Java互聯(lián)網(wǎng)架構(gòu)-深入理解MySQL性能調(diào)優(yōu)
《Java互聯(lián)網(wǎng)架構(gòu)-深入理解MySQL性能調(diào)優(yōu)》要點(diǎn):
本文介紹了Java互聯(lián)網(wǎng)架構(gòu)-深入理解MySQL性能調(diào)優(yōu),希望對(duì)您有用。如果有疑問(wèn),可以聯(lián)系我們。
概述
MySQL的主要適用場(chǎng)景
1、Web網(wǎng)站系統(tǒng)
2、日志記錄系統(tǒng)
3、數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)
4、嵌入式系統(tǒng)
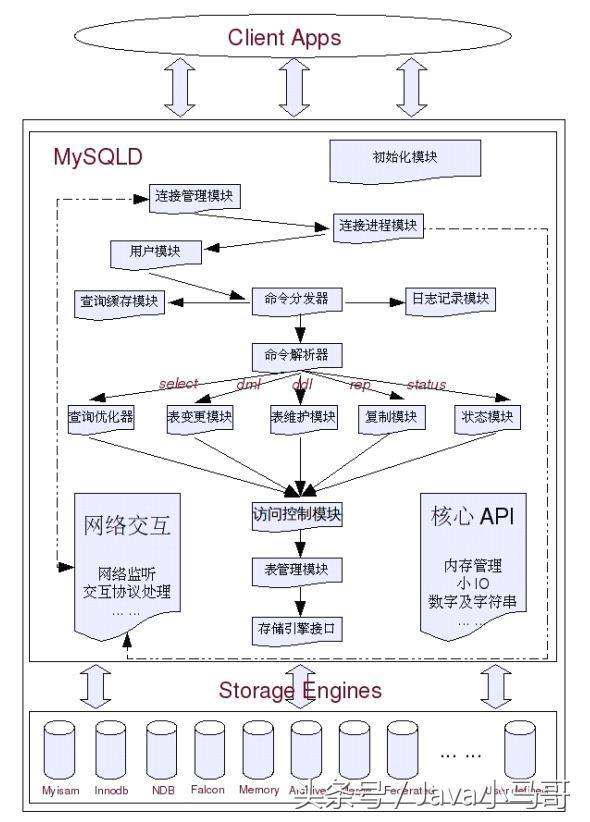
MySQL架構(gòu)圖:
索引
索引是什么
官方介紹索引是贊助MySQL高效獲取數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu).
筆者理解索引相當(dāng)于一本書(shū)的目錄,通過(guò)目錄就知道要的資料在哪里,不用一頁(yè)一頁(yè)查閱找出必要的資料.
索引目的
索引的目的在于提高查詢效率,可以類(lèi)比字典,如果要查“mysql”這個(gè)單詞,我們肯定必要定位到m字母,然后從下往下找到y(tǒng)字母,再找到剩下的sql.
如果沒(méi)有索引,那么你可能必要把所有單詞看一遍才能找到你想要的,如果我想找到m開(kāi)頭的單詞呢?或者ze開(kāi)頭的單詞呢?是不是覺(jué)得如果沒(méi)有索引,這個(gè)事情根本無(wú)法完成?
索引原理
除了辭書(shū),生活中隨處可見(jiàn)索引的例子,如火車(chē)站的車(chē)次表、圖書(shū)的目錄等.
它們的原理都是一樣的,通過(guò)不斷的縮小想要獲得數(shù)據(jù)的范圍來(lái)篩選出最終想要的結(jié)果,同時(shí)把隨機(jī)的事件變成順序的事件,也便是我們總是通過(guò)同一種查找方式來(lái)鎖定數(shù)據(jù).
數(shù)據(jù)庫(kù)也是一樣,但顯然要復(fù)雜許多,因?yàn)椴粌H面臨著等值查詢,還有范圍查詢(>、<、between、in)、模糊查詢(like)、并集查詢(or)等等.
數(shù)據(jù)庫(kù)應(yīng)該選擇怎么樣的方式來(lái)應(yīng)對(duì)所有的問(wèn)題呢?
我們回想字典的例子,能不克不及把數(shù)據(jù)分成段,然后分段查詢呢?
最簡(jiǎn)單的如果1000條數(shù)據(jù),1到100分成第一段,101到200分成第二段,201到300分成第三段……這樣查第250條數(shù)據(jù),只要找第三段就可以了,一下子去除了90%的無(wú)效數(shù)據(jù).
但如果是1千萬(wàn)的記錄呢,分成幾段比擬好?稍有算法基礎(chǔ)的同學(xué)會(huì)想到搜索樹(shù),其平均復(fù)雜度是lgN,具有不錯(cuò)的查詢性能.
但這里我們忽略了一個(gè)關(guān)鍵的問(wèn)題,復(fù)雜度模型是基于每次相同的操作成原來(lái)考慮的,
數(shù)據(jù)庫(kù)實(shí)現(xiàn)比較復(fù)雜,數(shù)據(jù)保留在磁盤(pán)上,而為了提高性能,每次又可以把部分?jǐn)?shù)據(jù)讀入內(nèi)存來(lái)計(jì)算,
因?yàn)槲覀冎腊菰L磁盤(pán)的成本大概是拜訪內(nèi)存的十萬(wàn)倍左右,所以簡(jiǎn)單的搜索樹(shù)難以滿足復(fù)雜的應(yīng)用場(chǎng)景.
磁盤(pán)IO與預(yù)讀
前面提到了拜訪磁盤(pán),那么這里先簡(jiǎn)單介紹一下磁盤(pán)IO和預(yù)讀,
磁盤(pán)讀取數(shù)據(jù)靠的是機(jī)械運(yùn)動(dòng),每次讀取數(shù)據(jù)花費(fèi)的時(shí)間可以分為尋道時(shí)間、旋轉(zhuǎn)延遲、傳輸時(shí)間三個(gè)部分,尋道時(shí)間指的是磁臂移動(dòng)到指定磁道所必要的時(shí)間,主流磁盤(pán)一般在5ms以下;
旋轉(zhuǎn)延遲就是我們經(jīng)常聽(tīng)說(shuō)的磁盤(pán)轉(zhuǎn)速,好比一個(gè)磁盤(pán)7200轉(zhuǎn),表示每分鐘能轉(zhuǎn)7200次,也就是說(shuō)1秒鐘能轉(zhuǎn)120次,旋轉(zhuǎn)延遲就是1/120/2 = 4.17ms;
傳輸時(shí)間指的是從磁盤(pán)讀出或?qū)?shù)據(jù)寫(xiě)入磁盤(pán)的時(shí)間,一般在零點(diǎn)幾毫秒,相對(duì)于前兩個(gè)時(shí)間可以忽略不計(jì).
