MySQL架構優化實戰系列1:數據類型與索引調優全解析
《MySQL架構優化實戰系列1:數據類型與索引調優全解析》要點:
本文介紹了MySQL架構優化實戰系列1:數據類型與索引調優全解析,希望對您有用。如果有疑問,可以聯系我們。
一、數據類型優化
數據類型
整數
數字類型:整數和實數
tinyint(8)、smallint(16)、mediuint(24)、int(32)、bigint(64) 數字表示對應最大存儲位數,如 tinyint (-127 --- 128),tinyint unsigned 表示不允許負數,則范圍為 (0 -- 255).
常規數據庫中 int(11) 只是表示控制顯示字符的個數是11個,int(1) 和 int(20) 存儲和計算是一樣的,即 int(1) 照樣可以存儲1111(4位數).
實數
實數有分數部分
float 和 double 類型支持使用標準的浮點運算近似計算
float 占用4個字節 double占用8個字節
decimal 類型用于保存精確的小數
decimal(18,9) 18表示小數點前后總位數 9表示小數點后面位數
mysql 5.0版本以上 4個字節保存9位數字
decimal(18,9) 共占用9個字節 小數點前4個字節 小數點后占1個 小數點后4個字節
字符串類型
varchar和char類型
varchar保存可變長度的字符串,比固定長度類型占用更少的存儲空間,只占用需要的空間.
varchar使用額外的1到2字節存儲長度,列小于255使用1字節保存長度,大于255使用2字節保存,varchar保留字符串末尾的空格.
char是固定長度,保存char值時候 **mysql去掉任何末尾的空格** ,進行比較時 空格會被填充到字符串末尾.
很多的char列,效率高于varchar,比如 char(1)對于單字節字符集占用1字節,varchar(1)占用兩字節,因為1字節保存長度.
慷慨不是明智的,分配真正需要的空間.
Blob和Text類型
blob和text唯一區別就是blob保存二進制數據、沒有字符集和排序規則.
選擇優化的數據類型
更小通常越好
使用更少的磁盤、內存、cpu,確保不會低估保存的值,但是text有字符集和排序規則.mysql不能索引這些數據類型的完整長度,也不能為排序使用索引.
簡單就好
比較整數的代價小于比較字符,使用mysql內建類型保存時間和日期,使用整數保存ip.
盡量避免
mysql難以優化可空列查詢,使固定索引(整數列上的索引)編程可變大小索引;沒有值可以使用 0 或者空字符串代替;把 列改為not 帶來的性能提升很小.
確定類型
像數字、字符串、時間、直觀類型可以確定,但是像 datetime 和timestamp,能保存同樣的類型.timestamp使用空間只有datetime一半.可以保存時區.
使用enum代替字符串類型
enum列可以保存65535不同的字符串,存儲在一個 "查找表"中 mysql內部存儲的是列表中的位置.
內部存儲的是這個字符串對應的位置,實際表中存儲的還是字符串.
創建一個表fruit category字段為enum類型,包含4種不同水果:


