Terark 聯合 MongoDB改進WiredTiger
《Terark 聯合 MongoDB改進WiredTiger》要點:
本文介紹了Terark 聯合 MongoDB改進WiredTiger,希望對您有用。如果有疑問,可以聯系我們。
相關主題:非關系型數據庫
歡迎參與《Terark 聯合 MongoDB改進WiredTiger》討論,分享您的想法,維易PHP學院為您提供專業教程。
2017-09-13 雷鵬 Terark實驗室
?
1.
背景
WiredTiger 是 KeyValue 存儲引擎,它最大的應用場景是作為 MongoDB 的默認存儲引擎,同時 MongoDB 對 WiredTiger 性能改進的探索也從未停止,于是,TerarkDB 以卓越的性能和壓縮率而獲得了 MongoDB 的興趣……
鑒于 TerarkDB 是 Terark 核心算法對 RocksDB 的適配,理論上相同的算法也可以用于 WiredTiger,我們經過一段時間的緊密開發,實現了第一個測試版本,期間 WiredTiger 的作者提供了大力的支持,在這里我們跟大家分享一下開發的經歷與成果.
2.
WiredTiger 和 LSM
WiredTiger 本身支持 BTree 和 LSM ( Log-Structured Merge Trees ) 兩種數據結構進行數據存儲,用戶通常可以根據自己的需求進行選擇.
2.1. BTree
BTree 讀性能優良.但是在寫壓力較大的情況下,性能會下降的較為嚴重:
BTree 的寫放大很嚴重:很少量的寫就會引起整頁被重新寫入磁盤,假定一個頁包含 200 條記錄,其中有 2 條被修改,當該頁被換出時,就需要將整個頁都寫入磁盤/SSD,象這樣 2 條數據修改導致 200 條數據被寫入磁盤,其寫放大就是 100 倍.
這在 SSD 上導致了更加嚴重的后果:因為 SSD 的壽命取決于寫次數,頻繁寫入會大幅降低 SSD 的壽命.
2.2. Log-Structured Merge Trees
LSM 是一個針對寫而進行了優化的數據結構,一個 LSM 在物理層面由多個子片段組成,其中最近被更新的那個片段存在于內存中,其余的以文件的方式存儲在磁盤中,當內存片段達到閾值時會被持久化成文件,同時產生一個新的內存片段用于寫操作.
這里,通過將所有的寫操作以追加的方式寫到內存中,就規避了 BTree 中出現的寫一條數據往往需要先讀磁盤,然后修改,然后再寫回磁盤的弊端.只需要在達到閾值時一次性的 flush 即可.
當然,LSM 也有它自己的弊端,寫的優化伴隨著讀性能的下降.簡單追加寫的方式意味著子片段之間可能會有數據的重疊,查詢也就往往需要讀取多個子片段才能返回有效的結果.LSM 通過后臺線程對已有數據進行 compact 來解決(緩解)這個問題.
3.
WiredTiger 接口層
WiredTiger 提供了一套回調接口以方便用戶按照自己的需求去定制底層的數據存取.例如,LSM 的每一個子文件,數據是按照 BTree 的方式進行存取的.熟悉 LevelDB / RocksDB 的同學可以通過回調實現一份以 Block Based 為組成文件的 LSM,和 原生的 BTree 比較一下性能.
WiredTiger 的回調接口如下:
static WT_DATA_SOURCE my_dsrc = {
alter,
create,
compact,
drop,
open_cursor, // *
rename,
salvage,
truncate,
range_truncate,
verify,
checkpoint,
terminate
};
error_check(conn->add_data_source(conn, "dsrc:", &my_dsrc, NULL));
回調里包含了創建、刪除、重命名、停止等函數.這里需要注意標 * 的 open_cursor 回調,用戶程序對 wt 的訪問,是統一經由抽象的 cursor 來實現的.
WiredTiger 的內部也遍布了 cursor 的調用,所以要重載數據存儲實現,cursor 相關的操作也不可避免:
WT_CURSOR::close
WT_CURSOR::next
WT_CURSOR::prev
WT_CURSOR::reset
WT_CURSOR::search
WT_CURSOR::search_near
WT_CURSOR::insert
WT_CURSOR::update
WT_CURSOR::remove
4.
將 Terark 算法集成進 WiredTiger
基于上面的理由,我們為 LSM 實現了一個 TerarkZipTable 數據源,把我們的可檢索壓縮算法嵌入到 WiredTiger 中.
4.1. LSM-Chunk
LSM-chunk (在WiredTiger語境里,LSM-file 以 chunk 來指代)或者是由內存數據轉化而成,或者是由若干個 chunk 通過 compact 生成.無論哪種方式,遍歷源數據都是必不可少的.為了實現高壓縮率和可檢索壓縮,Terark-chunk 需要遍歷源數據二次,對比原生的 LSM-chunk 只需要遍歷一次.這里的差異,可以簡單理解為Terark需要第一遍收集全局信息,為壓縮做準備,第二遍執行壓縮.
