MySQL架構優化實戰系列2:主從復制同步與查詢性能調優
《MySQL架構優化實戰系列2:主從復制同步與查詢性能調優》要點:
本文介紹了MySQL架構優化實戰系列2:主從復制同步與查詢性能調優,希望對您有用。如果有疑問,可以聯系我們。
1、主從復制同步部署
1、觀點
主從復制:2臺以上mysql服務器, 做負載均衡, 主服務器負責增編削 , 從服務器負責查詢
同步原理:mysql開啟bin-log日志,主服務器所有的增編削操作會記錄到bin-log日志;然后主服務器把bin-log日志發送 給 從服務器 , 從服務器重放bin-log日志 確保數據同步
2、開啟bin-log日記
設置裝備擺設 my.cnf 文件 并重啟 mysql
[root@localhost etc]# vim /etc/my.cnf
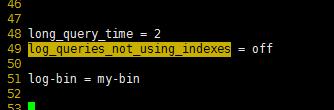
[root@localhost etc]# service mysql restart
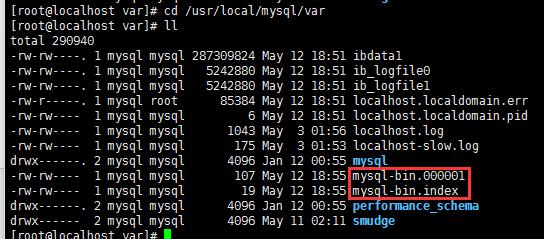
開啟之后 mysql-bin對應的文件 已經呈現
[root@localhost var]# cd /usr/local/mysql/var && ll
通過 show master status 命令查看 最新一個binlog日志 及開端行數
mysql> show master status;
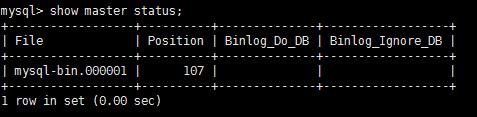
查看binlog日志內容 可見 最新一行日志在地位107
$ /usr/local/mysql/bin/mysqlbinlog /usr/local/mysql/var/mysql-bin.000001
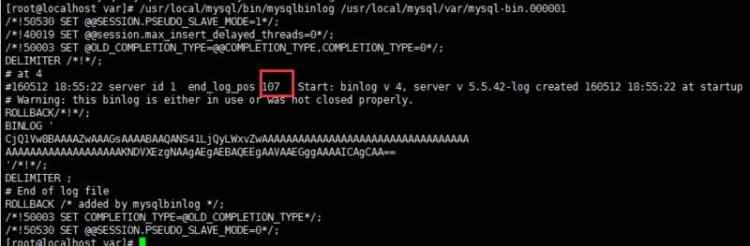
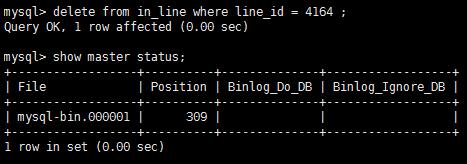
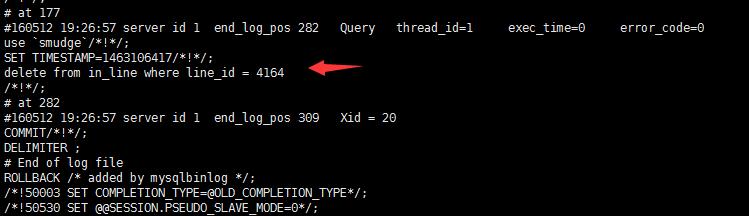
測試刪除數據 可見 binlog文件新增日記內容
3、bin-log日志相關敕令
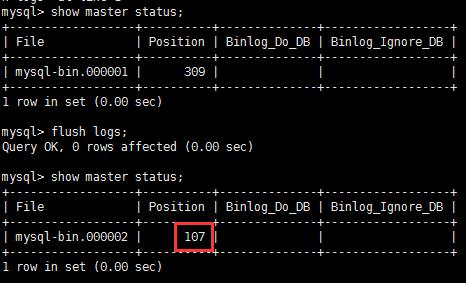
flush logs
新建一個binlog日志,增編削日志在新文件中插入,新的日志end-log-positon 是107行,107行記錄了mysql內部日志.
reset master
清空所有bin-log日志 只保存 mysql-bin.000001 文件
mysqlbinlog
查看bin-log日記/usr/local/mysql/bin/mysqlbinlog/usr/local/mysql/var/mysql-bin.00001
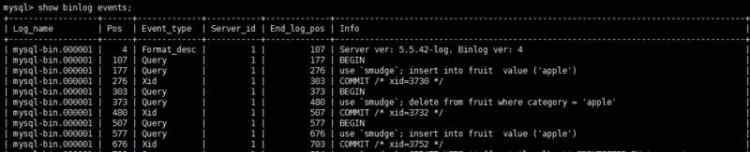
show binlog events 查看binlog記錄變亂
mysqlbinlog mysql -uroot -psmudge smudge_database
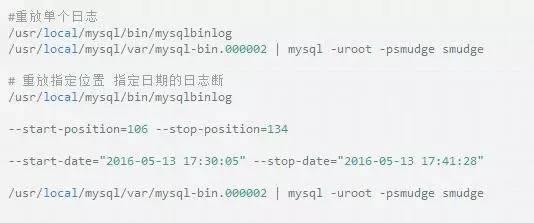
重放bin-log日志、恢復數據:其實就是再把日志中的sql語句執行一邊罷了.(注意:select 語句 和delete語句 不可以放在一起重放 因為你最后還是得不到數據)
恢復原理便是:執行之前的insert語句,或者之前的update語句
如果你的單純的delete物理刪除,別想規復了,因為再次執行的還是delete語句
4、create 創立用戶 + grant用戶授權
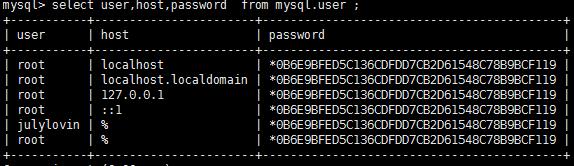
主服務器查看用戶暗碼
mysql> select host,user,password from mysql.user;
添加主服務器用戶暗碼
CREATE USER 'kang'@'192.168.206.132' IDENTIFIED BY 'smudge';
創建用戶kang 可以在ip為192.168.206.132主機上拜訪數據庫