那么拜訪一次磁盤(pán)的時(shí)間,即一次磁盤(pán)IO的時(shí)間約等于5+4.17 = 9ms左右,聽(tīng)起來(lái)還挺不錯(cuò)的,
但要知道一臺(tái)500 -MIPS的機(jī)器每秒可以執(zhí)行5億條指令,因?yàn)橹噶钜揽康氖请姷男再|(zhì),
換句話說(shuō)執(zhí)行一次IO的時(shí)間可以執(zhí)行40萬(wàn)條指令,數(shù)據(jù)庫(kù)動(dòng)輒十萬(wàn)百萬(wàn)乃至千萬(wàn)級(jí)數(shù)據(jù),每次9毫秒的時(shí)間,顯然是個(gè)災(zāi)難.
下圖是計(jì)算機(jī)硬件延遲的對(duì)比圖,供大家參考:

考慮到磁盤(pán)IO是非常昂揚(yáng)的操作,計(jì)算機(jī)操作系統(tǒng)做了一些優(yōu)化,
當(dāng)一次IO時(shí),不光把當(dāng)前磁盤(pán)地址的數(shù)據(jù),而是把相鄰的數(shù)據(jù)也都讀取到內(nèi)存緩沖區(qū)內(nèi),
因?yàn)榫植款A(yù)讀性原理告訴我們,當(dāng)計(jì)算機(jī)拜訪一個(gè)地址的數(shù)據(jù)的時(shí)候,與其相鄰的數(shù)據(jù)也會(huì)很快被拜訪到.
每一次IO讀取的數(shù)據(jù)我們稱之為一頁(yè)(page).
具體一頁(yè)有多大數(shù)據(jù)跟操作系統(tǒng)有關(guān),一般為4k或8k,也就是我們讀取一頁(yè)內(nèi)的數(shù)據(jù)時(shí)候,實(shí)際上才發(fā)生了一次IO,這個(gè)理論對(duì)于索引的數(shù)據(jù)結(jié)構(gòu)設(shè)計(jì)非常有贊助.
索引的數(shù)據(jù)布局
前面講了生活中索引的例子,索引的基本原理,數(shù)據(jù)庫(kù)的復(fù)雜性,又講了操作系統(tǒng)的相關(guān)知識(shí),目的就是讓大家了解,任何一種數(shù)據(jù)結(jié)構(gòu)都不是憑空產(chǎn)生的,一定會(huì)有它的配景和使用場(chǎng)景.
我們現(xiàn)在總結(jié)一下,我們必要這種數(shù)據(jù)結(jié)構(gòu)能夠做些什么,其實(shí)很簡(jiǎn)單,那就是:每次查找數(shù)據(jù)時(shí)把磁盤(pán)IO次數(shù)控制在一個(gè)很小的數(shù)量級(jí),最好是常數(shù)數(shù)量級(jí).那么我們就想到如果一個(gè)高度可控的多路搜索樹(shù)是否能滿足需求呢?就這樣,b+樹(shù)應(yīng)運(yùn)而生.
詳解b+樹(shù)
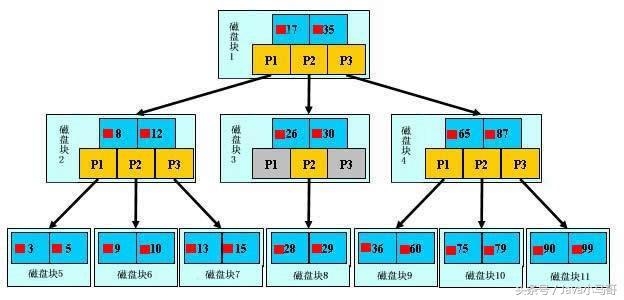
如上圖,是一顆b+樹(shù),關(guān)于b+樹(shù)的定義可以參見(jiàn)B+樹(shù).
這里只說(shuō)一些重點(diǎn),淺藍(lán)色的塊我們稱之為一個(gè)磁盤(pán)塊,可以看到每個(gè)磁盤(pán)塊包括幾個(gè)數(shù)據(jù)項(xiàng)(深藍(lán)色所示)和指針(黃色所示),
如磁盤(pán)塊1包括數(shù)據(jù)項(xiàng)17和35,包括指針P1、P2、P3,P1表示小于17的磁盤(pán)塊,P2表示在17和35之間的磁盤(pán)塊,P3表示大于35的磁盤(pán)塊.
真實(shí)的數(shù)據(jù)存在于葉子節(jié)點(diǎn)即3、5、9、10、13、15、28、29、36、60、75、79、90、99.
非葉子節(jié)點(diǎn)只不存儲(chǔ)真實(shí)的數(shù)據(jù),只存儲(chǔ)指引搜索方向的數(shù)據(jù)項(xiàng),
如17、35并不真實(shí)存在于數(shù)據(jù)表中.
b+樹(shù)的查找過(guò)程
如圖所示,如果要查找數(shù)據(jù)項(xiàng)29,
那么首先會(huì)把磁盤(pán)塊1由磁盤(pán)加載到內(nèi)存,此時(shí)產(chǎn)生一次IO,
在內(nèi)存中用二分查找確定29在17和35之間,鎖定磁盤(pán)塊1的P2指針,內(nèi)存時(shí)間因?yàn)榉浅6?相比磁盤(pán)的IO)可以忽略不計(jì),
通過(guò)磁盤(pán)塊1的P2指針的磁盤(pán)地址把磁盤(pán)塊3由磁盤(pán)加載到內(nèi)存,產(chǎn)生第二次IO,
29在26和30之間,鎖定磁盤(pán)塊3的P2指針,通過(guò)指針加載磁盤(pán)塊8到內(nèi)存,產(chǎn)生第三次IO,
同時(shí)內(nèi)存中做二分查找找到29,結(jié)束查詢,總計(jì)三次IO.
