性能調優攻略|SQL語句優化
《性能調優攻略|SQL語句優化》要點:
本文介紹了性能調優攻略|SQL語句優化,希望對您有用。如果有疑問,可以聯系我們。

1/ 前言
關于 MySQL 優化的方式在《千萬級的大表!MySQL這樣優化更好》文章已經有提到過.本日我們是談談關于 SQL 語句的優化部分.
日常 SQL 性能優化過程中,會借助一些查詢分析工具來協助,例如:
Solarwinds的SQL Query Analyzer;
MySQL 的SQL Query Analyzer;
Oracle 的SQL Performance Analyzer;
微軟的SQL Query Analyzer;
此中 MySQL 我們還可以使用 explain 工具來查看 SQL 語句的執行計劃(Execution Plan).
2/ 性能優化
對付 SQL 的性能優化,主要通過以下幾個維度來討論:
2.1/ 全表檢索
例1:SELECT * FROM user WHERE name = "xxx";
這樣的 SQL 語句基本上是全表查找,線性復雜度為 O(n),記錄數越多,性能也就越差.對于這種情況,我們可以有以下兩種辦法來提示性能:
分表,將年夜記錄數分割成幾塊小的記錄數;
索引,針對name 字段建立索引,對付B-Tree索引的復雜度基本上是 O(logn);
2.2/ 索引
針對已建立索引字段,在 WHERE 和 ORDER BY 子句中 ,盡量不要在字段上做計算、類型轉換、函數、空值判斷、字段連接等操作,因為這些操作將會破壞索引底本的性能.
2.3/ 多表查詢
關系型數據庫最多的操作就是多表查詢,多表查詢主要有三個關鍵字,EXISTS、IN 和 JOIN.基原來說,現在的數據引擎對 SQL 語句優化得都很好了,EXISTS、IN 和 JOIN 在結果上有些不同,但性能基本上都差不多.
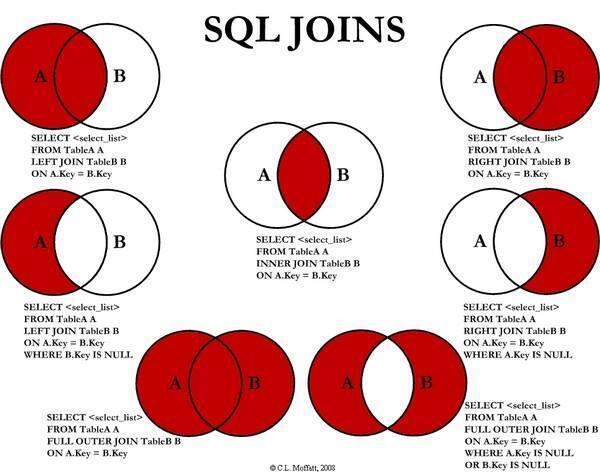
對付 JOIN 有三種實現算法,
嵌套循環(MySQL 只支持這種)
排序歸并,將兩個表依照查詢字段排序,再合并.
Hash 的 JOIN,主要辦理嵌套循環的 O(logn)的復雜度,使用一個臨時的 Hash 表來標識;
2.4/ 部門結果集
MySQL 中的 LIMIT、Oracle 的 ROWNUM、SQL Server 里的 TOP 都是在限制前幾條的返回成果.這樣給數據庫引擎很多可以調優的空間.
2.5/ 字符串
由于字符串在 SQL 中操作性能比擬差,因此在創建數據結構時,我們的基本上原則是:能用數字表示的盡量使用數字來表示,如:時間、工號等.
2.6/ 全文檢索
對于Text 類的文本字段查詢,盡量不使用 LIKE 來做全文檢索,如果必要全文檢索功能,可以嘗試使用第三方組件,如 Sphinx、ELK等.
2.7/ 其它
不用 SELECT *,明確指出各個字段,多表查詢必定要在字段名前加上表名.
不消 HAVING,因為會遍歷所有的記錄,性能極差.
盡可能地使用 UNION ALL代替 UNION.
索引過多,INSERT 和 DELETE 會越慢,UPDATE 如果是多半索引,也會慢,但如果只是一個索引,則只會影響一個索引表.
還有一點重要的,數據庫的各種操作都必要大量的內存,所以要保證服務器有足夠的內存.特別是針對 多表查詢的 SQL 語句,更是相當的耗內存.
3/ 總結
對 SQL 語句的性能優化,這里只是提供一個優化偏向或約定.在日常使用過程還是根據具體使用場景和方式來決定,沒有絕對的方式.
歡迎參與《性能調優攻略|SQL語句優化》討論,分享您的想法,維易PHP學院為您提供專業教程。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/7842.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