4.2. 重載粒度
需要強調的是,WiredTiger 的數據源含義較為寬泛,它可以是 LSM,也可以是組成 LSM 的子文件即 LSM-chunk.
我們這里重載的,是 LSM-chunk,涉及到 LSM 層面的 Merge , Checkpoint 是未受影響的.
4.3. 來自 WiredTiger 官方的協助
在整個修改過程中,WiredTiger 本身也有一些需要調整和修改的地方,為此 WiredTiger 在一個新分支上與我們進行協作:
1. 為了支持兩次遍歷,WiredTiger 為我們提供了一個額外的接口;
2. LSM-chunk 默認是以 BTree 方式實現的并在幾處代碼內寫死了,新分支已經修復;
3. WiredTiger 內部是按照名稱前綴來判斷數據類型的,LSM-chunk 對應的前綴是 BTree 通用的 file:,不巧有幾處也寫死了,新分支已修復;
4. LSM-chunk 默認需要生成 Bloom Filter 文件以提高查找效率,而 Terark 并不需要該文件,新分支目前正在修改,但不影響我們的測試;
5. 為了保證 Transaction 相關操作不受影響,WiredTiger 內存駐留的 LSM-chunk 仍然以 BTree 方式存在,其他的 chunk 可以通過重載 data-source 來實現,新分支已改;
6. 經過我們的提議,WiredTiger 新增了一個 cursor 選項(unpositioned),該選項指示 CURSOR::search 不要保留 cursor 位置
1)之前 WiredTiger 的 CURSOR::search 在搜索成功時總會保留 cursor 的位置;
2)而維護 cursor 位置的搜索已由接口 CURSOR::search_near 提供完美支持;
3)對于 TerarkZipTable,保留 cursor 位置是一筆不小的開銷
無 unpositioned 選項時,TerarkZipTable 通過投機方法來減小這種開銷;
有 unpositioned 選項時,就可以完全避免這種不必要的開銷.
4.4. TerarkDB 不需要 Bloom Filter
Bloom Filter 用來做否定測試,也就是說,如果 Bloom Filter 搜索 Key 失敗,則該 Key 一定不存在,如果 Bloom Filter 搜索成功,該 Key 可能存在,也可能不存在.
Bloom Filter 的優點是占用空間很小(一般情況下平均每個 Key 1~2 字節),搜索速度又很快,當然缺點就是它只能確認 Key 不存在.
傳統 SST 使用 Bloom Filter 來加速高層 Level 中 SST 的搜索.
高層(Level 值更小的 Level)的數據尺寸更小,并且都是新數據,訪問更頻繁,未命中的概率更高,而傳統索引搜索速度較慢,內存占用高,所以,用 Bloom Filter 可以實現很好的加速效果,并且相對內存占用較低.
然而,Terark SST 用了 CO-Index,CO-Index 的壓縮率和性能都非常高,和 Bloom Filter 相比,甚至在很多情況下空間和搜索性能同時占優,而且還是確定性的搜索(存在就是存在,不存在就是不存在),所以 Terark SST 就完全舍棄了 Bloom Filter.
4.5. 實現接口
WT_DATA_SOURCE
trk_create
trk_drop
trk_open_cursor
trk_pre_merge // *
這里的 trk_pre_merge 是 WiredTiger 官方提供的新的接口,用來供 Terark 實現兩次遍歷.
WT_CURSOR @ building
trk_builder_cursor_insert
trk_builder_cursor_close
trk_builder_cursor_reset
WT_CURSOR @ reading
trk_reader_cursor_next
trk_reader_cursor_prev
trk_reader_cursor_search
trk_reader_cursor_search_near
trk_reader_cursor_close
trk_reader_cursor_reset
上面的接口顯示,每個 chunk 按功用可以劃分為兩個階段:構建和查詢.
構建階段的 chunk 不需要提供 search 相關的功能,此時對應的回調可以設置為 NULL;同理,一旦 chunk 構建完畢,它就是 immutable 的,不需要考慮 insert 相關的操作.所以這里的 cursor 按照 chunk 的生命期拆分為兩組.
需要留心的有以下幾點:
初始化的 cursor 可以立即調用 next(),此時是從頭開始正向遍歷;
初始化的 cursor 可以立即調用 prev() ,此時是從尾開始反向遍歷;
search()對應的是精確查找,search_near()對應的是類 lower_bound() 的查找;
5.
