Mysql學習大幅提升MySQL中InnoDB的全表掃描速度的方法
《Mysql學習大幅提升MySQL中InnoDB的全表掃描速度的方法》要點:
本文介紹了Mysql學習大幅提升MySQL中InnoDB的全表掃描速度的方法,希望對您有用。如果有疑問,可以聯系我們。
MYSQL學習?在 InnoDB中更加快速的全表掃描
?一般來講,大多數應用查詢的時候都會用索引,查找很少的幾行數據(主鍵查找或百行內的查詢),但有時候我們需要全表查詢.典型的全表掃描就是邏輯備份? (mysqldump) 和 online schema changes( 注:在線上對大表 schema 的操作,也是 facebook 的一個開源項目) (SELECT ... INTO OUTFILE).
MYSQL學習?在 Facebook我們用 mysqldump 來備份數據庫. 正如你所知MySql提供兩種備份方式,提供了物理備份和邏輯備份的命令和工具. 相對物理備份,邏輯備份有一定的優勢,例如:
- ??? 邏輯備份備份數據要小得多. 3x-10x 尺寸差異并不少見.
- ??? 更容易解析備份數據庫. 在物理備份中,在出現嚴重問題時候,如校驗失敗.如果我們不能將數據庫恢復 ,想知道InnoDB內部數據結構,或者修復損壞是十分困難的.比起物理備份我們更加相邏輯備份.
MYSQL學習邏輯備份的主要缺點是數據庫的完全備份和完全還原比物理的備份恢復慢得多.
MYSQL學習緩慢的完全邏輯備份往往會導致問題.如果數據庫中存在很多大小支離破碎的表,它可能需要很長的時間.在 臉書,我們面臨 mysqldump 的性能問題,導致我們不能在合理的時間內對一些(基于HDD和Flashcache的)服務器完成完整邏輯備份.我們知道 InnoDB做全表掃描并不高效,因為 InnoDB 實際上并沒有順序讀取,在大多情況下是在隨機讀取.這是一個已知多年的老問題了.我們的數據庫存儲容量一直在增長,緩慢的全表掃描問題給我們造成了嚴重的影響,因此,我們決定加強 InnoDB 做順序讀取的速度.最后我們的數據庫攻堅工程師團隊在InnoDB 中實現了"Logical Readahead"功能.應用"Logical readahead",在通常生產工作負載下,我們全表掃描速比之從前度提高 9 ~ 10 倍.在超負荷生產中,全表掃描速度達到 15 ~ 20 倍的速度甚至更快.
MYSQL學習全表掃描在大的、碎片化數據表上的問題
做全表掃描時,InnoDB 會按主鍵順序掃描頁面和行.這應用于所有的InnoDB 表,包括碎片化的表.如果主鍵頁表沒有碎片(存儲主鍵和行的頁表),全表掃描是相當快,因為讀取順序接近物理存儲順序.這是類似于讀取文件的操作系統命令(dd/cat/etc) 像下面.
?
你可能會發現即使在商業HDD服務器上,你可以達到高于比100 MB/s 乘以"驅動器數目"的速度.超過1GB/s并不少見.
MYSQL學習不幸的是,在許多情況下主要關鍵頁表存在碎片.例如,如果您需要管理 user_id 和 object_id 映射,主鍵將會是(user_id,object_id).插入排序與 user_id并不一致,那么新插入/更新往往導致頁拆分.新的拆分頁將被分配在遠離當前頁的位置.這意味著頁面將會碎片化.
MYSQL學習如果主鍵頁是碎片化的,全表掃描將會變得極其緩慢.圖1闡釋了這個問題.在InnoDB讀取葉子頁#3之后,它需要讀取頁#5230,在那之后還要讀頁#4.頁#5230位置離頁#3和頁#4很遠,所以磁盤讀操作順序開始變得幾乎是隨機的,而不是連續的.大家都知道HDD上的隨機讀要比連續讀慢得多.一個有效的改進隨機讀性能的辦法是使用SSD.不過SSD每個GB的價錢要比HDD昂貴的多,所以使用SSD通常是不可能的.
