Mysql必讀使用FriendFeed來提升MySQL性能的方法
《Mysql必讀使用FriendFeed來提升MySQL性能的方法》要點:
本文介紹了Mysql必讀使用FriendFeed來提升MySQL性能的方法,希望對您有用。如果有疑問,可以聯系我們。
MYSQL入門?配景
MYSQL入門我們使用MySQL存儲了FriendFeed的所有數據.數據庫隨著用戶基數的增長而增長了很多.現在已經存儲了超過2.5億條記錄與一堆涵蓋了從評論和“喜歡”到好友列表的其他數據.
MYSQL入門隨著數據的增長,我們也曾迭代地辦理了隨著如此迅猛的增長而帶來的擴展性問題.我們的嘗試很有代表性,例如使用只讀mysql從節點和memcache來增加讀取吞吐量,對數據庫進行分片來提高寫入吞吐量.然而,隨著業務的增長,添加新功能比擴展既有功能以迎合更多的流量變得更加困難.
MYSQL入門
特別的,對 schema 做改動或為超過 1000-2000 萬行記錄的數據庫添加索引會將數據庫鎖住幾個小時.刪除舊索引也要占用這么多時間,但不刪除它們會影響性能;因為數據庫要持續地在每個INSERT上讀寫這些沒用的區塊,并將重要的區塊擠出了內存.為避免這些問題需要采取一些復雜的措施(例如在從節點上設置新的索引,然后將從節點與主節點對調),但這些措施會引發錯誤并且實施起來比擬困難,它們阻礙了需要改動 schema/索引才能實現的新功能.由于數據庫的嚴重分散,MySQL 的關系特性(如join)對我們沒用,所以我們決定脫離 RDBMS.
MYSQL入門
雖然已有許多用于辦理靈活 schema 數據存儲和運行時構建索引的問題(例如 CouchDB)的項目.但在大站點中卻沒有足夠廣泛地用到來說服人們使用.在我們看到和運行的測試中,這些項目要么不穩定,要么缺乏足夠的測試(參見這個有點過時的關于 CouchDB 的文章).MySQL 不錯,它不會損壞數據;復制也沒問題,我們已經了解了它的局限.我們喜歡將 MySQL 用于存儲,僅僅是非關系型的存儲.
MYSQL入門幾經思量,我們決定在 MySQL 上采用一種無模式的存儲系統,而不是使用一個完全沒接觸過的存儲系統.本文試圖描述這個系統的高級細節.我們很好奇其他大型網站是如何處理這些問題的,另外也希望我們完成的某些設計會對其他開發者有所贊助.
MYSQL入門綜述
MYSQL入門我們在數據庫中存儲的是無模式的屬性集(例如JSON對象或python字典).存儲的記錄只需一個名為id的16字節的UUID屬性.對數據庫而言實體的其他部分是不可見的.我們可以簡單地存入新屬性來改變schema(可以簡單理解為數據表中只有兩個字段:id,data;其中data存儲的是實體的屬性集).
MYSQL入門我們通過保留在不同表中的索引來檢索數據.如果想檢索每個實體中的三個屬性,我們就需要三個數據表-每個表用于檢索某一特定屬性.如果不想再用某一索引了,我們要在代碼中停止該索引對應表的寫操作,并可選地刪除那個表.如果想添加個新索引,只需要為該索引新建個MySQL表,并啟動一個進程異步地為該表添加索引數據(不影響運行中的服務).
MYSQL入門最終,雖然我們的數據表增多了,但添加和刪除索引卻變得簡單了.我們大力改善了添加索引數據的進程(我們稱之為“清潔工")使其在快速添加索引的同時不會影響站點.我們可以在一天內完成新屬性的保留和索引,并且我們不需要對調主從MySQL數據庫,也不需要任何其他可怕的操作.
MYSQL入門細節
MYSQL入門MySQL 使用表保留我們的實體,一個表就像這樣 :
?
