Mysql基本原理
《Mysql基本原理》要點:
本文介紹了Mysql基本原理,希望對您有用。如果有疑問,可以聯系我們。
從MySQL的原理入手,先看一張經典的圖:
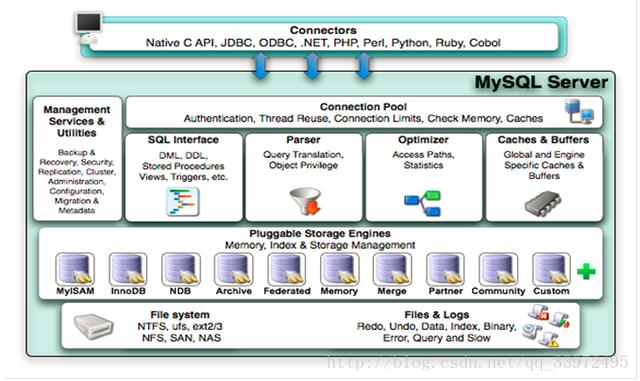
下面是關于上圖的介紹:
1.客戶端connectors
與其他編程中的sql語句進行交互,如:Java、PHP;
每個客戶端鏈接都會在服務器進程中擁有一個線程,這個連接的查詢只會在這個單獨的線程中執行,該線程只能輪流在某個CPU核心或CPU中運行.服務器會負責緩存線程,因此不需要為每一個新建的連接創建和銷毀線程.
一般情況,客戶端鏈接到mysql服務器時,服務器需要對其進下認證,認證基于用戶名、原始主機信息和密碼.如果使用了安全套接字SSL的方式連接,一旦客戶端連接成功,服務器會繼續驗證該客戶端是否具有執行某個特定查詢的權限.
2.Management Serveices & Utilities
系統管理和控制工具
3. Connection Pool (連接池)
管理緩存用戶連接,線程處理等需要緩存的需求
1、2、3——主要用于連接處理,授權認證,安全等,大多數基于網絡的客戶端/服務器的工具都有類似的架構
4. SQL Interface (SQL接口)
接受用戶的SQL命令,并且返回用戶需要查詢的結果.
(SQL接口接收到哀求后,它會將哀求進行hash處理并與緩存中的結果進行對比,如果完全匹配則通過緩存直接返回處理結果)
5. Parser (解析器)
SQL命令傳遞到解析器的時候,會被解析器解析和驗證
主要功能:
1.將sql分解成數據結構,并將這個結構傳遞到后續步驟,后續的sql的傳遞和處理就通過這個結構
2.后面分解過程中如果遇到了錯誤,那么就是這個sql出現了錯誤,將不會往后繼續執行
6. Optimizer (查詢優化器)
mysql會解析查詢,并創建內部數據結構(解析樹),然后進行各種優化,比如:重寫查詢,決定表的讀取順序,選擇合適的索引等.另外使用的是“選取-投影-聯接”策略進行查詢.
用一個例子就可以理解: select uid,name from user where gender = 1;
這個select 查詢先根據where 語句進行選取,而不是先將表全部查詢出來以后再進行gender過濾
這個select查詢先根據uid和name進行屬性投影,而不是將屬性全部取出以后再進行過濾
將這兩個查詢條件聯接起來生成最終查詢結果.
*優化器并不關心表使用的是什么存儲引擎,但是存儲引擎對于優化查詢是有影響的,優化器會哀求存儲引擎提供容量或摸個具體操作的開銷信息,以及表數據的統計信息(這里我也沒太理解,照抄的).
7. Cache和Buffer (查詢緩存)
如果查詢緩存有命中的查詢結果,查詢語句就可以直接去查詢緩存中取數據.
這個緩存機制是由一系列小緩存組成的.比如表緩存,記錄緩存,key緩存,權限緩存等
*對于select語句,在解析查詢之前,服務器會先檢查查詢緩存,如果能夠再其中找到對應的查詢,服務器將不必再執行查詢解析、優化和執行整個過程,而直接返回查詢緩存中的結果集.(buffer是寫緩存,cache是讀緩存)
8.Engine (存儲引擎)
存儲引擎是MySql中具體的與文件打交道的子系統.也是Mysql最具有特色的一個地方.
Mysql的存儲引擎是插件式的.它根據MySql AB公司提供的文件訪問層的一個抽象接口來定制一種文件訪問機制(這種訪問機制就叫存儲引擎)
*存儲引擎處理完數據,并將其返回給程序的同時,它還會將一份數據保留在緩存中,以便更快速的處理下一次相同的哀求.具體情況是,mysql會將查詢的語句、執行結果等進行hash,并保留在cache中,等待下次查詢.
維易PHP培訓學院每天發布《Mysql基本原理》等實戰技能,PHP、MYSQL、LINUX、APP、JS,CSS全面培養人才。
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/7074.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