MYSQL學習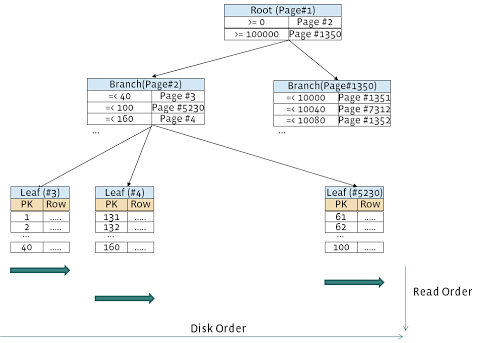
MYSQL學習圖 1.全表掃描實際沒有連續讀
MYSQL學習線性預讀取真的有意義嗎?
InnoDB支持預讀取特性,稱作“線性預讀取”( Linear Read Ahead).擁有線性預讀取,如果N個page可以順序訪問(N可以通過innodb_read_ahead_threshold參數進行配置,默認為56),InnoDB可以一次讀取一個extent(64個連續的page,如果不壓縮每個page為1MB).但是,實際來說這么做的意義不大.一個extent(64個page)非常小.對于一個支離破碎的較大的數據庫表來說,下一個page不一定在同一個extent當中.上面圖1就是一個很好的例子.讀取page#3之后,InnoDB需要讀取page#5230.page#3和page#5230并不在同一個extent當中,所以線性預讀取技術在這里用處不大.這對于大表來說是非常常見的情況,所以這也解釋了線性預讀取技術為什么不能有效改善全表掃描的性能.
?
物理預讀取
正如上面描述的,全表掃描速度較慢的主要原因是InnoDB主要進行隨機讀取.為了加速全表掃描,需要使InnoDB進行順序讀取.我想到的第一個方法就是創建一個UDF(user defined function)順序的讀取ibd文件(InnoDB的數據文件).UDF執行完成后,ibd文件的page應當保存在InnoDB的緩存池當中,所以在進行全表掃描時無需再進行隨機讀取.下面是一個示例用法:
?
MYSQL學習
mysql> SELECT buf_warmup ("db1", "large_table"); /* loading into buf pool */
mysql> SELECT * FROM large_application_table; /* in-memory select */
MYSQL學習buf_warmup() 是一個用戶自定義函數,用來讀取數據庫“db1"的表”large_table"的整個ibd文件.該函數需要花費時間將ibd文件從硬盤讀取,但因為是順序讀取的,所以比隨機讀取要快的多.在我的測試當中,比普通的線性預讀取快差不多5倍左右.
MYSQL學習這證明ibd文件的順序讀取能夠有效的改善吞吐率,但也存在一些缺點:
- ??? 如果table的大小超過InnoDB緩存池的大小,這種方法就不能工作
- ??? 在全表掃描過程中,讀取整個的ibd文件就意味著不但需要讀取primary key page還需要讀取二級索引page以及一些其他不需要的page,并將其保存在緩存池,盡管只有primary key page是實際需要的.如果擁有大量的二級索引,這種方法就不能有效的工作
- ??? 應用需要做出一定的修改以便調用UDF
MYSQL學習這看起來是一個足夠好的解決方案,但我們的數據庫設計團隊想出了一個更好的解決方法叫做“邏輯預讀取”(Logical Read Ahead),所以我們并不選擇UDF的方法.