MYSQL入門
CREATE TABLE entities (
added_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
id BINARY(16) NOT NULL,
updated TIMESTAMP NOT NULL,
body MEDIUMBLOB,
UNIQUE KEY (id),
KEY (updated)
) ENGINE=InnoDB;
MYSQL入門之所以使用 added_id 個字段是因為 InnoDB 按物理主鍵順序存儲數據,自增長主鍵確保新實例在磁盤上按順序寫到老實體之后,這樣有助于分區讀寫(相對老的實體,新實體往往讀操作更頻繁,因為 FriendFeed 的 pages 是按時間逆序排列).實體自己經 python 字典序列化后使用 zlib 壓縮存儲.
MYSQL入門索引單獨存在一張表里,如果要創建索引,我們創建一張新表存儲我們想要索引的數據分片的所有屬性.例如,一個 FriendFeed 實體通過看上去是這樣的:
?
MYSQL入門
{
"id": "71f0c4d2291844cca2df6f486e96e37c",
"user_id": "f48b0440ca0c4f66991c4d5f6a078eaf",
"feed_id": "f48b0440ca0c4f66991c4d5f6a078eaf",
"title": "We just launched a new backend system for FriendFeed!",
"link": "http://friendfeed.com/e/71f0c4d2-2918-44cc-a2df-6f486e96e37c",
"published": 1235697046,
"updated": 1235697046,
}
MYSQL入門我們索引實體的屬性 user_id,這樣我們可以渲染一個頁面,包括一個已提交用戶的所有屬性.我們的索引表看起來是這樣的:
MYSQL入門
CREATE TABLE index_user_id (
user_id BINARY(16) NOT NULL,
entity_id BINARY(16) NOT NULL UNIQUE,
PRIMARY KEY (user_id, entity_id)
) ENGINE=InnoDB;
MYSQL入門我們的數據存儲會自動為你維護索引,所以如果你要在我們存儲上述結構實體的數據存儲里開啟一個實例,你可以寫一段代碼(用 python):
?
MYSQL入門
user_id_index = friendfeed.datastore.Index(
table="index_user_id", properties=["user_id"], shard_on="user_id")
datastore = friendfeed.datastore.DataStore(
mysql_shards=["127.0.0.1:3306", "127.0.0.1:3307"],
indexes=[user_id_index])
new_entity = {
"id": binascii.a2b_hex("71f0c4d2291844cca2df6f486e96e37c"),
"user_id": binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"),
"feed_id": binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"),
"title": u"We just launched a new backend system for FriendFeed!",
"link": u"http://friendfeed.com/e/71f0c4d2-2918-44cc-a2df-6f486e96e37c",
"published": 1235697046,
"updated": 1235697046,
}
datastore.put(new_entity)
entity = datastore.get(binascii.a2b_hex("71f0c4d2291844cca2df6f486e96e37c"))
entity = user_id_index.get_all(datastore, user_id=binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"))
MYSQL入門上面的 Index 類在所有實體中查找 user_id,自動維護 index_user_id 表的索引.我們的數據庫是切分的,參數 shard_on 是用來確定索引是存儲在哪個分片上(這種情況下使用 entity["user_id"] % num_shards).
MYSQL入門你可以使用索引實例(見上面的 user_id_index.get_all)查詢一個索引,使用 python 寫的數據存儲代碼將表 index_user_id 和表 entities 合并.首先在所有數據庫分片中查詢表 index_user_id 獲取實體 ID 列,然后在 entities 提出數據.
MYSQL入門新建一個索引,好比,在屬性 link 上,我們可以創建一個新表:
?
MYSQL入門
CREATE TABLE index_link (
link VARCHAR(735) NOT NULL,
entity_id BINARY(16) NOT NULL UNIQUE,
PRIMARY KEY (link, entity_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
MYSQL入門我們可以修改數據存儲的初始化代碼以包括我們的新索引:
?
MYSQL入門
user_id_index = friendfeed.datastore.Index(
table="index_user_id", properties=["user_id"], shard_on="user_id")
link_index = friendfeed.datastore.Index(
table="index_link", properties=["link"], shard_on="link")
datastore = friendfeed.datastore.DataStore(
mysql_shards=["127.0.0.1:3306", "127.0.0.1:3307"],
indexes=[user_id_index, link_index])
MYSQL入門我可以異步構建索引(特別是實時傳輸服務):
?