插入4條數據,即4中不同水果.其中,最后一個菠蘿(pineapple) 沒有enum值 則插入了空數據.
發現字段category保存的還是字符串,其實內部已經將這些字符串關聯到enum字符的位置.
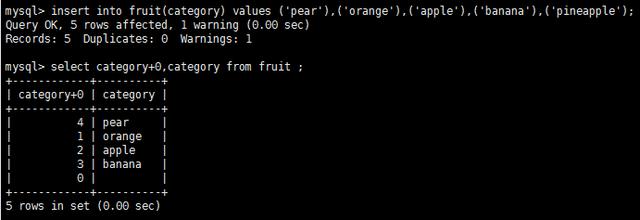
支持字符串搜索和位置搜索
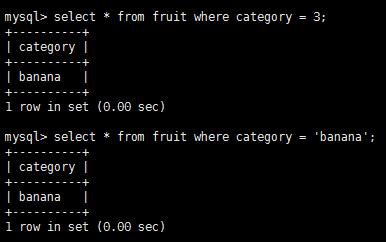
emu缺點在于插入數據之前,如果沒有對應enum,則需要alter表結構.
enum優點在于占用更少的存儲空間.
據說 enum 用于聯接查詢性能也比較好.
日期和時間類型
datetime 保存是1001年到9999年,精度是秒,存儲值為 2016-05-06 22:39:40.
timestamp保存自 1970年1月1日午夜以來的秒數,和unix時間戳相同,提供4字節存儲 只能表示1970年到2038年.默認timestamp值 為 NOT .
mysql中提供 from_unixtime函數把unix時間戳轉換為日期
unix_timestamp把日期轉換為unix時間戳
如果需要秒以下的精度保存日期和時間,可以使用bigint類型把它以毫秒的精度保存時間戳格式,或使用double保存秒的分數部分.
選擇標識符
整數類型通常是標識符最佳選擇,速度快,且能使用auto_increment,避免使用字符串做標識符,占用很多空間并且比整數類型要慢.
特殊類型的數據
通常使用varchar(15)保存IP地址,其實IP地址是無符號的32位整數,不是字符串,小數點僅僅為了可讀性.
mysql提供了 inet_aton inet_ntoa ,用于 ip地址和整數之前轉換.
二、索引優化
索引基礎知識
索引幫助mysql高效獲取數據的數據結構,索引(mysql中叫"鍵(key)") 數據越大越重要.索引好比一本書,為了找到書中特定的話題,查看目錄,獲得頁碼.
select fruit_name from fruit where id = 5 索引列位于id列,索引按值查找并且返回任何包含該值的行.
如果索引了多列數據,那么列的順序非常重要.
存儲引擎說明
myisam 存儲引擎
表鎖:myisam 表級鎖
不支持自動恢復數據:斷電之后 使用之前檢查和執行可能的修復
不支持事務:不保證單個命令會完成, 多行update 有錯誤 只有一些行會被更新
只有索引緩存在內存中:mysiam只緩存進程內部的索引
緊密存儲:行被僅僅保存在一起
Innodb存儲引擎
事務性:Innodb支持事務和四種事務隔離級別
外鍵:Innodb唯一支持外鍵的存儲引擎 create table 命令接受外鍵
行級鎖:鎖設定于行一級 有很好的并發性
多版本:多版本并發控制
按照主鍵聚集:索引按照主鍵聚集
所有的索引包含主鍵列:索引按照主鍵引用行 如果不把主鍵維持很短 索引就增長很大
優化的緩存:Innodb把數據和內存緩存到緩沖池 自動構建哈希索引
未壓縮的索引:索引沒有使用前綴壓縮,阻塞auto_increment:Innodb使用表級鎖產生新的auto_increment
沒有緩存的count:myisam 會把行數保存在表中 Innodb中的count會全表或索引掃描
索引類型
索引在存儲引擎實現的,而不是服務層.
B-tree 索引
大多數談及的索引類型就是B-tree類型, 可以在create table 和其他命令使用它 myisam使用前綴壓縮以減小索引,Innodb不會壓縮索引,myiam索引按照行存儲物理位置引用被索引的行,Innodb按照主鍵值引用行,B-tree數據存儲是有序的,按照順序保存了索引的列,加速了數據訪問,存儲引擎不會掃描整個表得到需要的數據.
B-tree 索引實例

使用B-tree索引的查詢類型,很好用于全鍵值、鍵值范圍或鍵前綴查找,只有在超找使用了索引的最左前綴的時候才有用.
匹配全名:全鍵值匹配和索引中的所有列匹配
查找叫Tang Kang 出生于 1991-09-23 的人
匹配最左前綴:B-tree找到姓為tang的人
匹配列前綴: 匹配某列的值的開頭部分 查找姓氏以T開頭的人
匹配范圍值:索引查找姓大于Tang小于zhu的人
精確匹配一部分并且匹配某個范圍的另外一部分:
查找姓為Tang并且名字以字母K開頭的人 精確匹配last_name列并且對
first_name進行范圍查詢
只訪問索引的查詢:B-tree支持只訪問索引的查詢,不會訪問行
B-tree局限性
B-tree局限性:(案例中索引順序:last_name first_name dob )
如果查找沒有送索引列的最左邊開始,沒有什么用處,即不能查找所有叫Kang 的人,也不能找到所有出生在某天的人,因為這些列不再索引最左邊,也不能使用該索引超找某個姓氏以特定字符結尾的人.
不能跳過索引的列,即不能找到所有姓氏為Tang并且出生在某個特定日期的人,如果不定義first_name列的值,Mysql只能使用索引的第一列.
存儲引擎不能優化任何在第一個范圍條件右邊的列,比如查詢是where last_name = 'Tang' AND first_name like 'K%' AND dob='1993-09-23' 訪問只能使用索引頭兩列.
由此可知 索引列順序的重要性!
哈希索引
目前只有Memory存儲引擎支持顯示的哈希索引,而且Memory引擎對我來說不常用,所以我們就輕描淡寫的過了吧.
R-tree(空間索引)
Myisam支持空間索引,可以使用geometry空間數據類型.
空間索引不會要求where子句使用索引最左前綴可以全方位索引數據,可以高效使用任何數據組合查找 配合使用mercontains函數使用.
全文索引
fulltext是Myisam表特殊索引,從文本中找關鍵字不是直接和索引中的值進行比較.
全文索引可以和B-Tree索引混用,索引價值互不影響.
全文索引用于match against操作 而不是普通的where子句.
前綴索引和索引選擇性
通常索引幾個字符,而不是全部值,以節約空間并得到好的性能,同時也降低選擇性.
索引選擇性是不重復的索引值和全部行數的比值.高選擇性的索引有好處,查找匹配過濾更多的行,唯一索引選擇率為1最佳狀態.
blob列、text列及很長的varchar列,必須定義前綴索引,mysql不允許索引他們的全文.
前綴索引和索引選擇性實例
造數據
#復制一份與cs_area表結構

