據.
$ mysql -hlocalhost -uroot -p123456mysql> create database pma_test;mysql> use pma_test;mysql> select database();create table `cities` (`id` int not null auto_increment,`city` varchar(255) default null,`country` varchar(255) default null,PRIMARY KEY (`id`));insert into cities values (1,'Tokyo','Japan');insert into cities values (2,'Osaka','Japan');insert into cities values (3,'Yokohama','Japan');insert into cities values (4,'Nagoya','Japan');insert into cities values (5,'New York','USA');insert into cities values (6,'Boston','USA');insert into cities values (7,'Berlin','Germany');insert into cities values (8,'London','UK');
2.使用分歧方式將mysql數據表導入hdfs
(1)直接將mysql表導入到HDFS上:
下例中,將mysql中的表pma_test.cities導入到hdfs.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities
不指定導入目錄,默認情況是導入到hdfs上面用戶家目錄下邊.
那么上邊的文件將會導入到HDFS的目錄是:/user/natty/cities
(2)指定HDFS的目錄和mapper數量:
先創立一個hdfs目錄,然后將mysql數據import指定到這個目錄.
$ bin/hdfs dfs -mkdir /user/hive/warehouse/testdb.db/cities;$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--num-mappers 1 \--target-dir /user/hive/warehouse/testdb.db/cities/ \--delete-target-dir
--num-mappers 1 : 指定mapper的數量是1;
--target-dir :為import操作指定目標目錄,也就是必要將數據import到哪個目錄下.
--delete-target-dir :指定了該參數后,如果hdfs的目標路徑已經存在了的話,就先刪除該目錄,再進行import(會重新創立該目錄).
(3)指定分隔符
默認情況下,import導入hdfs的文件,字段分隔符是逗號.可以使用參數 --fields-terminated-by 來改動字段分隔符. 下邊例子改為TAB分隔字段.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--num-mappers 1 \--target-dir /user/natty/sqoop/cities \--delete-target-dir \--fields-terminated-by '\t'
--fields-terminated-by : 指定字段的分隔符為 '\t' .
查看導入hdfs的文件,可以看到,字段分隔符是tab鍵.
$ bin/hdfs dfs -text /user/natty/sqoop/cities/pa*
(4)增量導入數據文件:
可以依照mysql表的PK,增量導入數據.只導入變化的數據.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--num-mappers 1 \--target-dir /user/natty/sqoop/cities \--check-column id \--incremental append \--last-value 7 \--fields-terminated-by '\t'
--check_column : 是指定增量的字段,通過id字段獲取增量數據.
--incremental :指定導入的方式,追加.
--last-value :從哪行開始導入,表現從第8行開始導入.
必要注意:當使用增量導入時,選項--delete-target-dir 不可以使用,否則報錯.
通過成果發現,id為8的記錄導入了2次.
(5)選擇文件的保留格式:
默認情況下,導出的文件格式是textfile,可以指定參數改動導出格式.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--num-mappers 1 \--delete-target-dir \--target-dir /user/natty/sqoop/cities \--fields-terminated-by '\t' \--as-parquetfile
--as-parquetfile : 指定文件的導出格局為parquet.
生成了類似"7185ff10-b9e5-4b14-9ef2-c24c3a7e3bba.parquet"格局的文件.
(6)是否壓縮,和壓縮方式選擇:
默認情況下,文件不壓縮.可以指定壓縮,并選擇壓縮格局.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--num-mappers 1 \--delete-target-dir \--target-dir /user/natty/sqoop/cities \--compress
--compress : 表現對文件壓縮.
壓縮之后,hdfs目錄生成了part-m-00000.gz文件,導入hdfs的文件已經進行了壓縮.
(7)其他常用的參數:
還包含
--query :后接sql語句,依照sql語句抽取文件.
--columns : 選擇某些字段來抽取.
--where : 查詢的where條件.
一般情況下,可以使用--query指定完整的sql語句來替代table、columns、where選項.使用--query時,要指定--target-dir
Instead of using the --table, --columns and --where arguments, you can specify a SQL statement with the --query argument.
第一種情況,使用colums、where條件,這時候必要指定--table項.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--num-mappers 1 \--delete-target-dir \--target-dir /user/natty/sqoop/cities \--columns 'id','city' \--where 'id>=4'
第二種情況,使用--query選項.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--num-mappers 1 \--delete-target-dir \--target-dir /user/natty/sqoop/cities \--query "select * from cities where country = 'Japan' and \$CONDITIONS"
注意: 條件$CONDITIONS必需添加,而且$還要做轉義,否則會報錯.
六丶 從mysql庫import數據到HIVE:
前邊導入的目標是hdfs目錄,如果想導入到hive表中,使用參數--hive-table 和 --hive-import兩個選項,例如下邊的例子,將cities表導入到hive的hive_cities表中:
##先刪除用戶家目錄下的文件夾cities$ bin/hdfs dfs -rmr /user/natty/cities/$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--hive-import \--hive-table hive_cities \--fields-terminated-by '\t'hive> select * from default.hive_cities;
上邊的例子中,沒有指定數據庫,所以表建到了default庫下.
我們也可以指定導出的hive表地點的數據庫.使用參數--hive-database選項.
$ bin/sqoop import \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table cities \--delete-target-dir \--hive-import \--hive-table hive_cities \--hive-database testdb \--fields-terminated-by '\t'hive> select * from testdb.hive_cities;
從mysql導入到hive時,先將mysql數據導出放在hdfs目錄:/user/natty/cities下,然后在load到hive表里去.所以上邊再次導入這個表到hive另一張表時,必要指定選項--delete-target-dir,否則報錯:
Output directory hdfs://hadoop-senior01.pmpa.com:8020/user/natty/cities already exists
七丶從hdfs export導出到RDBMS的應用相對少一些.使用export命令實現.
$ bin/sqoop export \--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \--username root \--password 123456 \--table hdfs2mysql \--export-dir /user/hive/warehouse/testdb.db/cities/ \--input-fields-terminated-by ','mysql> select * from hdfs2mysql;
export成功后,可以在mysql內外查看到數據.
--table :指定我們要導入到mysql的哪張表中.
--export-dir : 從hdfs上的哪個路徑上導出.
--input-fields-terminated-by ',' : 這項必要非常注意,我們先確定hdfs上的文件是以什么符號作為字段分隔符的,然后指定這項.這項跟import的不同,是input-xxx屬性,輸入文件的分隔符.
從Hive表導入到Mysql表: 實質上便是從HDFS導入到RDBMS,沒有特殊的選項參數.
總結
到這里,深入理解java—大型網站分布式高并發架構知識就結束了,,不足之處還望大家多多原諒!!覺得收獲的話可以點個關注收藏轉發一波喔,謝謝大佬們支持.(吹一波,233~~)
下面和年夜家交流幾點編程的經驗:
1、多寫多敲代碼,好的代碼與扎實的基礎知識必定是實踐出來的
2丶 測試、測試再測試,如果你不徹底測試本身的代碼,那恐怕你開發的就不只是代碼,可能還會聲名狼藉.
3丶 簡化算法,代碼如惡魔,在你完成編碼后,應回頭而且優化它.從長遠來看,這里或那里一些的改進,會讓后來的支持人員更加輕松.
最后,每一位讀到這里的網友,感謝你們能耐心地看完.希望在成為一名更優秀的Java法式員的道路上,我們可以一起學習、一起進步.
我的內部交流群469717771 歡迎列位前來交流和分享, 驗證:(009)

維易PHP培訓學院每天發布《大數據協作框架—Sqoop介紹》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9227.html
