Mysql必讀MySQL分組查詢Group By實現(xiàn)原理詳解
《Mysql必讀MySQL分組查詢Group By實現(xiàn)原理詳解》要點:
本文介紹了Mysql必讀MySQL分組查詢Group By實現(xiàn)原理詳解,希望對您有用。如果有疑問,可以聯(lián)系我們。
MYSQL實例由于GROUP BY 實際上也同樣會進行排序操作,而且與ORDER BY 相比,GROUP BY 主要只是多了排序之后的分組操作.當然,如果在分組的時候還使用了其他的一些聚合函數(shù),那么還需要一些聚合函數(shù)的計算.所以,在GROUP BY 的實現(xiàn)過程中,與 ORDER BY 一樣也可以利用到索引.
MYSQL實例 在MySQL 中,GROUP BY 的實現(xiàn)同樣有多種(三種)方式,其中有兩種方式會利用現(xiàn)有的索引信息來完成 GROUP BY,另外一種為完全無法使用索引的場景下使用.下面我們分別針對這三種實現(xiàn)方式做一個分析.
MYSQL實例 1、使用松散(Loose)索引掃描實現(xiàn) GROUP BY
MYSQL實例 何謂松散索引掃描實現(xiàn) GROUP BY 呢?實際上就是當 MySQL 完全利用索引掃描來實現(xiàn) GROUP BY 的時候,并不需要掃描所有滿足條件的索引鍵即可完成操作得出結(jié)果.
MYSQL實例 下面我們通過一個示例來描述松散索引掃描實現(xiàn) GROUP BY,在示例之前我們需要首先調(diào)整一下 group_message 表的索引,將 gmt_create 字段添加到 group_id 和 user_id 字段的索引中:
MYSQL實例
sky@localhost: example 08:49:45> create index idx_gid_uid_gc
-> on group_message(group_id,user_id,gmt_create);
Query OK, rows affected (0.03 sec)
Records: 96 Duplicates: 0 Warnings: 0
sky@localhost: example 09:07:30> drop index idx_group_message_gid_uid
-> on group_message;
Query OK, 96 rows affected (0.02 sec)
Records: 96 Duplicates: 0 Warnings: 0
MYSQL實例然后再看如下 Query 的執(zhí)行計劃:
MYSQL實例
sky@localhost: example 09:26:15> EXPLAIN
-> SELECT user_id,max(gmt_create)
-> FROM group_message
-> WHERE group_id < 10
-> GROUP BY group_id,user_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: group_message
type: range
possible_keys: idx_gid_uid_gc
key: idx_gid_uid_gc
key_len: 8
ref: NULL
rows: 4
Extra: Using where; Using index for group-by
MYSQL實例我們看到在執(zhí)行計劃的 Extra 信息中有信息顯示“Using index for group-by”,實際上這就是告訴我們,MySQL Query Optimizer 通過使用松散索引掃描來實現(xiàn)了我們所需要的 GROUP BY 操作.
MYSQL實例下面這張圖片描繪了掃描過程的大概實現(xiàn):
MYSQL實例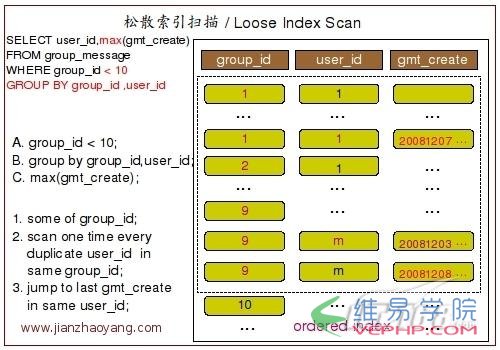
MYSQL實例要利用到松散索引掃描實現(xiàn) GROUP BY,需要至少滿足以下幾個條件:
MYSQL實例◆GROUP BY 條件字段必須在同一個索引中最前面的連續(xù)位置;
◆在使用GROUP BY 的同時,只能使用 MAX 和 MIN 這兩個聚合函數(shù);
◆如果引用到了該索引中 GROUP BY 條件之外的字段條件的時候,必須以常量形式存在;
MYSQL實例為什么松散索引掃描的效率會很高?
MYSQL實例因為在沒有WHERE子句,也就是必須經(jīng)過全索引掃描的時候, 松散索引掃描需要讀取的鍵值數(shù)量與分組的組數(shù)量一樣多,也就是說比實際存在的鍵值數(shù)目要少很多.而在WHERE子句包含范圍判斷式或者等值表達式的時候, 松散索引掃描查找滿足范圍條件的每個組的第1個關(guān)鍵字,并且再次讀取盡可能最少數(shù)量的關(guān)鍵字.
MYSQL實例2.使用緊湊(Tight)索引掃描實現(xiàn) GROUP BY
MYSQL實例緊湊索引掃描實現(xiàn) GROUP BY 和松散索引掃描的區(qū)別主要在于他需要在掃描索引的時候,讀取所有滿足條件的索引鍵,然后再根據(jù)讀取惡的數(shù)據(jù)來完成 GROUP BY 操作得到相應(yīng)結(jié)果.
MYSQL實例
sky@localhost : example 08:55:14> EXPLAIN
-> SELECT max(gmt_create)
-> FROM group_message
-> WHERE group_id = 2
-> GROUP BY user_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: group_message
type: ref
possible_keys: idx_group_message_gid_uid,idx_gid_uid_gc
key: idx_gid_uid_gc
key_len: 4
ref: const
rows: 4
Extra: Using where; Using index
1 row in set (0.01 sec)
MYSQL實例這時候的執(zhí)行計劃的 Extra 信息中已經(jīng)沒有“Using index for group-by”了,但并不是說 MySQL 的 GROUP BY 操作并不是通過索引完成的,只不過是需要訪問 WHERE 條件所限定的所有索引鍵信息之后才能得出結(jié)果.這就是通過緊湊索引掃描來實現(xiàn) GROUP BY 的執(zhí)行計劃輸出信息.