給用戶kang受權所有的庫的權限

5、主服務器設置裝備擺設
主服務器ip:192.168.206.128
設置裝備擺設主服務器my.cnf 文件
vim /etc/my.cnf
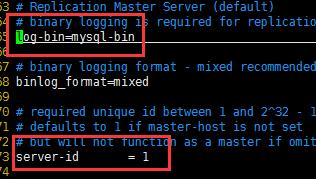
設置裝備擺設之后刷新binlog文件
flush logs with read lock 確保獲得一致性快照,等待主從binlog日志同步完畢到達數據一致
又或使用mysqldump備份sql 文件
將主服務器一致都是sql文件備份,通報到從服務器
mysqldump -uroot -psmudge smudge -l -F > '/home/smudge.sql'
-l 是指鎖表 避免新數據插入
-F 是刷新 生成一個新的binlog日記
(假如你數據庫中有merge表 容易會提示Unable to open underlying table which is differently defined or ofnon-MyISAM type ordoesn't exist when using LOCK TABLES )

使用scp隧道傳輸敕令 傳遞文件
scp /home/smudge.sql 192.168.206.132:/home

6、從服務器設置裝備擺設
恢復一部門主服務器備份的數據
新建smudge庫
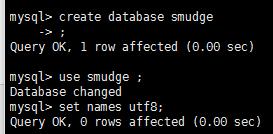
mysql導入sql文件
[root@localhost~]# mysql -uroot -psmudge smudge < /home/smudge.sql
設置裝備擺設從服務器my.cnf文件
vim /etc/my.cnf
其中用戶名和暗碼就是上述我們在主服務器添加的信息
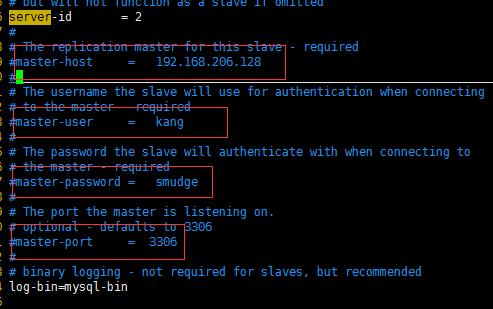
(如果你的mysql版本5.1(mysql>status查看)之前的,配置這4項,啟動之后就不必使用change master 敕令 進行主動同步)
保留并重啟mysql
查看主服務器master binlog文
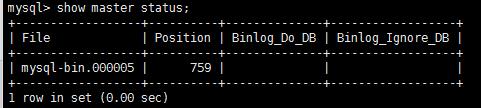
啟動slave過程,開啟主從同步
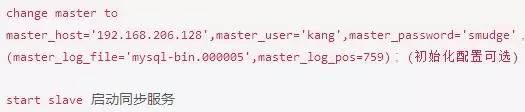
因為我的mysql版本是5.7的, 所以我使用change master敕令
show slave status 查看從服務器狀況
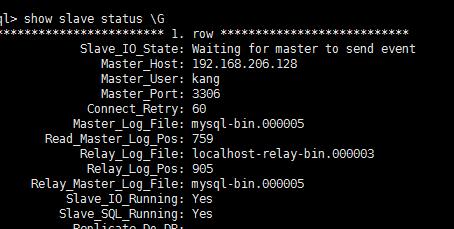
注解同步功能已經開啟
7、從服務器常用敕令
start slave 啟動復制線程
stop slave 結束復制線程
show master logs 查看主數據庫日記
change master to master_host ,master_user 靜態切換主數據庫
show processlist 查看運行過程 (主動服務器都適用)
8、常見差錯排錯
show slave status 反省主動狀態
20 數值為NO
21 數值為
注解同步出現了故障,可能是slave服務器執行了寫操作或者從服務器重啟有事務回滾操作.
辦理
從服務器: stop slave 封閉復制線程
主服務器:show master status 查看最新二進制文件和地位偏移量
從服務器執行:change master to master_host ...
