CMU研發(fā)數據庫調優(yōu)AI,水平超DBA老炮
《CMU研發(fā)數據庫調優(yōu)AI,水平超DBA老炮》要點:
本文介紹了CMU研發(fā)數據庫調優(yōu)AI,水平超DBA老炮,希望對您有用。如果有疑問,可以聯系我們。

這個周末,最不開心的應該是優(yōu)秀的數據庫治理員了.
這些優(yōu)秀的數據庫管理員(以下簡稱數據庫管理員為DBA),原本可以靠自己的本領,享受高薪,可是,好景不長了,因為即便是資質平平的DBA,以后借助AI的力量,也能瞬間達到優(yōu)秀DBA的水平.
來看最近來自卡耐基梅隆數據庫小組的最新研究結果,他們正用最新的深度學習技術,完成數據庫的調優(yōu)工作.
如果這項技術在未來進一步遍及,那么,很無奈,這個行業(yè)不得不接受AI對于人員結構的改造.
DBA迎來新的反動
卡內基·梅隆大學數據庫小組采納機器學習實現了數據庫的自動化管理,其在線版的自動化管理服務 OtterTune 稍后即會上線.
OtterTune 所要辦理的是數據庫管理中最為繁雜的問題:諸如緩存大小分配、寫入頻率管理等因素在內的數百項參數的動態(tài)設置.過去,這項工作只能由經驗豐富的數據庫專家手動來完成.
這其中采納了怎樣的原理呢?
OtterTune 到底用了什么原理?
采用機器學習后,OtterTune 把數據庫管理系統(tǒng)(DBMS)的工作流程釀成這樣:
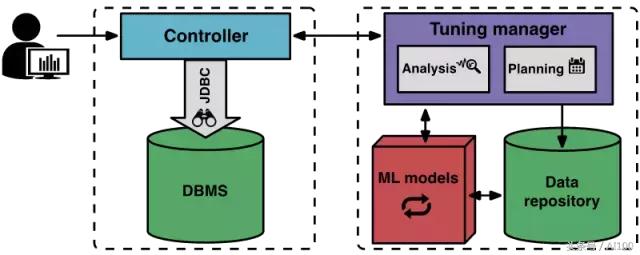
一開始,OtterTune 必要被告知明確的優(yōu)化目標,如延遲、吞吐量等;其客戶端 Controller 會自動關聯目標 DBMS 及其亞馬遜 EC2 副本的類型與當前設置.
而后,Controller 便開啟第一個察看周期,察看 DBMS 并記錄目標項.察看結束時,Controller 會搜集好 DBMS 的內部參數,并將它和目標項發(fā)送給 Tuning Manager.
收到參數后,Tuning Manager 便把它們存儲入庫.OtterTune 用這些參數計算出 DBMS 的目標配置,并將其發(fā)還至 Controller,Controller 部署并運行新的配置,以提升數據庫性能.
治理人員可隨時啟用或終止 OtterTune 服務.
簡而言之:
首先,必要設置一些優(yōu)化目標,連接到數據庫系統(tǒng),使用初始化的設置去運行;
然后控制器開啟第一次察看周期,記錄下當前設置模式下的所有系統(tǒng)性能度量,并返回這些結果給調優(yōu)器;
調優(yōu)器記錄這些成果,并根據這些度量信息和系統(tǒng)信息計算出新的數據庫配置;
最后調優(yōu)器把調優(yōu)成果配置傳回控制器,同時可以有效評估系統(tǒng)提升的期望值;
用戶依據評估值決定是否使用新的配置.
其中最核心的步驟便是:計算出新的數據庫管理系統(tǒng)DBMS 的目標配置,即這里面用到的主要是機器學習.
下面詳細解釋一下機械學習在里面的作用.
機械學習的作用
機器學習模塊分為三部分:獲取 Controller 觀察到的工作負載參數(Workload Characterization 組件),辨認并學習這些參數(Knob Identification 組件),自動管理數據庫(Automatic Tuner 組件).
下面逐一來說:
Workload Characterization: OtterTune 使用 DBMS 的內部運行參數來提取數據庫的工作負載特征.機器學習模塊使用聚類辦法來衡量這些參數的相關性,盡可能地裁剪參數量,以降低計算的復雜程度.
Knob Identification: 識別并學習數據庫參數,OtterTune 所用的特征選取辦法是 Lasso,以找出它們的重要程度.OtterTune 據此來計算 DBMS 的目標配置,它使用一種增量辦法來找出數據庫的最佳配置.