初步的集成測試結果
5.1. 測試環境
CPU: Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz x2 (共16核32線程)
內存: DDR4 1866 MHz(共192G)
SSD: INTEL 730 IOPS 89000
CentOS Linux release 7.3.1611 (Core)
5.2. 測試數據
測試程序使用的是我們自己開發的測試工具: terarkdb-tests
測試數據使用了 Wikipedia,原始數據約 103 GB
5.3. 測試準備
分別使用原生 wiredtiger-with-snappy 和 適配了 terark-as-data-source 的 引擎,灌入上文提到的數據,總大小102G . 數據的前3列合并作為 key, 剩余的字段作為 value.
原生 wiredtiger 生成的數據集大小是 62G,其中 bloom-filter 文件 0.1G,數據文件 62G .
適配 terark 生成的數據集大小是 23G,因為是可檢索壓縮,所以不需要 bloom-filter.
原生 WiredTiger 配置:
wiredtiger_open
(
db
=./
wiredtigerdb_lsm
,
conf
=
create
,
cache_size
=
137438953472
,
log
=(
enabled
,
recover
=
on
),
checkpoint
=(
log_size
=
64MB
,
wait
=
60
),
lsm_manager
=(
worker_thread_max
=
8
),
extensions
=[
libwiredtiger_snappy
.
so
])
session
->
create
(
uri
=
lsm
:
dbbench_wt
-
0
,
conf
=
key_format
=
S
,
value_format
=
S
,
checksum
=
off
,
internal_page_max
=
128K
,
leaf_page_max
=
16K
,
type
=
lsm
,
os_cache_dirty_max
=
16MB
,
lsm
=(
bloom_config
=(
leaf_page_max
=
8MB
),
bloom_bit_count
=
28
,
bloom_hash_count
=
19
,
bloom_oldest
=
true
,
chunk_max
=
40GB
,
chunk_size
=
100MB
,
merge_min
=
2
),
block_compressor
=
snappy
)
修改版配置:
wiredtiger_open
(
db
=./
wiredtigerdb_terark
,
conf
=
create
,
cache_size
=
34359738368
,
log
=(
enabled
,
recover
=
on
),
checkpoint
=(
log_size
=
64MB
,
wait
=
60
),
lsm_manager
=(
worker_thread_max
=
8
),
extensions
=[
libwiredtiger_snappy
.
so
])
session
->
create
(
uri
=
lsm
:
dbbench_wt
-
0
,
conf
=
key_format
=
S
,
value_format
=
S
,
checksum
=
off
,
internal_page_max
=
128K
,
leaf_page_max
=
16K
,
type
=
lsm
,
os_cache_dirty_max
=
16MB
,
lsm
=(
bloom_config
=(
leaf_page_max
=
8MB
),
bloom_bit_count
=
28
,
bloom_hash_count
=
19
,
bloom_oldest
=
true
,
chunk_max
=
20GB
,
chunk_size
=
500MB
,
merge_min
=
2
,
merge_custom
=(
prefix
=
terark
,
start_generation
=
2
,
suffix
=.
trk
)))
補充說明:
WiredTiger 會在 level0 和 level1 產生原生的 lsm-chunk, level2 及以上的層級才會產生 terark-chunk.在本測試中,完成 compact 后所有 chunk 都轉為了 terark-chunk.這里的 bloom_filter 只作用于初期的 lsm-chunk 而不作用于 terark-chunk.
5.4. 測試用例
壓縮率在上面已經對比很明顯了,對于不同用例下,壓縮率是不變的(23 GB vs. 62 GB).
剩下的測試主要是在給定時間內,重復進行隨機訪問.
key 提取于原文件,保證查詢都會命中.這里要說明的是,key 文件有 1.2G 大小,因為是同一臺機子上測試,可以認為測試程序自身會占用約 2G 大小的空間.
限制內存方面,
原生 wiredtiger 通過設置內核參數,以限制物理內存的方式完成;
適配了 terark 的經由 cgroup 完成;
二者方式不同在于原生 wiredtiger 間接使用的系統緩存是無法通過 cgroup 限制的.
5.4.1. 不限內存
不限制內存的情況下,原生WT會使用非常多的內存,實際場景中幾乎不存在數據能全部裝入內存的情況.
原生WiredTiger(約100萬QPS):
?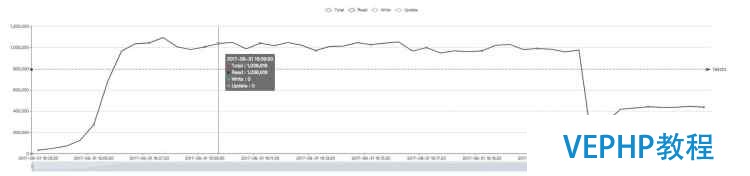 ?
?