真實(shí)的情況是,3層的b+樹(shù)可以表示上百萬(wàn)的數(shù)據(jù),如果上百萬(wàn)的數(shù)據(jù)查找只必要三次IO,性能提高將是巨大的,
如果沒(méi)有索引,每個(gè)數(shù)據(jù)項(xiàng)都要發(fā)生一次IO,那么總共需要百萬(wàn)次的IO,顯然本錢(qián)非常非常高.
b+樹(shù)性質(zhì)
通過(guò)上面的分析,我們知道IO次數(shù)取決于b+數(shù)的高度h,假設(shè)當(dāng)前數(shù)據(jù)表的數(shù)據(jù)為N,每個(gè)磁盤(pán)塊的數(shù)據(jù)項(xiàng)的數(shù)量是m,則有h=㏒(m+1)N,當(dāng)數(shù)據(jù)量N必定的情況下,m越大,h越小;
而m = 磁盤(pán)塊的大小 / 數(shù)據(jù)項(xiàng)的大小,磁盤(pán)塊的大小也便是一個(gè)數(shù)據(jù)頁(yè)的大小,是固定的,如果數(shù)據(jù)項(xiàng)占的空間越小,數(shù)據(jù)項(xiàng)的數(shù)量越多,樹(shù)的高度越低.
這就是為什么每個(gè)數(shù)據(jù)項(xiàng),即索引字段要盡量的小,好比int占4字節(jié),要比bigint8字節(jié)少一半.
這也是為什么b+樹(shù)要求把真實(shí)的數(shù)據(jù)放到葉子節(jié)點(diǎn)而不是內(nèi)層節(jié)點(diǎn),一旦放到內(nèi)層節(jié)點(diǎn),磁盤(pán)塊的數(shù)據(jù)項(xiàng)會(huì)大幅度下降,導(dǎo)致樹(shù)增高.
當(dāng)數(shù)據(jù)項(xiàng)等于1時(shí)將會(huì)退化成線性表.
當(dāng)b+樹(shù)的數(shù)據(jù)項(xiàng)是復(fù)合的數(shù)據(jù)結(jié)構(gòu),好比(name,age,sex)的時(shí)候,
b+數(shù)是依照從左到右的順序來(lái)建立搜索樹(shù)的,
好比當(dāng)(張三,20,F)這樣的數(shù)據(jù)來(lái)檢索的時(shí)候,
b+樹(shù)會(huì)優(yōu)先比擬name來(lái)確定下一步的所搜方向,如果name相同再依次比擬age和sex,最后得到檢索的數(shù)據(jù);
但當(dāng)(20,F)這樣的沒(méi)有name的數(shù)據(jù)來(lái)的時(shí)候,b+樹(shù)就不知道下一步該查哪個(gè)節(jié)點(diǎn),
因?yàn)榻⑺阉鳂?shù)的時(shí)候name就是第一個(gè)比擬因子,必須要先根據(jù)name來(lái)搜索才能知道下一步去哪里查詢.
好比當(dāng)(張三,F)這樣的數(shù)據(jù)來(lái)檢索時(shí),b+樹(shù)可以用name來(lái)指定搜索方向,
但下一個(gè)字段age的缺失,所以只能把名字等于張三的數(shù)據(jù)都找到,然后再匹配性別是F的數(shù)據(jù)了,
這個(gè)是非常重要的性質(zhì),即索引的最左匹配特性.
索引是不是越多越好?
索引能夠極大的提高數(shù)據(jù)檢索效率,也能夠改善排序分組操作的性能,但是我們不能忽略的一個(gè)問(wèn)題便是索引是完全獨(dú)立于基礎(chǔ)數(shù)據(jù)之外的一部分?jǐn)?shù)據(jù).
假設(shè)我們?cè)诟卤碇杏凶侄蔚耐瑫r(shí),也更新索引數(shù)據(jù),調(diào)整因?yàn)楦滤鶐?lái)鍵值變化后的索引信息.
而如果我們沒(méi)有對(duì)字段進(jìn)行索引的話,MySQL 所必要做的僅僅只是更新表中字段 的信息.
這樣,所帶來(lái)的最明顯的資源消耗便是增加了更新所帶來(lái)的IO量和調(diào)整索引所致的計(jì)算量.
此外,索引是必要占用存儲(chǔ)空間的,而且隨著數(shù)據(jù)量的增長(zhǎng),所占用的空間也會(huì)不斷增長(zhǎng).
所以索引還會(huì)帶來(lái)存儲(chǔ)空間資源消耗的增長(zhǎng).
什么場(chǎng)景應(yīng)該加索引?加索引的四個(gè)原則
1. 較頻繁的作為查詢條件的字段應(yīng)該創(chuàng)立索引
提高數(shù)據(jù)查詢檢索的效率最有效的辦法就是減少需要拜訪的數(shù)據(jù)量,從上面所了解到的索引的益處中我們知道了,索引正是我們減少通過(guò)索引鍵字段作為查詢條件的Query 的IO 量的最有效手段.所以一般來(lái)說(shuō)我們應(yīng)該為較為頻繁的查詢條件字段創(chuàng)建索引.
2. 唯一性太差的字段不適合單獨(dú)創(chuàng)立索引,即使頻繁作為查詢條件
唯一性太差的字段主要是指哪些呢?
如狀態(tài)字段,類(lèi)型字段等等,這些字段中存方的數(shù)據(jù)可能總共便是那么幾個(gè)幾十個(gè)值重復(fù)使用,每個(gè)值都會(huì)存在于成千上萬(wàn)或是更多的記錄中.
對(duì)于這類(lèi)字段,我們完全沒(méi)有需要?jiǎng)?chuàng)建單獨(dú)的索引的.
因?yàn)榧词刮覀儎?chuàng)立了索引,MySQL Query Optimizer 大多數(shù)時(shí)候也不會(huì)去選擇使用,
如果什么時(shí)候MySQL Query Optimizer 抽了一下風(fēng)選擇了這種索引,那么非常遺憾的告訴你,這可能會(huì)帶來(lái)極大的性能問(wèn)題.
由于索引字段中每個(gè)值都含有大量的記錄,那么存儲(chǔ)引擎在根據(jù)索引拜訪數(shù)據(jù)的時(shí)候會(huì)帶來(lái)大量的隨機(jī)IO,甚至有些時(shí)候可能還會(huì)出現(xiàn)大量的重復(fù)IO.
3. 更新非常頻繁的字段不適合創(chuàng)立索引
上面在索引的弊端中我們已經(jīng)分析過(guò)了,索引中的字段被更新的時(shí)候,不僅僅必要更新表中的數(shù)據(jù),同時(shí)還要更新索引數(shù)據(jù),以確保索引信息是準(zhǔn)確的.
這個(gè)問(wèn)題所帶來(lái)的是IO 拜訪量的較大增加,不僅僅影響更新Query 的響應(yīng)時(shí)間,還會(huì)影響整個(gè)存儲(chǔ)系統(tǒng)的資源消耗,加大整個(gè)存儲(chǔ)系統(tǒng)的負(fù)載.