Automatic Tuner: 而后的工作則交由 Automatic Tuner 組件.首先,它用 Workload Characterization 組件的性能數據來確定 DBMS 的目標負載;而后,它會選擇一組分歧的配置進行測試.
OtterTune 的目標總是優(yōu)化下一組配置,盡可能地搜集數據來晉升性能,而非緊盯住目標配置不放.
成果對比
OtterTune 在論文中測試了 MySQL 和 Postgres 這兩個數據庫的延遲和吞吐量,成果如下:
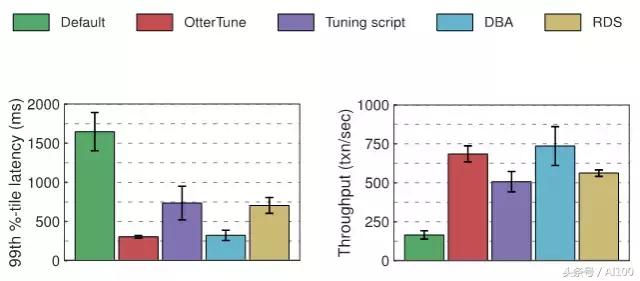
從圖中可以看出,相比于 MYSQL 治理腳本,OtterTune 的延遲要低 60%,吞吐量則能提升 35%.
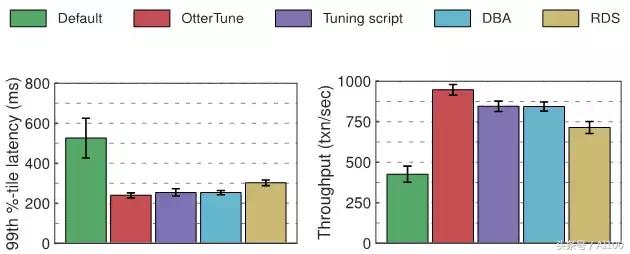
相比于 Postgres 的默認配置,OtterTune 與其他辦法在延遲方面的提升大體相近;但吞吐量方面,OtterTune 比 DBA 的選擇要好 12%.
總體來看,OtterTune可以在延遲和吞吐等性能指標上大幅領先傳統(tǒng)的自動化配置腳本,并接近專業(yè)DBA的程度.
AI若何擊中了這個行業(yè)的痛點?
為什么這個行業(yè)必要AI來改造?DBA的日常工作到底有哪些痛點?
讓我們把眼光拉近,看看這個行業(yè)到底有什么問題.
目前的數據庫,主要采納專業(yè)的數據庫管理員(以下稱DBA)來設計數據系統(tǒng)的架構,調優(yōu)等.
但是,由于業(yè)務系統(tǒng)極其復雜,且隨著業(yè)務的快速迭代,必要數據庫系統(tǒng)能跟上業(yè)務的節(jié)奏,快速響應,快速更新,這就導致調優(yōu)任務也隨之變得極其復雜.
DBA需要靈活掌握各項影響系統(tǒng)性能的控制因素,也必需對數據底層,甚至體系結構都有深入了解,才能很好地完成調優(yōu)任務.
因此,真正滿足優(yōu)秀的DBA就非常少了,并且價格昂貴.
隨著大數據行業(yè)的井噴式發(fā)展,這種人才一直都是嚴重供不該求.
不外,這部分原本可以享受高薪的人群,好日子貌似要走到頭了.
因為,通俗DBA也能借助AI搶飯碗了.
卡耐基梅隆的數據庫小組整出來的這個新研究,就是要通過使用AI技術,簡化了DBA對于數據庫系統(tǒng)的調優(yōu)過程,即就是普通的DBA,也能達到、甚至超過專業(yè)DBA調優(yōu)系統(tǒng)的能力.
所以,一旦AI在此領域真正開始發(fā)揮作用,人力本錢將大幅降低,工作又能快速響應,公司再也不會因為專業(yè)DBA短缺而影響業(yè)務發(fā)展了,這將是公司老板拍手稱快的大好事.
原文地址
https://aws.amazon.com/cn/blogs/ai/tuning-your-dbms-automatically-with-machine-learning/必修tag=vglnk-c1507-20
歡迎參與《CMU研發(fā)數據庫調優(yōu)AI,水平超DBA老炮》討論,分享您的想法,維易PHP學院為您提供專業(yè)教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/7849.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創(chuàng)建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