master_log_file='mysql-bin.000005',master_log_pos=759 敕令
二、查詢機能優化
1、查詢執行根基知識
mysql執行查詢進程
① 客戶端將查詢發送到服務器
② 服務器檢查查詢緩存 如果找到了就從緩存返回結果 不然進行下一步
③ 服務器解析,預處置和優化查詢,生成執行計劃
④ 執行引擎挪用存儲引擎api執行查詢
⑤ 服務器將成果發送回客戶端
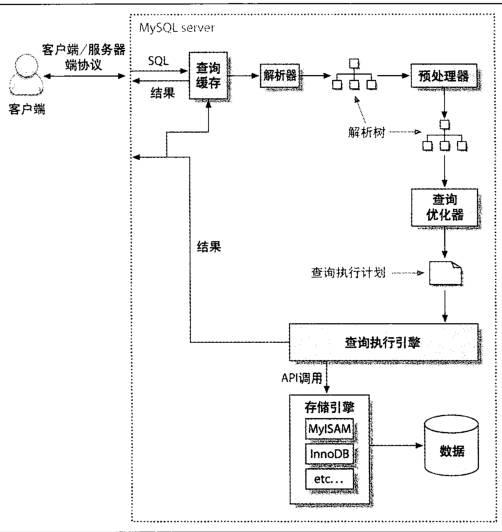
mysql客戶端/服務器協定
該協議是半雙工通信,可以發送或接收數據,但是不克不及同時發送和接收決定了mysql的溝通簡單又快捷;
缺點:無法進行流程控制,一旦一方發送消息,另一方在發送回復之前必需提取完整的消息,就像拋球游戲,任意時間,只有某一方有球,而且有球在手上,否則就不能把球拋出去(發送消息)
mysql客戶端發送/服務器相應
可以設定max_packet_size這個參數控制客戶端發送的數據包(一旦發送數據包,唯一做的便是等待結果)
服務器發送的響應由多個數據包組成, 客戶端必須完整接收結果,即使只需要幾行數據,也得等到全部接收 然后丟掉,或者強制斷開連接.(這兩個辦法好挫,所以我們使用limit子句呀!!)
也可以理解,客戶端從服務器 "拉" 數據 ,實際是服務器產生數據 "推"到客戶端, 客戶端不能說不要 是必需全部裝著!
常用的Mysql類庫 其實是從客戶端提取數據 緩存到array(內存)中,然后進行 foreach 處置.
但是對于龐大的結果集裝載在內存中必要很長時間,如果不緩存,使用較少的內存并且可以盡快工作,但是應用程序和類庫交互時候,服務器端的鎖和資源都是被鎖定的.
查詢狀況
每個mysql連接都是mysql服務器的一個線程 任意一個給定的時間都有一個狀態來標識正在產生的事情.
使用 show full processlist 敕令查看
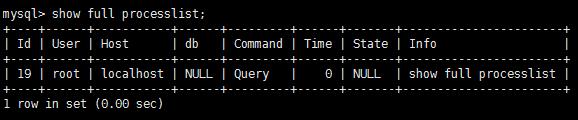
mysql中一共有12個狀態:休眠、查詢、鎖定、闡發和統計、拷貝到磁盤上的臨時表、排序結果、發送數據,通過這些狀態 知道 "球在誰手上".
查詢緩存
解析一個查詢,如果開啟了緩存,mysql會反省查詢緩存,發現緩存匹配,返回緩存之前,反省查詢的權限.
2、優化數據拜訪
查詢性能低下最基本的原因是拜訪了太多的數據,分析兩方面:
① 查明應用程序是否獲取超過需要的數據 通常意味著拜訪了過多的行或列
② 查明mysql服務器是否分析了超過必要的行
向服務器哀求了不需要的數據
一般哀求不需要的數據,再丟掉他們,造成服務器額外的負擔,增加網絡開銷,消耗了內存和cpu.
典型的差錯:
① 提取超過必要的行 => 添加 limit 10 控制獲取行數
② 多表聯接提取所有列 => select fruit.* from fruit left join fruit_juice where
.....
③ 提取所有的列 => select id,name... from fruit ... (有時提取超過必要的數據便于復用)
mysql檢查了太多半據
簡單的開銷指標:執行時間、反省的行數、返回的行數.
以上三個指標寫入了慢查詢日志 可以使用 mysqlsla工具進行日志闡發:
① 執行時間:執行時間只是參考 弗成一概而論 因為執行時間 和服務器當時負載有關
② 檢查和返回的行:抱負情況下返回的行和檢查的行一樣,但是顯示基本不可能 比如聯接查詢
③ 檢查的行和拜訪類型: 使用explain sq語句,觀察typ列