下面這張圖片展示了大概的整個執(zhí)行過程:
MYSQL實例
MYSQL實例在 MySQL 中,MySQL Query Optimizer 首先會選擇嘗試通過松散索引掃描來實現(xiàn) GROUP BY 操作,當發(fā)現(xiàn)某些情況無法滿足松散索引掃描實現(xiàn) GROUP BY 的要求之后,才會嘗試通過緊湊索引掃描來實現(xiàn).
MYSQL實例當 GROUP BY 條件字段并不連續(xù)或者不是索引前綴部分的時候,MySQL Query Optimizer 無法使用松散索引掃描,設(shè)置無法直接通過索引完成 GROUP BY 操作,因為缺失的索引鍵信息無法得到.但是,如果 Query 語句中存在一個常量值來引用缺失的索引鍵,則可以使用緊湊索引掃描完成 GROUP BY 操作,因為常量填充了搜索關(guān)鍵字中的“差距”,可以形成完整的索引前綴.這些索引前綴可以用于索引查找.而如果需要排序GROUP BY結(jié)果,并且能夠形成索引前綴的搜索關(guān)鍵字,MySQL還可以避免額外的排序操作,因為使用有順序的索引的前綴進行搜索已經(jīng)按順序檢索到了所有關(guān)鍵字.
MYSQL實例3.使用臨時表實現(xiàn) GROUP BY
MYSQL實例MySQL 在進行 GROUP BY 操作的時候要想利用所有,必須滿足 GROUP BY 的字段必須同時存放于同一個索引中,且該索引是一個有序索引(如 Hash 索引就不能滿足要求).而且,并不只是如此,是否能夠利用索引來實現(xiàn) GROUP BY 還與使用的聚合函數(shù)也有關(guān)系.
MYSQL實例前面兩種 GROUP BY 的實現(xiàn)方式都是在有可以利用的索引的時候使用的,當 MySQL Query Optimizer 無法找到合適的索引可以利用的時候,就不得不先讀取需要的數(shù)據(jù),然后通過臨時表來完成 GROUP BY 操作.
MYSQL實例
sky@localhost : example 09:02:40> EXPLAIN
-> SELECT max(gmt_create)
-> FROM group_message
-> WHERE group_id > 1 and group_id < 10
-> GROUP BY user_id\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: group_message
type: range
possible_keys: idx_group_message_gid_uid,idx_gid_uid_gc
key: idx_gid_uid_gc
key_len: 4
ref: NULL
rows: 32
Extra: Using where; Using index; Using temporary; Using filesort
MYSQL實例這次的執(zhí)行計劃非常明顯的告訴我們 MySQL 通過索引找到了我們需要的數(shù)據(jù),然后創(chuàng)建了臨時表,又進行了排序操作,才得到我們需要的 GROUP BY 結(jié)果.整個執(zhí)行過程大概如下圖所展示:
MYSQL實例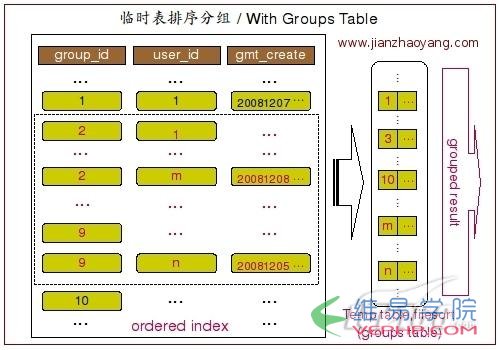
MYSQL實例當 MySQL Query Optimizer 發(fā)現(xiàn)僅僅通過索引掃描并不能直接得到 GROUP BY 的結(jié)果之后,他就不得不選擇通過使用臨時表然后再排序的方式來實現(xiàn) GROUP BY了.
MYSQL實例在這樣示例中即是這樣的情況. group_id 并不是一個常量條件,而是一個范圍,而且 GROUP BY 字段為 user_id.所以 MySQL 無法根據(jù)索引的順序來幫助 GROUP BY 的實現(xiàn),只能先通過索引范圍掃描得到需要的數(shù)據(jù),然后將數(shù)據(jù)存入臨時表,然后再進行排序和分組操作來完成 GROUP BY.
轉(zhuǎn)載請注明本頁網(wǎng)址:
http://www.snjht.com/jiaocheng/3404.html
同類教程排行
- Mysql實例mysql報錯:Deadl
- MYSQL數(shù)據(jù)庫mysql導(dǎo)入sql文件
- MYSQL的UTF8MB4編碼排序要用u
- MYSQL教程mysql自定義split
- 如何打造MySQL高可用平臺
- MYSQL創(chuàng)建表出錯Tablespace
- Mysql必讀MySQL中CLIENT_
- MYSQL數(shù)據(jù)庫mysql常用字典表(完
- Mysql應(yīng)用MySql的Communi
- Mysql入門解決MySQL Sendi
- Mysql必讀關(guān)于skip_name_r
- MYSQL數(shù)據(jù)庫MySQL實現(xiàn)兩張表數(shù)據(jù)
- Mysql實例使用dreamhost空間
- MYSQL數(shù)據(jù)庫mysql 查詢表中平均
- MYSQL教程mysql 跨表查詢、更新