修改版WiredTiger(約122萬QPS):
?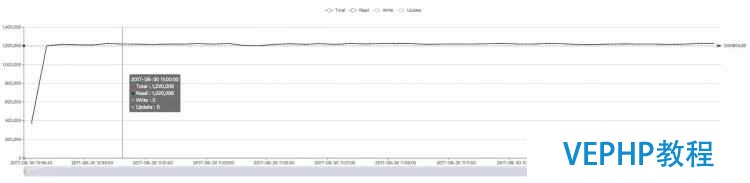 ?
?
注:Terark 版本的波動很小是因為初始時有內存預熱,數據駐留在內存后不會 eviction.
5.4.2. 內存限制 27G
在這種情況下,Terark 版的 WT 可以完全裝入內存,而原生的對內存需求太大,無法完全裝入,性能差距明顯(此時 Terark 版本的數據總尺寸約為 23 GB)
原生 WiredTiger(約1.3萬):
?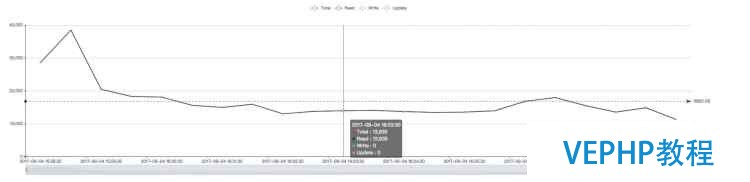 ?
?
修改版 WiredTiger (和不限內存保持一致,即122萬左右):
?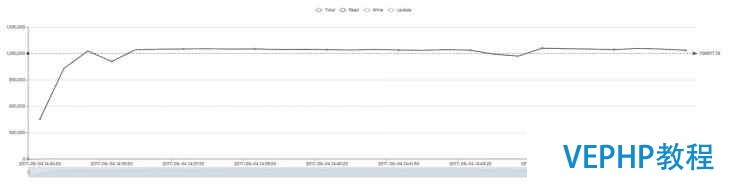 ?
?
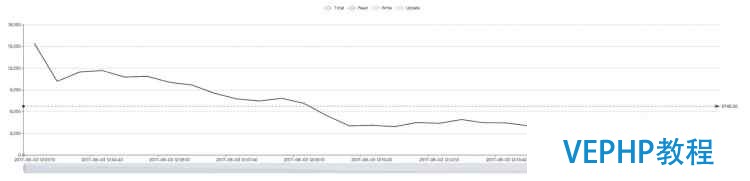
5.4.3. 內存限制為12G
注:鑒于 terark 生成的數據集大小 23G,12G 的測試就是為了測試當數據集大于內存時的效果.
原生 WiredTiger(約6700):
? ?
?
此處原本的 WiredTiger 在 12G 內存下和 27G 下的性能曲線都是先高后低.
我們的理解是初期 WiredTiger 的 DBCache 還未填滿(默認值是物理內存的一半),這部分內存就被系統緩存用了,從而大量的已壓縮數據塊存在于系統緩存中,系統緩存的命中率就比較高,從而性能較好.
隨著時間的推進,wiredtiger 不斷申請新的內存,系統會犧牲系統緩存,優先保證進程的內存要求,直到把 DBCache 填滿(達到 DBCache 上限,即物理內存的一半),此時 DBCache 內有大量已解壓的數據,在相同的內存中,存放壓縮的數據和已解壓的數據,已解壓的數據必然只能存放得更少,而系統緩存中有沒有多少存量,從而整體上減小了 Cache 命中率,進而頻繁的 IO 導致曲線轉而向下.
這也說明在 IO 能力不足時,增大系統緩存比增大 DBCache 更能獲得性能的提升,我們相信,如果這里使用的是 PCIe 的高端 SSD,情況會很不一樣.
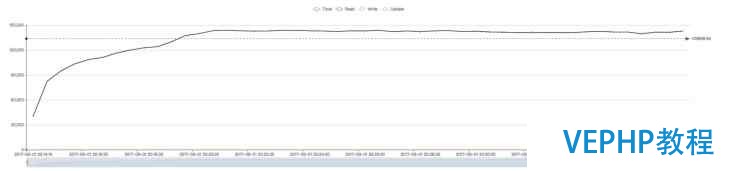
修改版 WiredTiger(約14萬):
? ?
?
6.
總結
目前和 MongoDB 官方的合作還在繼續,我們期待未來 MongoDB 的用戶能夠使用上 Terark 的技術,在 OLTP 領域能夠獲得更好的性能,更低的成本.
同時也非常期待能夠和其他數據庫廠商產生深度合作,把中國的技術推向世界.
?
Terark 專注于存儲引擎的研發
提供領先的數據庫和存儲系統優化服務
搜索 "Terark" 了解更多
聯系我們:contact@terark.com
?
Terark 實 驗 室