typ列:(拜訪速度依次遞增)
① 全表掃描(full table scan)
② 索引掃描(index scan)
③ 規模掃描(range scan)
④ 獨一索引查找(unique index lookup)
⑤ 常量(constant)
可見type列為index即sql語句,基于索引掃描:
rows列為12731,即掃描了12731行 extra列為using index,即使用索引過濾不必要的行
mysql會在3種環境下使用where子句,從最好到最壞依次是:
① 對索引查找應用where子句來消除不匹配的行 這產生在存儲層
② 使用覆蓋索引(extra 列 "using index") 避免拜訪行 從索引取得數據過濾不匹配的行 這發生在服務層不需要從表中讀取行
③ 從表中檢索出數據 過濾不婚配的行(extra:using where)
如果發現拜訪數據行數很大,嘗試以下措施:
① 使用籠罩索引 ,存儲了數據 存儲引擎不會讀取完整的行
② 變動架構使用匯總表
③ 重寫繁雜的查詢 讓mysql優化器優化執行它
3、重構查詢的方式
優化有問題的查詢,其實也可以找到替代計劃,提供更高的效率.
繁雜查詢和多個查詢
mysql一般服務器可以每秒50000個查詢,慣例情況下,使用盡可能少的查詢 有時候分解查詢得到更高的效率.
縮短查詢
分治法,查詢本色上不變,每次執行一小部分,以減少受影響的行數.比如清理陳舊的數據,每次清理1000條:
delete from message where create < date_sub(now,inteval 3 month)
limit 1000
防止長光陰鎖住很多行的數據.
分化聯接
把一個多表聯接分解成多個單個查詢 然后在應用法式實現聯接操作
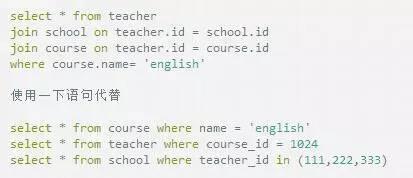
第一眼看上去比擬浪費,因為增加了查詢數量,但是有重大的性能優勢:
① 緩存效率高,應用法式直接緩存了表 類似第一個查詢直接跳過
② 對付myisam表來說 每個表一個查詢有效利用表鎖 查詢鎖住表的時間縮短
③ 應用程端進行聯接更便利擴展數據庫
④ 使用in 避免聯表查詢id排序的消耗
⑤ 減少多余行的拜訪 , 意味著每行數據只拜訪一次 避免聯接查詢的非正則化的架構帶來的反復拜訪同一行的弊端
分解聯策應用場景:
① 可以緩存早期查詢的年夜量的數據
② 使用了多個myisam表(mysiam表鎖 并發時候 一條sql鎖住多個表 所以要分化)
③ 數據分布在分歧的服務器上
④ 對于年夜表使用in 替換聯接
④ 一個聯接引用了同一個表許多次
提取隨機行

