SDN實戰團分享(二十九):Microflow性能調優分享
《SDN實戰團分享(二十九):Microflow性能調優分享》要點:
本文介紹了SDN實戰團分享(二十九):Microflow性能調優分享,希望對您有用。如果有疑問,可以聯系我們。
編者按:本文系SDN實戰團技術分享系列,我們希望通過SDNLAB提供的平臺傳播知識,傳遞價值,歡迎加入我們的行列.
分享嘉賓
--------------------------------------------------------------------------------------------------
分享介紹:張攀:BII天地互連的工程師,在公司里負責SDN產品和技術的開發,同時在ONF、OPNFV、ONOS等社區也有大量尺度、開源,項目搭建等工作,目前在ONF擔任工作組的副主席.
Hello大家好,很高興可以在這里和大家分享一下我的個人開源項目Microflow的相關工作.
我是BII天地互連的工程師,在公司里負責SDN產品和技術的開發,同時在ONF、OPNFV、ONOS等社區也有大量尺度、開源,項目搭建等工作,目前在ONF擔任工作組的副主席.
因為之前在做SDN控制器性能測試的緣故,對目前主流的開源控制器的性能都做了一些定量的測評,結果顯示并不令人滿意.
上周的那個paper里也同樣認為當下控制器的性能是限制SDN網絡部署的瓶頸,雖說分析得并不全面,但也部分說明了現狀.
分析過CBench的源碼,也在公司帶領開發自己的測試工具,其實CBench的測試辦法,并不能恰當地模擬真實的網絡環境,給出的結果應當說還是明顯偏高的.
基于以上認識,起了念想要自己去做一個輕量、高效,同時又可以辦理切實問題的控制器.初衷并不是想要像時下流行的那般去改變什么,而更多的是對一次心血來潮的長久的珍視.
設計任何軟件當然首先是對架構的設計,在Microflow的實現過程中,主要側重的還是對性能優化的考慮.這一部分涉及一些硬件運行的原理,同時也參考了Nginx\redis\memcached\DPDK\Linux kernel的軟件設計.在接下來的分享里,我會首先介紹一下控制器的架構,然后重點介紹幾個性能優化的技術.最后簡要介紹一下Microflow的開發現狀和路線圖作為總結.
針對Microflow的架構調整過好幾版,實現了之后測一測,發現不太抱負于是棄掉重來.所有的調整均是出于性能和資源占用的考慮,務求達到簡潔高效可拓展的目的.當前的架構設計如下圖:
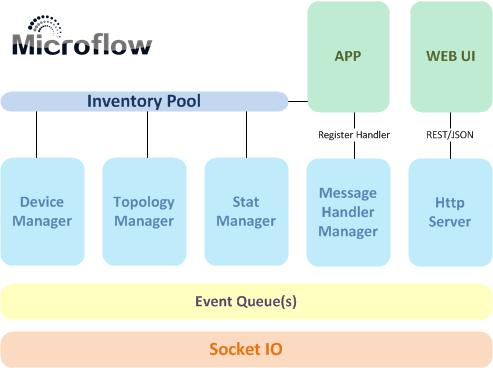
采用Epoll做socket的異步I/O,接收到的OpenFlow數據直接進入消息處理隊列.系統或上層APP注冊消息處理辦法,以響應特定事件.同時將設備信息、主機信息、拓撲信息統一管理和維護,為上層應用提供查詢、分析、計算等服務.另外集成一個HTTP的服務器提供WEB界面和REST的接口.
在線程設置方面,socket I/O由獨立的線程處理,消息處理(事件響應)由另外的線程負責,Microflow會處理各個線程與CPU的親和性關系,數量可以根據CPU核心數目調整(一般不超過核心數量),另有獨立的線程負責Timer/Log/HTTP哀求/等事務.
多線程的好處是可以充分利用多個CPU核心,但必然帶來競爭和死鎖等問題.在Microflow中,消息隊列,網絡資源的哈希表和儲存空間就都成了線程之間的共享內存,對共享內存的加鎖帶來的進程阻塞將成為新的性能瓶頸.在Microflow中對讀寫拜訪密集的內容都采用了無鎖化的處理,后面會有介紹.