4. 不會(huì)呈現(xiàn)在WHERE子句中的字段不創(chuàng)建索引
查詢時(shí),不會(huì)命中索引.那么索引就沒(méi)有存在的意義了.
創(chuàng)建索引的舉例闡明
CREATE TABLE `v9_member_menu` ( `id` smallint(6) unsigned NOT NULL AUTO_INCREMENT, # 主鍵標(biāo)識(shí) `name` char(40) NOT NULL DEFAULT '', # 菜單名稱 `parentid` smallint(6) NOT NULL DEFAULT '0', # 父級(jí)ID `m` char(20) NOT NULL DEFAULT '', # 模型名稱 `c` char(20) NOT NULL DEFAULT '', # 控制器名 `a` char(20) NOT NULL DEFAULT '', # 辦法名 `data` char(100) NOT NULL DEFAULT '', # 附加數(shù)據(jù) `listorder` smallint(6) unsigned NOT NULL DEFAULT '0',# 排序值 `display` enum('1','0') NOT NULL DEFAULT '1', # 是否顯示 `isurl` enum('1','0') NOT NULL DEFAULT '0', # 是否是一個(gè)鏈接 `url` char(255) NOT NULL DEFAULT '', # 鏈接地址 PRIMARY KEY (`id`), KEY `listorder` (`listorder`), KEY `parentid` (`parentid`), KEY `module` (`m`,`c`,`a`)) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;關(guān)于 菜單的使用場(chǎng)景, 我做出如下整理
會(huì)根據(jù) url分割出 m,c,a 然后進(jìn)行查詢菜單ID,再關(guān)聯(lián)權(quán)限表,查詢是否有權(quán)限.
根據(jù) 菜單ID 獲取菜單信息,例如 刪,改,查的應(yīng)用場(chǎng)景
會(huì)根據(jù)菜單的父級(jí)ID 查詢父級(jí)信息, 或者同本身的ID 查詢子級(jí)信息.
顯示菜單時(shí),通常會(huì)進(jìn)行排序.
第一個(gè)情況 就符合 ,創(chuàng)建復(fù)合索引的條件,在where中常常會(huì)一起出現(xiàn),
例如 m=home and c=index and a=login
第二個(gè)情況 可以使用主鍵索引,主鍵自己就自帶索引屬性.
第三個(gè)情況,在查詢子級(jí)時(shí) 通常會(huì)使用到.
第四個(gè)情況: 排序也常常使用到.
data 和 url 為何不加索引?
data 和 url 屬于詳細(xì)內(nèi)容, 一般只用于展示,不會(huì)加入到where條件查詢中,所以不必要加索引.
display 和 isurl 為何不加索引
display 和 isurl 一樣 他的數(shù)值很單一,不是1就是0,沒(méi)需要加索引,而且符合條件的數(shù)據(jù)有很多,給mysql帶來(lái)大量的隨機(jī)IO.
索引的類(lèi)型
聚簇索引和非聚簇索引
索引分為聚簇索引和非聚簇索引兩種,聚簇索引是依照數(shù)據(jù)存放的物理位置為順序的,而非聚簇索引就不一樣了;
聚簇索引能提高多行檢索的速度,而非聚簇索引對(duì)于單行的檢索很快.
聚簇索引是一種數(shù)據(jù)存儲(chǔ)方式,它實(shí)際上是在同一個(gè)結(jié)構(gòu)中保存了B+樹(shù)索引和數(shù)據(jù)行,InnoDB表是依照聚簇索引組織的(類(lèi)似于Oracle的索引組織表).
InnoDB通過(guò)主鍵聚簇?cái)?shù)據(jù),如果沒(méi)有定義主鍵,會(huì)選擇一個(gè)唯一的非空索引代替,如果沒(méi)有這樣的索引,會(huì)隱式定義個(gè)主鍵作為聚簇索引.
下圖形象闡明了聚簇索引表(InnoDB)和非聚簇索引(MyISAM)的區(qū)別:
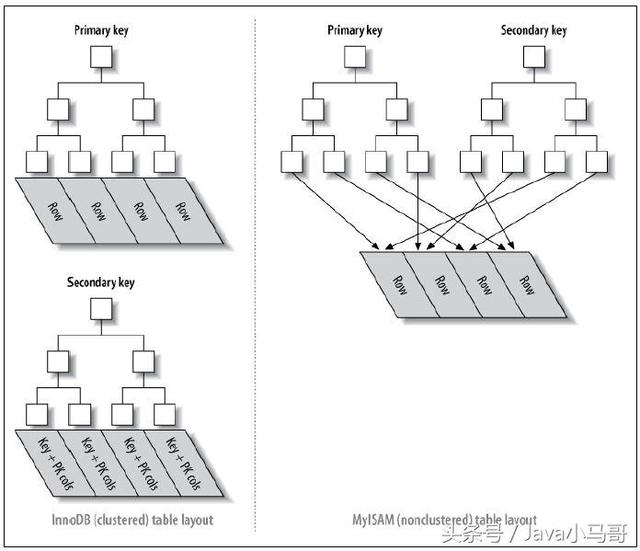
對(duì)于非聚簇索引表來(lái)說(shuō)(右圖),表數(shù)據(jù)和索引是分成存儲(chǔ)的,主鍵索引和二級(jí)索引存儲(chǔ)上沒(méi)有任何區(qū)別.
而對(duì)于聚簇索引表來(lái)說(shuō)(左圖),表數(shù)據(jù)是和主鍵一起存儲(chǔ)的,主鍵索引的葉結(jié)點(diǎn)存儲(chǔ)行數(shù)據(jù),二級(jí)索引的葉結(jié)點(diǎn)存儲(chǔ)行的主鍵值.
聚簇索引表最大限度地提高了I/O密集型應(yīng)用的性能,但它也有以下幾個(gè)限制:
1)插入速度嚴(yán)重依賴于插入順序,依照主鍵的順序插入是最快的方式,否則將會(huì)出現(xiàn)頁(yè)分裂,嚴(yán)重影響性能.
因此,對(duì)于InnoDB表,我們一般都會(huì)定義一個(gè)自增的ID列為主鍵.
2)更新主鍵的代價(jià)很高,因?yàn)閷?huì)導(dǎo)致被更新的行移動(dòng).因此,對(duì)于InnoDB表,我們一般定義主鍵為弗成更新.
3)二級(jí)索引拜訪需要兩次索引查找,第一次找到主鍵值,第二次根據(jù)主鍵值找到行數(shù)據(jù).