MYSQL入門
./rundatastorecleaner.py --index=index_link
MYSQL入門一致性與原子性
MYSQL入門由于采用分區的數據庫,實體的索引可能存儲在與實體不同的分區中,這引起了一致性問題.如果進程在寫入所有索引表前瓦解了會怎樣?
MYSQL入門許多有野心的 FriendFeed 工程師傾向于構建一個事務性協議,但我們希望盡可能地堅持系統的簡潔.我們決定放寬限制:
- ??? 保留在主實體表中的屬性集是規范完整的
- ??? 索引不會對真實實體值產生影響
MYSQL入門因此,往數據庫中寫入實體時我們采用如下步驟:
- ??? 使用 InnoDB 的 ACID 屬性將實體寫入 entities 表.
- ??? 將索引寫入所有分區中的索引表.
MYSQL入門
我們要記住從索引表中取出的數據可能是不準確的(例如如果寫操作沒有完成步驟2可能會影響舊屬性值).為確保采用上面的限制能返回正確的實體,我們用索引表來決定要讀取哪些實體,但不要相信索引的完整性,要使用查詢條件對這些實體進行再過濾:
MYSQL入門1.根據查詢條件從索引表中取得 entity_id
MYSQL入門2.根據 entity_id 從 entities 表中讀取實體
MYSQL入門3.根據實體的真實屬性(用 Python)過濾掉不符合查詢條件的實體
MYSQL入門為保證索引的持久性和一致性,上文提到的“清潔工”進程要持續運行,寫入丟失的索引,清理失效的舊索引.它優先清理最近更新的實體,所以實際上維護索引的一致性非常快(幾秒鐘).
?
性能
MYSQL入門我們對新系統的主索引進行了優化,對結果也很滿意.以下是上個月 FriendFeed 頁面的加載延時統計圖(我們在前幾天啟動了新的后端,你可以根據延時的顯著回落找到那一天).
MYSQL入門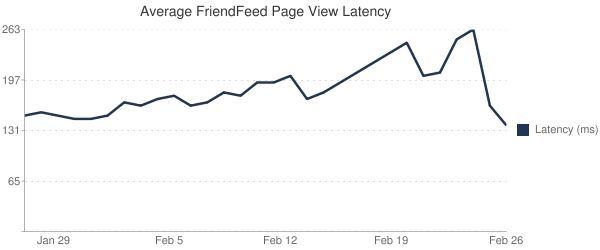
MYSQL入門特別地,系統的延時現在也很穩定(哪怕是在午高峰期間).如下是過去24小時FriendFeed頁面加載延時圖.
MYSQL入門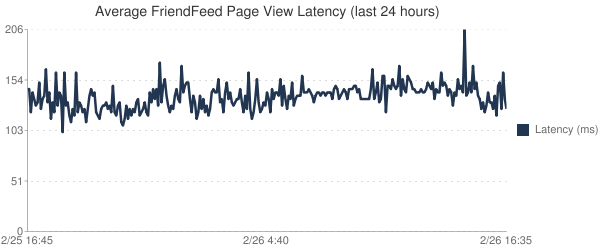
MYSQL入門與上周的某天相比擬:
MYSQL入門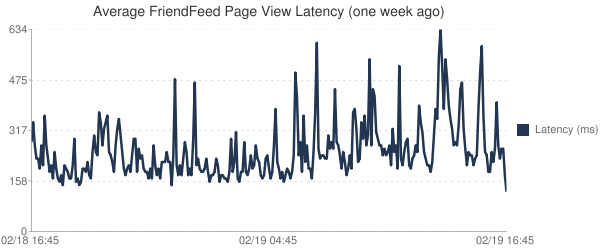
MYSQL入門系統到目前為止使用起來很便利.我們在部署之后也改動了幾次索引,并且我們也開始將這種模式應用于 MySQL 中那些較大的表,這樣我們在以后可以輕松地改動它們的結構.
《Mysql必讀使用FriendFeed來提升MySQL性能的方法》是否對您有啟發,歡迎查看更多與《Mysql必讀使用FriendFeed來提升MySQL性能的方法》相關教程,學精學透。維易PHP學院為您提供精彩教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/9846.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
