簡單MySQL教程二
《簡單MySQL教程二》要點:
本文介紹了簡單MySQL教程二,希望對您有用。如果有疑問,可以聯系我們。
一、7中join查詢
1、Join圖
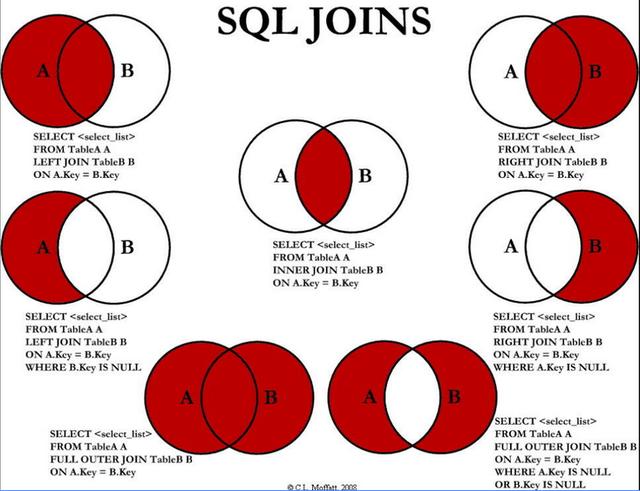
2、建表語句
CREATE TABLE `tbl_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`locAdd` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `tbl_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `tbl_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_dept(deptName,locAdd) VALUES('RD',11);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('HR',12);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MK',13);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MIS',14);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('FD',15);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z3',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z4',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z5',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w5',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w6',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s7',3);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s8',4);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s9',51);
3、7種join語句
1 A、B兩表共有
select * from tbl_emp a inner join tbl_dept b on a.deptId = b.id;
2 A、B兩表共有+A的獨有
select * from tbl_emp a left join tbl_dept b on a.deptId = b.id;
3 A、B兩表共有+B的獨有
select * from tbl_emp a right join tbl_dept b on a.deptId = b.id;
4 A的獨有
select * from tbl_emp a left join tbl_dept b on a.deptId = b.id where b.id is null;
5 B的獨有
select * from tbl_emp a right join tbl_dept b on a.deptId = b.id where a.deptId is null; #B的獨有
6 AB全有
#MySQL Full Join的實現 因為MySQL不支持FULL JOIN,下面是替代辦法
#left join + union(可去除重復數據)+ right join
SELECT * FROM tbl_emp A LEFT JOIN tbl_dept B ON A.deptId = B.id
UNION
SELECT * FROM tbl_emp A RIGHT JOIN tbl_dept B ON A.deptId = B.id
7 A的獨有+B的獨有
SELECT * FROM tbl_emp A LEFT JOIN tbl_dept B ON A.deptId = B.id WHERE B.`id` IS NULL
UNION
SELECT * FROM tbl_emp A RIGHT JOIN tbl_dept B ON A.deptId = B.id WHERE A.`deptId` IS NULL;
二、索引簡介
1、官方定義
索引(Index)是贊助MySQL高效獲取數據的數據結構.
可以得到索引的本質:索引是數據結構.
2、排好序的快速查找數據結構
在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種特定方式指向數據.
這樣就可以在這些數據結構上實現高級查找算法,這些數據結構就是索引.如下圖:
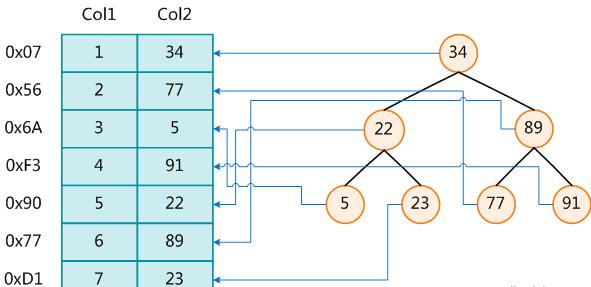
左邊是數據表,一共有兩列七條記錄,最左邊的是數據記錄的物理地址
為了加快Col2的查找,可以維護一個右邊所示的二叉查找樹,每個節點分別包括索引鍵值和一個指向對應數據記錄物理地址的指針,這樣就可以運用二叉查找在一定的復雜度內獲取到相應數據,從而快速的檢索出符合條件的記錄.
3、我們平常所說的索引,如果沒有特別指明,都是指B樹(多路搜索樹,并不一定是二叉的)結構組織的索引.其中聚集索引,次要索引,覆蓋索引,復合索引,前綴索引,唯一索引默認都是使用B+樹索引,統稱索引.當然,除了B+樹這種類型的索引之外,還有哈稀索引(hash index)等.