二級(jí)索引的葉節(jié)點(diǎn)存儲(chǔ)的是主鍵值,而不是行指針(非聚簇索引存儲(chǔ)的是指針或者說(shuō)是地址),這是為了減少當(dāng)呈現(xiàn)行移動(dòng)或數(shù)據(jù)頁(yè)分裂時(shí)二級(jí)索引的維護(hù)工作,但會(huì)讓二級(jí)索引占用更多的空間.
聚簇索引的葉節(jié)點(diǎn)就是數(shù)據(jù)節(jié)點(diǎn),而非聚簇索引的頁(yè)節(jié)點(diǎn)仍然是索引檢點(diǎn),并保存一個(gè)鏈接指向?qū)?yīng)數(shù)據(jù)塊.
聚簇索引主鍵的插入速度要比非聚簇索引主鍵的插入速度慢很多.
相比之下,聚簇索引適合排序,非聚簇索引不適合用在排序的場(chǎng)所.
因?yàn)榫鄞厮饕旧硪呀?jīng)是依照物理順序放置的,排序很快.
非聚簇索引則沒(méi)有順次存放,需要額外消耗資源來(lái)排序.
當(dāng)你需要取出必定范圍內(nèi)的數(shù)據(jù)時(shí),用聚簇索引也比用非聚簇索引好.
主鍵索引(PRIMARY KEY )
主鍵自帶索引屬性. 不管是 修改查詢刪除 基本都會(huì)用到它.
普通索引(Normal)
這是最基本的索引,它沒(méi)有任何限制,好比上文中為listorder字段創(chuàng)建的索引就是一個(gè)普通索引,MyIASM中默認(rèn)的BTREE類(lèi)型的索引,也是我們大多數(shù)情況下用到的索引.
實(shí)例
–直接創(chuàng)建索引CREATE INDEX index_name ON table(column(length))–修改表布局的方式添加索引ALTER TABLE table_name ADD INDEX index_name ON (column(length))–創(chuàng)建表的時(shí)候同時(shí)創(chuàng)建索引CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), INDEX index_name (title(length)))–刪除索引DROP INDEX index_name ON table
唯一索引(Unique)
與普通索引類(lèi)似,不同的就是:索引列的值必需唯一,但允許有空值(注意和主鍵不同).
如果是組合索引,則列值的組合必須唯一,創(chuàng)建辦法和普通索引類(lèi)似.
例如:用戶表的 用戶名 和 郵箱 都可以進(jìn)行唯一索引
實(shí)例
–創(chuàng)建唯一索引CREATE UNIQUE INDEX indexName ON table(column(length))–修改表布局ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))–創(chuàng)建表的時(shí)候直接指定CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), UNIQUE indexName (title(length)));
全文索引(Full Text)
MySQL從3.23.23版開(kāi)始支持全文索引和全文檢索,FULLTEXT索引僅可用于 MyISAM 表;
他們可以從CHAR、VARCHAR或TEXT列中作為CREATE TABLE語(yǔ)句的一部門(mén)被創(chuàng)建,
或是隨后使用ALTER TABLE 或CREATE INDEX被添加.
對(duì)于較大的數(shù)據(jù)集,將你的材料輸入一個(gè)沒(méi)有FULLTEXT索引的表中,然后創(chuàng)建索引,其速度比把材料輸入現(xiàn)有FULLTEXT索引的速度更為快.
不外切記對(duì)于大容量的數(shù)據(jù)表,生成全文索引是一個(gè)非常消耗時(shí)間非常消耗硬盤(pán)空間的做法.
在數(shù)據(jù)量不是很大的情況下 可以利用 全文索引做 站內(nèi)搜索.
但是得先分詞,能力進(jìn)行全文檢索.檢索時(shí) 是通過(guò) 空格來(lái)分割詞匯.
最好是 新建一個(gè)關(guān)聯(lián)表(此中 存儲(chǔ)分詞的字段 用全文索引),把分詞后的內(nèi)容 用 空格分割 存儲(chǔ)到 關(guān)聯(lián)表,然后對(duì)應(yīng)原始表.
查詢流程如下
查詢關(guān)聯(lián)表
獲取所有能查到的 文章ID
根據(jù)文章ID 獲取文章數(shù)據(jù)
也可以配合第三方的檢索插件 來(lái)進(jìn)行全文檢索
packagist.org 搜索中文分詞
小項(xiàng)目可以使用 結(jié)巴分詞
單列索引 和 復(fù)合索引
多個(gè)單列索引與單個(gè)多列索引的查詢效果分歧,因?yàn)閳?zhí)行查詢時(shí),MySQL只能使用一個(gè)索引,會(huì)從多個(gè)索引中選擇一個(gè)限制最為嚴(yán)格的索引.
即 mysql 底層本身會(huì)判斷 使用那個(gè)索引 速度會(huì)更快
組合索引(最左前綴)
平時(shí)用的SQL查詢語(yǔ)句一般都有比擬多的限制條件,所以為了進(jìn)一步榨取MySQL的效率,就要考慮建立組合索引.
例如上表中針對(duì)title和time建立一個(gè)組合索引:
ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10))
建立這樣的組合索引,其實(shí)是相當(dāng)于分別建立了下面兩組組合索引:
–title,time
–title
為什么沒(méi)有time這樣的組合索引呢?這是因?yàn)镸ySQL組合索引“最左前綴”的成果.
簡(jiǎn)單的理解便是只從最左面的開(kāi)始組合.
并不是只要包括這兩列的查詢都會(huì)用到該組合索引,如下面的幾個(gè)SQL所示:
–使用到上面的索引SELECT * FROM article WHREE title='測(cè)試' AND time=1234567890;SELECT * FROM article WHREE utitle='測(cè)試';–不使用上面的索引SELECT * FROM article WHREE time=1234567890;
自創(chuàng)索引表
如果又必要可以自創(chuàng) 索引表(關(guān)聯(lián)表).