下面介紹幾個Microflow采用的性能優化技術
性能優化的目標,就是伺候好CPU,讓它能愉快得滿速率運行.對CPU來說,它必要的無非是指令和數據.可以更快地取得數據(指令也是一種數據)去計算,可以用更精簡的指令完成計算任務,就是所有性能優化的目的.
最抱負的情況,就是CPU需要什么數據,什么數據就在它的緩存里.因為緩存和內存速度上的巨大差距,必須利用好CPU緩存.為了做到這一點,是需要一些巧妙的設計的.下面是一個現代計算機系統存儲讀寫速度量化比較:
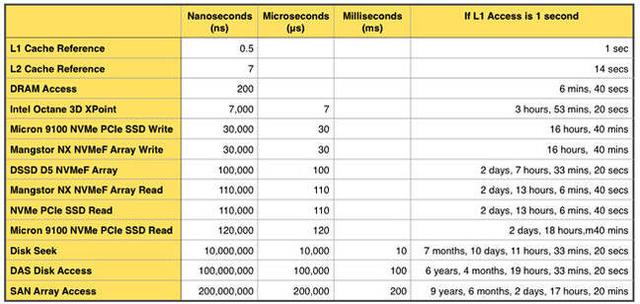
緩存和內存的讀寫速度相差數百倍, 將有用的數據寫入到緩存里便是成功的一半
先從CPU從內存取數據說起.給CPU一個內存地址和數據長度,它就會自動把數據加載到本身的緩存里了嗎?并不是這么簡單.在CPU看來,內存的數據是以4字節、8字節的”數據塊”存儲的.假設CPU需要一個4字節的數據,如果該數據的起始地址是4或8的倍數,那么CPU可以通過一次操作取得數據,但如果數據從地址0x1開始呢?如下圖:
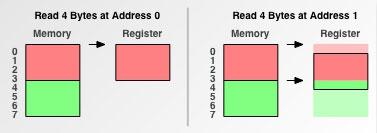
如果是這樣的話,CPU必要做很多額外的工作,才能從內存中取得該數據.第一步,讀取addr 0-3的數據;第二步,將該數據向左移動1位,第三步,讀取addr 4-7的數據,第四步,將該數據向右移動3位,第五步,將兩個移位后的數據合并成目標數據,如下圖:
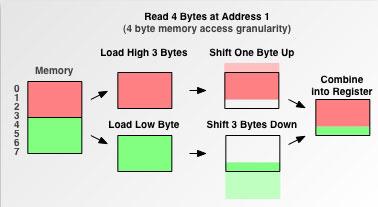
出于性能考慮,第二種情況是要盡量避免的.這也便是所謂的”內存按4字節對齊”.雖然更小字節的內存對齊可以帶來一些空間上面的壓縮,但在我們的場景下并沒有帶來任何邊際效益.
對于已經加載到緩存中的數據,也不是就此可以安枕無憂.CPU的緩存并不是以字節為單位,而是以一個Cache Line為單位.Intel的CPU Cache Line通常是64字節.在CPU從內存中讀取一個數據的時候,從這個數據開始的64字節的內容都會讀取到緩存中.
這在多線程環境下都會帶來影響,如果兩個線程分別操作的兩個數據相隔在64字節以內,比如隊列結構體的入隊和出隊指針,那么線程1在更新了入隊指針之后,為堅持數據的一致性,會導致拷貝了相同Cache Line,只操作出隊指針的線程2的緩存失效.線程2只能重新從主內存讀取出隊指針.這樣即便兩個線程在數據操作方面不存在競爭,但還是會互相影響,極大地提高Cache miss的概率,這種現象稱為False sharing.