分組查詢

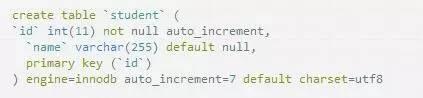
外鍵
只有Innodb引擎支持外鍵,myisam可以添加外鍵然則沒有效果.
主表添加主鍵id,從表添加外鍵id援用主表的id.
表student
表student_extend
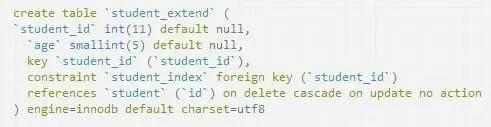
為student_extend添加外鍵,外鍵指向student表中的id列,在delete時觸發外鍵.
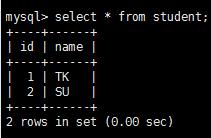
表student數據
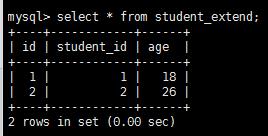
表student_extend數據
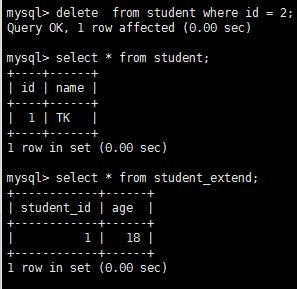
刪除了表student一條數據,則外鍵表就會觸發外鍵,刪除了對應數據:
delete from student where id = 2;
優化結合查詢

優化max min
此中 name 沒有索引

對一個表同時進行select以及update
維易PHP培訓學院每天發布《MySQL架構優化實戰系列2:主從復制同步與查詢性能調優》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/7830.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