例如 現(xiàn)在有一個(gè)文章表, 必要做一個(gè)文章的站內(nèi)搜索
那么 我們必要新建一個(gè)文章表
CREATE TABLE `article` ( `id` int(11) unsigned NOT NULL COMMENT '主鍵', `title` varchar(255) NOT NULL COMMENT '題目', `author` varchar(255) NOT NULL DEFAULT '' COMMENT '作者', `content` text NOT NULL COMMENT '內(nèi)容', `create_time` int(11) unsigned NOT NULL COMMENT '創(chuàng)建時(shí)間', `update_time` int(11) unsigned DEFAULT NULL COMMENT '修改時(shí)間', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
創(chuàng)建一個(gè) 分詞索引表
CREATE TABLE `article_participle` ( `id` int(11) NOT NULL, `article_id` int(11) unsigned NOT NULL COMMENT '文章表ID ', `participle` varchar(1000) NOT NULL COMMENT '關(guān)鍵詞 以空格分隔', PRIMARY KEY (`id`), UNIQUE KEY `article_id` (`article_id`) USING BTREE COMMENT '文章ID', FULLTEXT KEY `participle` (`participle`) COMMENT '中文分詞存儲(chǔ)') ENGINE=MyISAM DEFAULT CHARSET=utf8;
先根據(jù) 搜索的關(guān)鍵詞 搜索 分詞索引表
然后在根據(jù)搜索出的成果 (article_id 文章ID) 搜索文章表
索引辦法
BTree 索引特征
BTree索引可以被用在像=,>,>=,<,<=和BETWEEN這些比擬操作符上.而且還可以用于LIKE操作符,只要它的查詢條件是一個(gè)不以通配符開(kāi)頭的常量.像下面的語(yǔ)句就可以使用索引:
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';
下面這兩種情況不會(huì)使用索引:
SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%';SELECT * FROM tbl_name WHERE key_col LIKE other_col;
第一條是因?yàn)樗酝ㄅ浞_(kāi)頭,第二條是因?yàn)闆](méi)有使用常量.
假如你使用... LIKE '%string%'并且string超過(guò)三個(gè)字符,MYSQL使用Turbo Boyer-Moore algorithm算法來(lái)初始化查詢表達(dá)式,然后用這個(gè)表達(dá)式來(lái)讓查詢更迅速.
一個(gè)這樣的查詢col_name IS NULL是可以使用col_name的索引的.
任何一個(gè)沒(méi)有覆蓋所有WHERE中AND級(jí)別條件的索引是不會(huì)被使用的.也就是說(shuō),要使用一個(gè)索引,這個(gè)索引中的第一列必要在每個(gè)AND組中出現(xiàn).
下面的WHERE條件會(huì)使用索引:
... WHERE index_part1=1 AND index_part2=2 AND other_column=3 /* index = 1 OR index = 2 */... WHERE index=1 OR A=10 AND index=2 /* 優(yōu)化成 "index_part1='hello'" */... WHERE index_part1='hello' AND index_part3=5 /* 可以使用 index1 的索引但是不會(huì)使用 index2 和 index3 */... WHERE index1=1 AND index2=2 OR index1=3 AND index3=3;
下面的WHERE條件不會(huì)使用索引:
/* index_part1 沒(méi)有被使用到 */... WHERE index_part2=1 AND index_part3=2 /* 索引 index 沒(méi)有呈現(xiàn)在每個(gè) where 子句中 */... WHERE index=1 OR A=10 /* 沒(méi)有索引覆蓋所有列 */... WHERE index_part1=1 OR index_part2=10
有時(shí)候mysql不會(huì)使用索引,即使這個(gè)在可用的情況下.
例如當(dāng)mysql預(yù)估使用索引會(huì)讀取大部分的行數(shù)據(jù)時(shí).(在這種情況下,一次全表掃描可能比使用索引更快,因?yàn)樗匾俚臋z索).
然而,假如語(yǔ)句中使用LIMIT來(lái)限定返回的行數(shù),mysql則會(huì)使用索引.
因?yàn)楫?dāng)成果行數(shù)較少的情況下使用索引的效率會(huì)更高.
位圖索引 (HASH)
Hash類(lèi)型的索引有一些區(qū)別于以上所述的特征:
1.相對(duì)于BTree索引,占用的空間非常小,創(chuàng)立和使用非常快.
位圖索引由于只存儲(chǔ)鍵值的起止Rowid和位圖,占用的空間非常少.
2.不適合鍵值較多的列.
3.不適合update、insert、delete頻繁的列.
4.可以存儲(chǔ)null值.
BTree索引由于不記錄空值,當(dāng)基于is null的查詢時(shí),會(huì)使用全表掃描.
而對(duì)位圖索引列進(jìn)行is null查詢時(shí),則可以使用索引.
5.當(dāng)select count(XX) 時(shí),可以直接拜訪索引中一個(gè)位圖就快速得出統(tǒng)計(jì)數(shù)據(jù).
6.當(dāng)根據(jù)鍵值做and,or或 in(x,y,..)查詢時(shí),直接用索引的位圖進(jìn)行或運(yùn)算,快速得出成果行數(shù)據(jù)統(tǒng)計(jì).
7.它們只能用于對(duì)等比擬,例如=和<=>操作符(但是快很多).它們不能被用于像<這樣的范圍查詢條件.假如系統(tǒng)只需要使用像“鍵值對(duì)”的這樣的存儲(chǔ)結(jié)構(gòu),盡量使用hash類(lèi)型索引.
8.優(yōu)化器不克不及用hash索引來(lái)為ORDER BY操作符加速.(這類(lèi)索引不克不及被用于搜索下一個(gè)次序的值)
9.mysql不能判斷出兩個(gè)值之間有多少條數(shù)據(jù)(這必要使用范圍查詢操作符來(lái)決定使用哪個(gè)索引).假如你將一個(gè)MyISAM表轉(zhuǎn)為一個(gè)依靠hash索引的MEMORY表,可能會(huì)影響一些語(yǔ)句(的性能).
10.只有完整的鍵能力被用于搜索一行數(shù)據(jù).(假如用B-tree索引,任何一個(gè)鍵的片段都可以用于查找).
去索引化
為了更好的提高并發(fā)量,又發(fā)生了另一個(gè)思想!去索引化.
去索引化,并不是真正的去掉索引.只是通過(guò)異步操作把索引 像關(guān)系表那樣存起來(lái).
這樣可以提升,高并發(fā)寫(xiě)入的性能,又可以提升數(shù)據(jù)查詢的性能.
SQL語(yǔ)句優(yōu)化
經(jīng)常用到的必要條件字段 必要建立索引
避免在 where 子句中對(duì)字段進(jìn)行 null 值判斷(全表掃描)
避免 !=或<>操作
避免 in 和 not in 可用(between)
避免 '%c%' 考慮使用全文檢索.
避免使用 參數(shù),子句,函數(shù)操作
避免表達(dá)式操作 如 num/2=100; 優(yōu)化后 num=100*2;
查詢時(shí) 把條件中 有索引的 放在最左邊 (最左前綴)
exists 代替 in
分布式架構(gòu) 和集群架構(gòu)的區(qū)別
簡(jiǎn)單說(shuō),分布式是以縮短單個(gè)任務(wù)的執(zhí)行時(shí)間來(lái)提升效率的,而集群則是通過(guò)提高單位時(shí)間內(nèi)執(zhí)行的任務(wù)數(shù)來(lái)提升效率.