一個簡單的辦法是在兩個指針之間添加Cache padding,即添加一個Cache Line長度的無用數據.這樣兩個指針就會出現在兩個不同的Cache Line之中,分別為兩個線程所用.因為前面提到的cache和內存的巨大的速度差異,用一組簡單的測試數據可以說明False sharing帶來的影響:
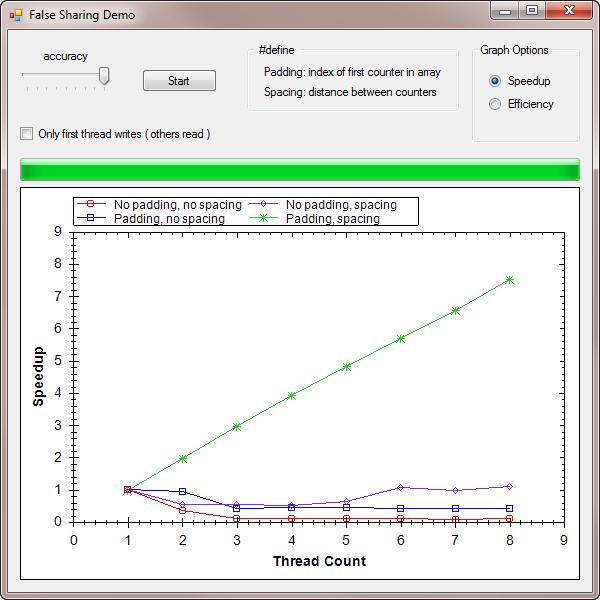
這個測試是,每個線程都在操作一個int數據,做簡單的自加從0至10M.在數據中可以看出,在8個線程的情況下,不發生False Sharing的執行效率(綠線)是發生False Sharing(紅線)的一百倍以上.
利用Cache Line的特性,也可以將某一個線程需要一起操作的數據支配到一起,進一步降低Cache Miss.當程序里某些結構體比較大的時候,也可以考慮把它分割成幾個較小的結構體,存在不同的Cache Line里面,也可以降低Cache Miss.
盡可能讓有用的數據留在Cache里優化性能的一個手段.對CPU來說,它的另外一個工作便是執行指令.CPU并不是簡單的按順序執行程序的指令,為了提高效率,它采用的是流水線的方式.即在執行當前指令的同時,獲取下一條指令.這樣下一個指令周期就可以直接執行下一條指令而不必再先去獲取.
如果程序一直按順序執行,那么CPU的流水線就會一直堅持滿負荷工作狀態.但在程序中不可避免的會遇到轉跳的情況,就是常見的那些if..else..語句.當前面的判斷指令還沒有執行完的時候,CPU的下一條指令是取if后的還是else后的?如果取錯,那么就需要在執行完判斷指令后清空整條流水線,重新加載第一個指令,拖慢整個程序的運行.
如果我們可以給CPU一些“指導”,告訴它是if后面的指令執行的概率大,還是else后面的指令執行的概率大,那么它就可以在流水線里預先獲取概率大的指令,從而盡可能地避免清空流水線對性能的影響,這便是被稱為“分支預測”的技術.
用一個簡單的例子說明一下分支預測帶來的性能提升.
兩組數據,各包括100K個整數,一組隨機排列,另外一組升序排列.要做的處理很簡單,遍歷全部數據,將所有大于128的整數相加求和.簡單表示一下: for data in array; if data > 128; sum+=data;
在執行判斷的時候,因為第一組數據完全隨機,所以無法預測是否大于128,流水線有必定概率被清空.而第二組數據可以預測在128之后的數據全部大于128,之前的全部小于.執行的指令都是一樣的,但因為流水線的問題,運行的效率相差6倍.詳細的測試代碼和結果可以參看這里:http://stackoverflow.com/questions/11227809/why-is-it-faster-to-process-a-sorted-array-than-an-unsorted-array
昨天我看到Facebook新開源的高性能壓縮算法Zstandard的介紹,里面也提到利用減少分支的辦法提升效率,它給出了一個while循環的例子.除此之外,一些簡單的if判斷可以用位操作的方式代替.比如返回兩個數中較大的數,除了if(x>y) return x; else return y;之外還可以max = x ^ ((x ^ y) & -(x https://graphics.stanford.edu/~seander/bithacks.html
目前的感覺是軟件性能調優必須得向硬件的方向上去靠(除了之前說的,還有NUMA等很多需要考慮的東西),或者優化Linux的內核(bypass socket/fast socket/huge page等等),單純的優化算法(除了特別適用于場景的)能起到的效果比擬有限.關于CPU的內容還有很多,限于篇幅這里就不再一一介紹,分享一篇比擬不錯的文章,有興趣的朋友可以自行深入:http://igoro.com/archive/gallery-of-processor-cache-effects/
在采用了內存對齊,Cache padding,分支預測等技術之后,測試了一下Microflow的Cache Miss rate,看一下執行最集中的函數:
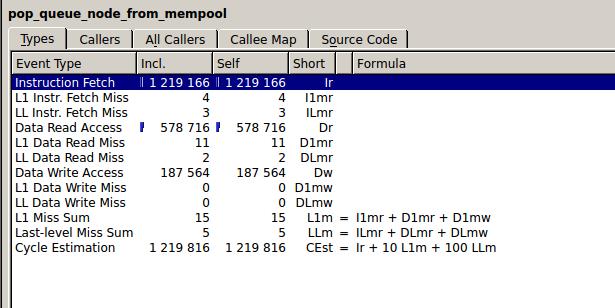
這是從消息隊列里讀取數據的函數,相當于所有數據包的入口.指令獲取1219K次,Miss 4次,讀數據578K次,Miss 11次, 寫數據187K次,Miss 0.