MYSQL學習邏輯預讀取
邏輯預讀取(LRA)的工作流程如下:
- ??? 讀取主鍵的一些分支page
- ??? 計算葉子page的數量
- ??? 以page number的順序(大多數是順序磁盤讀取)依次讀取一些(通過配置控制數量的多少)葉子page
- ??? 以主鍵的順序讀取行
MYSQL學習整個流程如圖2所示:
MYSQL學習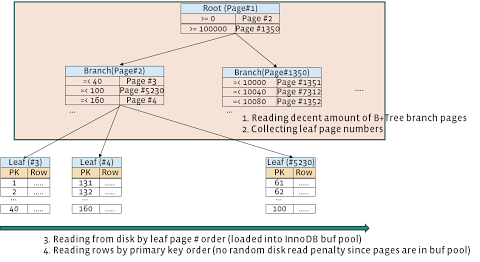
MYSQL學習Fig 2: Logical Read Ahead
MYSQL學習
邏輯預讀取解決了物理預讀取所存在的問題.LRA使InnoDB僅讀取主鍵page(不需要讀取二級索引頁面),并且每一次預讀取頁面的數量是可以控制的.除此之外,LRA對SQL語法不需要做任何修改.
MYSQL學習為了使LRA工作,我們需要增加兩個session變量.一個是"innodb_lra_size",用來控制預讀取葉子頁面(page)大小.另外一個是"innodb_lra_sleep",用來控制每一次預讀取之間休眠多長時間.我們用512MB~4096MB的大小以及50毫秒的休眠時間來進行測試,到目前為止我們還沒有遇到任何嚴重問題(例如崩潰/阻塞/不一致等).這些session變量僅在需要進行全表的時候進行設置.在我們的應用中,mysqldump以及其他一些輔助腳本啟用了邏輯預讀取.
MYSQL學習一次提交多個async I/O請求
MYSQL學習我們注意到,另外一個導致性能問題的原因是InnoDB 每次i/o僅讀取一個頁面,即使開啟了預讀取技術.每次僅讀取16KB對于順序讀取來說實在是太小了,效率相比大的讀取單元要低很多.
MYSQL學習在版本5.6中,InnoDB默認使用Linux本地I/O.如果一次提交多個連續的16KB讀請求,Linux在內部會將這些請求合并,讀操作能夠更有效的執行.不幸的是,InnoDB一次只會提交一個頁面的i/o請求.我提交了一個bug report#68659.正如bug report中所寫,在一個當代的HDD RAID 1+0環境中,如果我一次性提交64個連續的頁面讀取請求,我可以獲得超過1000MB/s的硬盤讀取速度;如果每次只提交一個頁面讀取請求,我們僅可以獲得160MB/s的硬盤讀取速度.
MYSQL學習為了使LRA在我們的應用環境中更好的工作,我們修正了這個問題.在我們的MySQl中,InnoDB在調用io_submit()之前會提交多個頁面i/o請求.
MYSQL學習基準測試
在所有的測試中,我們使用的都是生產環境下的數據庫表(分頁的表).
MYSQL學習1. 純HDD環境全表掃描 (基礎的基準測試, 沒有其他的工作負載)
MYSQL學習
MYSQL學習2. Online schema change under heavy workload
MYSQL學習
MYSQL學習* dump time only, not counting data loading time
?源碼
?我們做出的所有增強修改都可以在GitHub上獲取.
MYSQL學習
結論
MYSQL學習對于全表掃描來說InnoDB的工作效率不高,所以我們對它做了一定的修改.我在兩方面進行了改進,一是實現了邏輯預讀取;一是實現了一次提交多個async read i/o請求.對于我們生產環境中的數據庫表來說,我們獲得了8-18倍的性能提高,這對于減少備份時間、模式修改時間等來說是非常有用的.我希望這些特性能夠在InnoDB中獲得Oracle官方支持,至少是主要的MySQL分支.
轉載請注明本頁網址:
http://www.snjht.com/jiaocheng/5426.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數據庫mysql導入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數據庫mysql常用字典表(完
- Mysql應用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關于skip_name_r
- MYSQL數據庫MySQL實現兩張表數據
- Mysql實例使用dreamhost空間
- MYSQL數據庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