#插入1600數據

#模擬真實數據

#表area有name列 需要對name列前綴索引
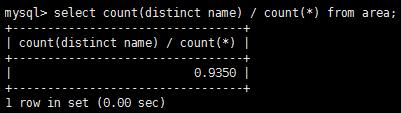
#計算得比值接近0.9350就好了
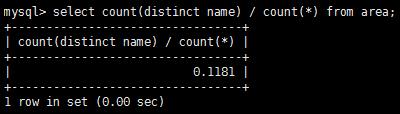
#分別取 3 4 5位name值計算
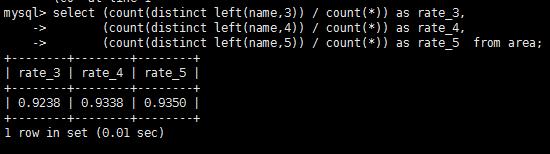
#可知name列添加5位前綴索引就可以了
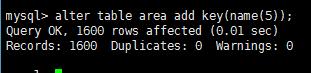
#Mysql不能在order by 或 group by查詢使用前綴索引 也不能將其用作覆蓋索引
聚集索引
聚集索引不是一種單獨的索引類型,而是一種存儲數據的方式.
Innodb 的聚集索引實際上同樣的結構保存了B-tree索引和數據行,"聚集" 是指實際的數據行和相關的鍵值保存在一起,每個表只能有一個聚集索引,因此不能一次把行保存在兩個地方. (由于聚集索引對我來說不常用,我們就略過啦~)
覆蓋索引
索引支持高效查找行,mysql也能使用索引來接收列的數據.這樣不用讀取行數據,當發起一個被索引覆蓋的查詢,explain解釋器的extra列看到 using index.
#滿足條件:#
# select 查詢的字段必須 有索引全覆蓋
select last_name,first_name 其中 last_name 和first_name 必須都有索引
#不能在索引執行like操作
為排序使用索引掃描
mysql排序結果的方式:使用文件排序 、 掃描有序的索引
explain中的type列若為 "索引(Index)" 說明mysql掃描索引.單純掃描索引很快,如果mysql沒有使用索引覆蓋查詢 就不得不查找索引中發現的每一行.
mysql能有為排序和查找行使用同樣的索引,如表 user 索引 (uid,birthday ) .
使用排序索引:

避免多余和重復索引
重復索引:類型相同,以同樣的順序在同樣的列創建索引,比如在表user id列 添加 unique(id)約束 、id not .
primary key 約束 index(id),其實這些是相同的索引 !
多余索引:如存在(A)索引 應該擴展它 滿足 (A,B)索引
(A,B)索引 <==> (B)
(A,B)索引 <==> (A)
(A,B) A最左前綴 (B,A) B最左前綴
索引實例研究
設計user表 字段:country、 state/region 、city 、sex 、age 、eye 、color 功能:支持組合條件搜索用戶 支持用戶排序 用戶上次在線時間
支持多種過濾條件
不在選擇性很差的列添加索引
優化排序

索引和表維護
表維護三個目標:查找和修復損壞、維護精確的索引統計,并減少碎片
查找并修復表損壞
check table 命令:確定表是否損壞,能抓到大部分表和索引錯誤
repair table 命令:修復損壞的表
myisamchk :離線修復工具
更新索引統計
analyze table cs_area 更新索引統計信息,便于優化器優化sql
show index 命令檢查索引的基數性

減少索引和數據碎片
myisam引擎 使用 optimize table 清除碎片 Innodb 引擎 使用 alter table .. engine = .. 重新創建索引
正則化和非正則化
正則化和非正則化
正則化數據庫:每個因素只會表達一次,教師表teacher (id,school_id), 學校表school
(school_id,school_name) 優點:更新信息只變動一張表 缺點:簡單的學校名稱查詢 需要關聯表
非正則化數據庫:信息是重復的 或者 保存在多個地方
教師表teacher (id,school_id,school_name) 學校表school (school_id,school_name)
優點:便于直接統計對應學校名稱的老師
缺點:更新需要變動的表多一張
正則化和非正則化并用:比如需要統計用戶的發帖數 可以在user表添加字段num_message 保存發帖總數 避免高密度查詢統計
緩存和匯總表
實例:統計過去24小時發布的信息精確的數量
表周期性創建
周期創建可以得到沒有碎片和全排序索引的高效表
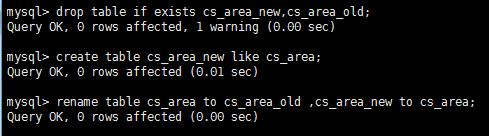
注意:此法會將數據清除,只是得到一個沒有碎片和高效的索引表.
計數表:比如緩存用戶朋友數量、文件下載次數 通常建立一個單獨的表,以保持快速維護計數器.
計劃任務定期聚合函數查詢,更新對應的字段.
近期熱文(點擊標題可閱讀全文)
近期活動:
Gdevops全球敏捷運維峰會北京站

峰會官網:www.gdevops.com
《MySQL架構優化實戰系列1:數據類型與索引調優全解析》是否對您有啟發,歡迎查看更多與《MySQL架構優化實戰系列1:數據類型與索引調優全解析》相關教程,學精學透。維易PHP學院為您提供精彩教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/7829.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