總體來看,Cache Miss主要發生在Kernel提供的函數里面..比如memset/memcpy等等..所以還是有提升空間的...現在因為時間有限,暫時不寫自己的wrapper函數,現在的辦法就是實現內存池,只在初始化的時候調用這些函數,盡量減少調用次數,還是有一些效果的...
在介紹完關于硬件的內容之后,軟件本身也有很多可以優化的內容,這個展開說可以說一天...在這里保舉一本書:Computer Systems: A Programmer's Perspective,里面就是在教各種如何寫高效的代碼.雖然在某些領域的深度并不夠,但勝在覆蓋面較廣.感興趣的朋友可以從網上下來看看.我在這里主要介紹一下Microflow里無鎖鏈表和哈希的實現.
首先想說明的是,鎖自己并不是降低多線程程序性能的原因,對鎖的集中爭奪才是.另外即便是號稱可以實現無鎖的”原子操作”也有它自己的cost,并不僅僅是CPU執行一個指令那么簡單.在這里并不想深入太多細節,總之我的經驗就是,無鎖并不一定快于有鎖,完全看具體應用的場景和需求.但在SDN控制器中,集中管控的網絡資源信息一定是各個線程爭搶的主要對象.所以實現無鎖的數據結構也就有了很大的現實意義.
現代很多程序為了提高效率都采用了內存池的設計.即在啟動的時候向內核申請一大塊內存,當程序需要內存儲存數據的時候,在用戶空間分配一小塊內存即可,而不必每次都去麻煩內核.Microflow也不例外,這樣做有很多好處,但用戶必需對分配的內存進行管理,最常見的就是將具有關聯數據的小內存塊用指針”連”起來,這也就是無鎖鏈表的工作.
鏈表主要的意義其實就是告訴你下一個元素在哪里,這樣只需要抓住鏈表的”頭”,就可以把整條鏈拎出來.好比局域網里的交換機數據可以組成一條鏈表,一條網絡路徑上的所有交換機可以組成一條鏈表,或是同一臺交換機上的端口數據可以組成一條鏈表,等等.
所以對鏈表來說,最關鍵的便是正確指向下一塊內存的地址.多線程的場景下,有可能多個線程都想去修改這個地址,就會產生競爭,一旦改錯,后面的數據就永遠丟失了.
一個方法就是用到被稱為”Compare-and-swap”(CAS)的原子操作.該操作的作用是,讀取一塊內存的值,并將它與某個值相比較,如果相同,就將這片內存的值替換為一個新值,如果不同,則維持原樣.所謂原子操作,就是當某線程在執行該操作的時候,CPU保證該操作不會被任何其他的線程打斷,無鎖就是靠此實現.
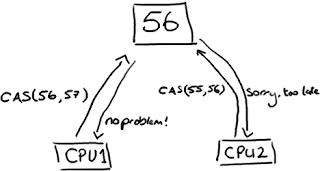
如上圖所示,兩個CPU都想去修改同一塊內存中的值,CPU1想要將56改為57,在圖示的情況下可以成功,而CPU2想要將55改為56,因為和現在內存上的值不相等(說明已經有其他線程更改過了),所以不會成功.對CPU2來說,必要重新讀取一下該內存的值,然后再執行一次CAS操作.
如果將56想象成鏈表的next指針,那么就可以利用CAS實現無鎖操作.簡單描述一下插入節點的操作:
首先新建節點(20),然后找到它要插入的位置,將它的next指針指向節點(30)
然后對節點10的next指針執行CAS操作,如果該指與操作前獲取到的next指針相同,則將它更新為節點20的地址.如果不同,說明有別的線程已經變動了next的值,則重新執行以上的操作,直至成功.如此可以完成鏈表的無鎖插入.