4、優勢
提高數據檢索的效率,降低數據庫IO成本.
通過索引列對數據進行排序,降低數據排序的成本,降低了CPU的消耗.
5、劣勢
雖然索引大大提高了查詢速度,同時卻會降低更新表的速度,如對表進行INSERT、UPDATE和DELETE. 因為更新表時,MySQL不僅要保存數據,還要保存一下索引文件每次更新添加了索引列的字段, 都會調整因為更新所帶來的鍵值變化后的索引信息.
6、索引分類
單值索引
一個索引只包括單個列,一個表可以有多個單列索引.
復合索引
一個索引包括多個列.
唯一索引
索引列的值必須唯一,但可以有空值.
7、基本語法
創建
CREATE [UNIQUE ] INDEX indexName ON mytable(columnname(length));
ALTER mytable ADD [UNIQUE ] INDEX [indexName] ON (columnname(length));
注意:如果是CHAR,VARCHAR類型,length可以小于字段實際長度; 如果是BLOB和TEXT類型,必須指定length.
刪除
DROP INDEX [indexName] ON mytable;
查看
SHOW INDEX FROM table_name\G;
使用ALTER命令創建索引
有四種方式來添加數據表的索引:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 該語句添加一個主鍵,這意味著索引值必須是唯一的,且不能為NULL.
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 這條語句創建索引的值必須是唯一的(除了NULL外,NULL可能會出現多次).
ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出現多次.
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):該語句指定了索引為 FULLTEXT ,用于全文索引.
8、mysql索引結構
BTree索引原理
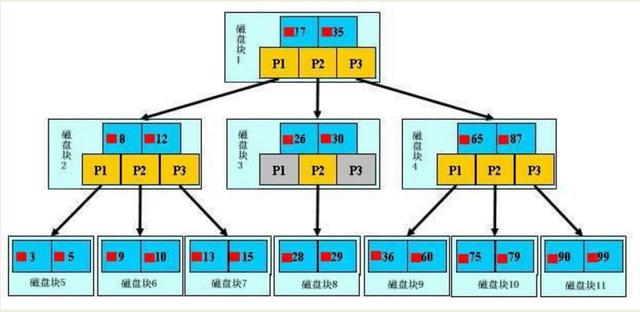
【初始化介紹】
一顆b+樹,淺藍色的塊我們稱之為一個磁盤塊,可以看到每個磁盤塊包括幾個數據項(深藍色所示)和指針(黃色所示),
如磁盤塊1包括數據項17和35,包括指針P1、P2、P3,
P1表示小于17的磁盤塊,P2表示在17和35之間的磁盤塊,P3表示大于35的磁盤塊.
真實的數據存在于葉子節點即3、5、9、10、13、15、28、29、36、60、75、79、90、99.
非葉子節點不存儲真實的數據,只存儲指引搜索方向的數據項,如17、35并不真實存在于數據表中.
【查找過程】
如果要查找數據項29,那么首先會把磁盤塊1由磁盤加載到內存,此時發生一次IO,在內存中用二分查找確定29在17和35之間,鎖定磁盤塊1的P2指針,內存時間因為非常短(相比磁盤的IO)可以忽略不計,通過磁盤塊1的P2指針的磁盤地址把磁盤塊3由磁盤加載到內存,發生第二次IO,29在26和30之間,鎖定磁盤塊3的P2指針,通過指針加載磁盤塊8到內存,發生第三次IO,同時內存中做二分查找找到29,結束查詢,總計三次IO.
真實的情況是,3層的b+樹可以表示上百萬的數據,如果上百萬的數據查找只需要三次IO,性能提高將是巨大的,如果沒有索引,每個數據項都要發生一次IO,那么總共需要百萬次的IO,顯然成本非常非常高.
9、其他索引
Hash索引
full-text索引
R-Tree索引
10、哪些情況需要創建索引
主鍵自動建立唯一索引
頻繁作為查詢條件的字段
查詢中與其他表關聯的字段,外鍵關系創建索引
在高并發下創建組合索引
查詢中排序的字段,排序字段若通過索引去拜訪將大大提高排序速度
查詢中統計或分組字段
11、哪些情況不用建立索引
表記錄太少
經常增刪改的表
提高了查詢速度,同時卻會降低更新表的速度,如對表進行INSERT、UPDATE和DELETE.
因為更新表時,MySQL不僅要保存數據,還要保存一下索引文件
數據重復且分布平均的表字段,因此應該只為最經常查詢和最經常排序的數據列建立索引. 注意,如果某個數據列包括許多重復的內容,為它建立索引就沒有太大的實際效果.

維易PHP培訓學院每天發布《簡單MySQL教程二》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/7881.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