例如:
如果一個(gè)任務(wù)由10個(gè)子任務(wù)組成,每個(gè)子任務(wù)單獨(dú)執(zhí)行需1小時(shí),則在一臺(tái)服務(wù)器上執(zhí)行改任務(wù)需10小時(shí).
采用分布式方案,提供10臺(tái)服務(wù)器,每臺(tái)服務(wù)器只負(fù)責(zé)處理一個(gè)子任務(wù),不考慮子任務(wù)間的依賴關(guān)系,執(zhí)行完這個(gè)任務(wù)只需一個(gè)小時(shí).(這種工作模式的一個(gè)典型代表便是Hadoop的Map/Reduce分布式計(jì)算模型)
而采納集群方案,同樣提供10臺(tái)服務(wù)器,每臺(tái)服務(wù)器都能獨(dú)立處理這個(gè)任務(wù).假設(shè)有10個(gè)任務(wù)同時(shí)到達(dá),10個(gè)服務(wù)器將同時(shí)工作,10小后,10個(gè)任務(wù)同時(shí)完成,這樣,整身來(lái)看,還是1小時(shí)內(nèi)完成一個(gè)任務(wù)!
分表
為什么要分表?
數(shù)據(jù)庫(kù)中的數(shù)據(jù)量不必定是可控的,在未進(jìn)行分庫(kù)分表的情況下,隨著時(shí)間和業(yè)務(wù)的發(fā)展,庫(kù)中的表會(huì)越來(lái)越多,表中的數(shù)據(jù)量也會(huì)越來(lái)越大,相應(yīng)地,數(shù)據(jù)操作,增刪改查的開(kāi)銷(xiāo)也會(huì)越來(lái)越大;
另外,由于無(wú)法進(jìn)行分布式式部署,而一臺(tái)服務(wù)器的資源(CPU、磁盤(pán)、內(nèi)存、IO等)是有限的,最終數(shù)據(jù)庫(kù)所能承載的數(shù)據(jù)量、數(shù)據(jù)處理才能都將遭遇瓶頸.
分表的方式?
程度切分(橫向切分)
垂直切分(縱向切分)
聯(lián)合切分(橫向切分 和縱向切分)
垂直分表
何為垂直分表?
即將表依照功能模塊、關(guān)系密切程度劃分出來(lái),部署到不同的數(shù)據(jù)表上.
比如user(用戶表 主要存用戶名 和暗碼)表和user_details(用戶詳情 頭像,地址等)表.
好比博客表中的title和content表.(大字段 拆到另外一個(gè)表里)
大字段垂直切分
什么樣的字段適合于從表中拆分:
首先要肯定是大字段.為什么?原因很簡(jiǎn)單,便是因?yàn)樗拇?
大字段一般都是存放著一些較長(zhǎng)的Detail 信息,如文章的內(nèi)容,帖子的內(nèi)容,產(chǎn)物的介紹等等.
其次是和表中其他字段相比拜訪頻率明顯要少很多.
如果我們要查詢某些記錄的某幾個(gè)字段,數(shù)據(jù)庫(kù)并不是只需要拜訪我們需要查詢的哪幾個(gè)字段,而是需要讀取其他所有字段這樣,我們就不得不讀取包括大字段在內(nèi)的很多并不相干的數(shù)據(jù).
而由于大字段所占的空間比例非常大,自然所浪費(fèi)的IO 資源也就非常之大了.
實(shí)際上,在有些時(shí)候,我們甚至都不必定非要大字段才能進(jìn)行垂直分拆.
在有些場(chǎng)景下,有的表中大部分字段平時(shí)都很少拜訪,而其中的某幾個(gè)字段卻是拜訪頻率非常高.
對(duì)于這種表,也非常適合通過(guò)垂直分拆來(lái)達(dá)到優(yōu)化性能的目的.
垂直切分的長(zhǎng)處
數(shù)據(jù)庫(kù)的拆分簡(jiǎn)單明了,拆分規(guī)則明
應(yīng)用法式模塊清晰明確,整合容易
數(shù)據(jù)維護(hù)便利易行,容易定位
垂直切分的缺點(diǎn)
部分表關(guān)聯(lián)無(wú)法在數(shù)據(jù)庫(kù)級(jí)別完成,必要在程序中完成
對(duì)于拜訪極其頻繁且數(shù)據(jù)量超大的表仍然存在性能瓶頸,不一定能滿足要求
事務(wù)處置相對(duì)更為復(fù)雜
切分達(dá)到必定程度之后,擴(kuò)展性會(huì)遇到限制
過(guò)度切分可能會(huì)帶來(lái)系統(tǒng)過(guò)渡復(fù)雜而難以維護(hù)
程度分表
何為程度切分?
當(dāng)一個(gè)表中的數(shù)據(jù)量過(guò)大時(shí),我們可以把該表的數(shù)據(jù)依照某種規(guī)則,進(jìn)行劃分,然后存儲(chǔ)到多個(gè)結(jié)構(gòu)相同的表,和不同的庫(kù)上.
依據(jù)的條件可以是時(shí)間、地域、功能等比擬清晰的條件
好比財(cái)務(wù)報(bào)表、薪資發(fā)放就可以用時(shí)間進(jìn)行水平分割;
好比商品庫(kù)存就可以用地域進(jìn)行分割
好比用戶表的普通用戶、商戶就可以用功能來(lái)進(jìn)行劃分
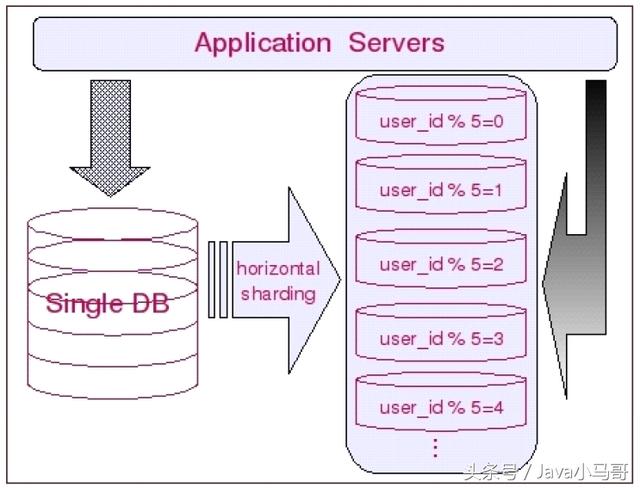
程度通用分表策略
以u(píng)uid作為全局唯一標(biāo)識(shí),為每一個(gè)新生成的用戶生成uuid
將uuid進(jìn)行md5加密,生成16進(jìn)制隨機(jī)字符串,取隨機(jī)字符串前兩位進(jìn)行10進(jìn)制轉(zhuǎn)換,對(duì)分表數(shù)量的取余,獲取插入的表后綴名.