節點的刪除也是同樣.但刪除的時候存在一個問題:
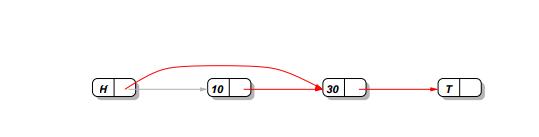
當我想要刪除節點10,我只必要將頭節點(H)的next指針指向節點10的next節點(30)即可,可以用CAS操作實現.
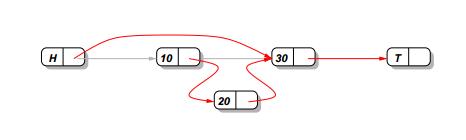
但如果此時有另外一個線程在如上圖的位置插入了節點20,那么最終的結果就是,頭結點還是指向了節點30,直接越過了節點20,即節點20的插入并沒有成功.
解決的辦法是為每一個鏈表節點結構增加了一個標志位.當要刪除某個節點的時候,先將該標志位置1,表示它已在邏輯上被刪除.而在插入的時候首先檢查前序節點的標志位是不是1,如果是1就重新查找一遍前序節點.這樣便可以避免以上的情況.
還是想強調一遍的是,無鎖并不必定快于有鎖,有鎖也有很多種類,互斥鎖,自旋鎖等等,它們的特性也各不相同,鎖的粒度等等也都可以調整,還是需要結合實際的需求來決定采取哪種方式.
至于哈希表,就直接利用了無鎖鏈表.每一個哈希桶都是一條這樣的鏈表.遇到碰撞的數據直接在鏈表的頭結點之后插入即可.這樣也就實現了無鎖哈希表.
OK,關于性能優化的技術就簡要介紹到這里.下面看一些控制器性能測試結果.Microflow運行的服務器CPU Intel E5-2609 v2 @ 2.50GHz 4核 /16GB 1600Mhz/Ubuntu 12.04,測試工具是OFsuite,跑在另外一臺服務器上.
首先測一下單socket針對包括有ARP報文的Packet_in消息,控制器回復Packet_out消息(廣播APR)的吞吐和時延:
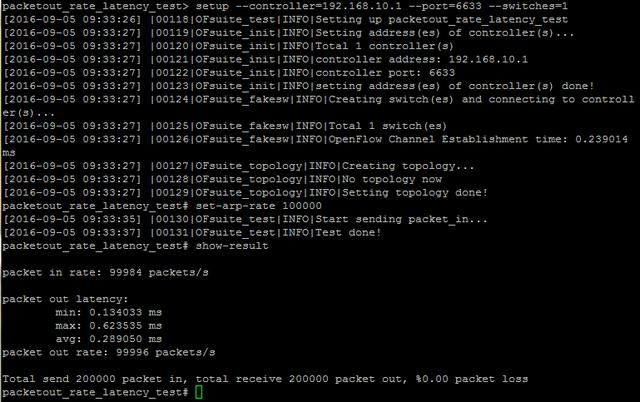
在單socket 100K pps的情況下,Microflow的最大時延是0.6ms,平均也就0.3ms左右.再來看一下拓撲發現的情況,500個交換機組成linear的拓撲,全部發現時間600多ms:
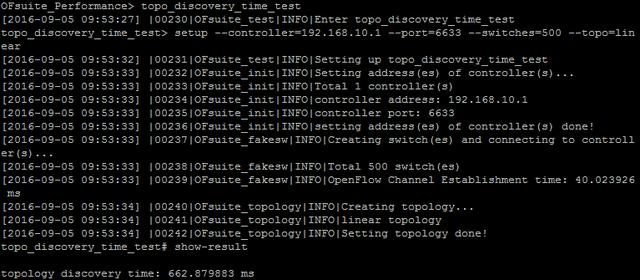
這里必要說一下的是,為什么不采用Cbench測試.Cbench首先是將700多個Packet_in數據包全部包入一個TCP的payload,組成一個最大長度的IP報文,然后通過loopback接口(默認MTU:65536)發給localhost控制器,然后看測試結果.這樣基本上沒有任何TCP和每一個數據包的Linux內核空間到用戶空間的拷貝的開銷,可以提升測試結果,但在現實中并沒有這種場景存在.而OFsuite是將可選數量的Packet_in封裝在單獨的TCP里面,通過以太接口恒速發給另外一臺服務器,這里使用的是每一個TCP單獨封裝一個Packet_in,最好地模擬了現實的網絡場景.