好比建立8張表,對(duì)8取余,則會(huì)生成user_0...user_7,每個(gè)用戶會(huì)隨機(jī)插入這8張表中
分表后,如何統(tǒng)計(jì)數(shù)據(jù)?
所有統(tǒng)計(jì)數(shù)據(jù)都是根據(jù)業(yè)務(wù)需求而來(lái)的,原始數(shù)據(jù)存在的情況,我們可以進(jìn)行自建索引,實(shí)現(xiàn)具體的業(yè)務(wù)需求.
好比根據(jù)添加時(shí)間自建索引,其結(jié)構(gòu)如下:
|id|uuid|addtime|
|---|---|---|
那么根據(jù)addtime 我們就可以得出總數(shù),最新個(gè)數(shù).
分表后查詢效率的問(wèn)題?
根據(jù)自建索引表,獲取uuid,再根據(jù)uuid獲取數(shù)據(jù)每一行的數(shù)據(jù). 只不過(guò)多了一個(gè)10次的for循環(huán)罷了,而php的10for循環(huán)可以說(shuō)是微秒級(jí)的.結(jié)果集存儲(chǔ)的是指針 在通過(guò) mysql_fetch_row()讀取磁盤(pán)文件
水平切分的優(yōu)點(diǎn)
表關(guān)聯(lián)基本能夠在數(shù)據(jù)庫(kù)端全部完成
不會(huì)存在某些超大型數(shù)據(jù)量和高負(fù)載的表遇到瓶頸的問(wèn)題
應(yīng)用法式端整體架構(gòu)改動(dòng)相對(duì)較少
事務(wù)處置相對(duì)簡(jiǎn)單
只要切分規(guī)則能夠定義好,基本上較難遇到擴(kuò)展性限制
程度切分的缺點(diǎn)
切分規(guī)則相對(duì)更為復(fù)雜,很難抽象出一個(gè)能夠滿足整個(gè)數(shù)據(jù)庫(kù)的切分規(guī)則
后期數(shù)據(jù)的維護(hù)難度有所增加,人為手工定位數(shù)據(jù)更困難
應(yīng)用系統(tǒng)各模塊耦合度較高,可能會(huì)對(duì)后面數(shù)據(jù)的遷移拆分造成必定的困難
垂直與程度聯(lián)合切分的使用 (聯(lián)合切分)
如果大部門(mén)業(yè)務(wù)邏輯稍微復(fù)雜一點(diǎn),系統(tǒng)負(fù)載大一些的系統(tǒng),
都無(wú)法通過(guò)上面任何一種數(shù)據(jù)的切分辦法來(lái)實(shí)現(xiàn)較好的擴(kuò)展性,
而需要將上述兩種切分辦法結(jié)合使用,不同的場(chǎng)景使用不同的切分辦法.
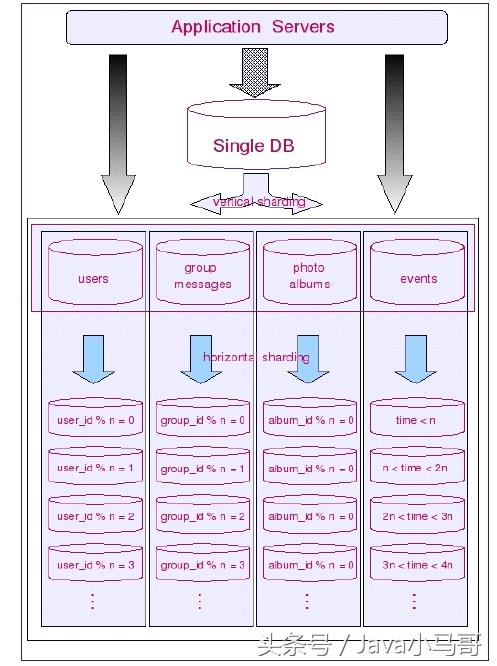
聯(lián)合切分的長(zhǎng)處
可以充分利用垂直切分和程度切分各自的優(yōu)勢(shì)而避免各自的缺陷
讓系統(tǒng)擴(kuò)展性得到最大化提升
聯(lián)合切分的缺點(diǎn)
數(shù)據(jù)庫(kù)系統(tǒng)架構(gòu)比擬復(fù)雜,維護(hù)難度更大;
應(yīng)用法式架構(gòu)也相對(duì)更復(fù)雜.
總結(jié)
以上是對(duì)MySQL性能調(diào)優(yōu),分享給大家,希望大家可以了解什么是MySQL性能調(diào)優(yōu).覺(jué)得收獲的話可以點(diǎn)個(gè)存眷收藏轉(zhuǎn)發(fā)一波喔,謝謝大佬們支持.(吹一波,233~~)
Java小馬哥,頭條出品,每天一篇干貨,喜歡就收藏+存眷

《Java互聯(lián)網(wǎng)架構(gòu)-深入理解MySQL性能調(diào)優(yōu)》是否對(duì)您有啟發(fā),歡迎查看更多與《Java互聯(lián)網(wǎng)架構(gòu)-深入理解MySQL性能調(diào)優(yōu)》相關(guān)教程,學(xué)精學(xué)透。維易PHP學(xué)院為您提供精彩教程。
轉(zhuǎn)載請(qǐng)注明本頁(yè)網(wǎng)址:
http://www.snjht.com/jiaocheng/7824.html
同類(lèi)教程排行
- Mysql實(shí)例mysql報(bào)錯(cuò):Deadl
- MYSQL數(shù)據(jù)庫(kù)mysql導(dǎo)入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺(tái)
- MYSQL創(chuàng)建表出錯(cuò)Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數(shù)據(jù)庫(kù)mysql常用字典表(完
- Mysql應(yīng)用MySql的Communi
- Mysql入門(mén)解決MySQL Sendi
- Mysql必讀關(guān)于skip_name_r
- MYSQL數(shù)據(jù)庫(kù)MySQL實(shí)現(xiàn)兩張表數(shù)據(jù)
- Mysql實(shí)例使用dreamhost空間
- MYSQL數(shù)據(jù)庫(kù)mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