OFsuite還能測很多,流表下發速率鏈路建立時間什么的,不過還是比及Microflow實現了這些功能再說吧...
最后看一下Microflow的資源占用情況:
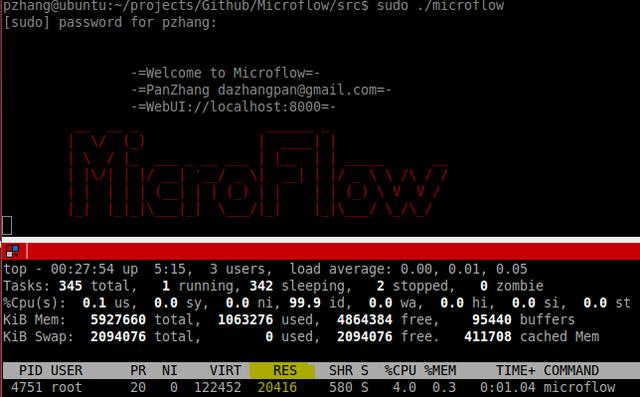
在初始化全部內存池,沒有處理數據包的情況下,物理內存、虛擬內存的占用情況,CPU占用率4%(輪詢數據隊列所致).在處理單socket 100K pps級別的數據哀求的時候,各個CPU核心的占用情況如下:
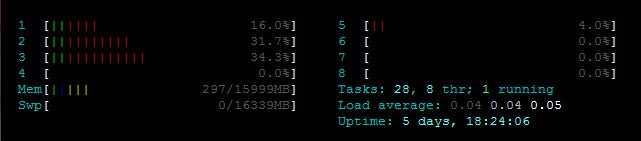
依照程序里CPU親和性的設置,CORE 1是處理Epoll I/O的核心,CORE 2和3是處理事件的核心(這里只開了兩個處理線程,程序里可以配置再開幾個).每個占用率在30%左右.看來單socket 100Kpps還遠不是Microflow的極限,但后面受限于Linux本身(TCP window size/recv buffer size等),沒有再提速測試...畢竟是工作時間在公司的服務器上..
由于其輕量級,高性能的特性,Microflow未來可能在SDN+IoT,智能家庭,工業互聯網、車聯網等嵌入式設備為主流的領域找到用武之地,當然有人愿意在數據中心部署也歡迎 XD
目前開發的進度還算可以,眼下需要完成的是拓撲計算,流表下發和統計搜集的功能,這樣至少可以先建立端到端的路徑,同時做好與WEB UI的交互,實現underlay資源的實時可視化.接下來我計劃重點開發一下集群功能,不打算應用目前主流的開源集群架構,而是仿照FPS游戲的同步機制本身實現,主要還是對開放了源代碼的Quake 3這款游戲有比較深的感情 :p
當然也不一定就是這樣了,原來就是為了填補一下業余生活,也許下面我會重點美化一下WEB界面,以后改行做前端了也說不定 不過這個項目我肯定是會繼續完善下去的,雖然可能從始至終都是我一個人的自娛自樂,但我也不想去提什么”功不唐捐”這一類的陳詞濫調,我只是想證明,沖動并不僅僅是魔鬼,“一時的沖動”也不一定就只能“釀成大錯”,反而它恰恰應該是被我們珍視的東西,因為我知道,它會帶我們去到我們要去的地方,也許所有的啟程,都是一次蓄謀已久的心血來潮.
關于Microflow就介紹這些,謝謝大家!補充一下源碼地址:Http://github.com/PanZhangg/Microflow
-------------------------------------------------------------------------- SDN實戰團微信群由Brocade中國區CTO張宇峰領銜組織創立,攜手SDN Lab以及海表里SDN/NFV/云計算產學研生態系統相關領域實戰技術牛,每周都會組織定向的技術及業界動態分享,歡迎感興趣的同學加微信:eigenswing,進群參與,您有想聽的話題可以給我們留言.
《SDN實戰團分享(二十九):Microflow性能調優分享》是否對您有啟發,歡迎查看更多與《SDN實戰團分享(二十九):Microflow性能調優分享》相關教程,學精學透。維易PHP學院為您提供精彩教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/8689.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
