SEO:如何正確識(shí)別百度蜘蛛,且看官方說(shuō)法
《SEO:如何正確識(shí)別百度蜘蛛,且看官方說(shuō)法》要點(diǎn):
本文介紹了SEO:如何正確識(shí)別百度蜘蛛,且看官方說(shuō)法,希望對(duì)您有用。如果有疑問(wèn),可以聯(lián)系我們。
相關(guān)主題:網(wǎng)站搜索引擎優(yōu)化
這篇文章來(lái)自百度官網(wǎng)。
經(jīng)常聽(tīng)到站長(zhǎng)們問(wèn),百度蜘蛛是什么?
最近百度蜘蛛來(lái)的太頻繁服務(wù)器抓爆了,最近百度蜘蛛都不來(lái)了怎么辦?
還有很多站點(diǎn)想得到百度蜘蛛的IP段,想把IP加入白名單,但I(xiàn)P不固定,我們無(wú)法對(duì)外公布。
那怎么才能識(shí)別正確的百度蜘蛛呢?來(lái)來(lái)來(lái),只需兩步,教你正確識(shí)別百度蜘蛛。
1、查看UA:其中最主要的關(guān)鍵字是Baiduspider
如果UA都不對(duì),可以直接判斷非百度搜索的蜘蛛,目前對(duì)外公布過(guò)的UA是:
移動(dòng)UA:Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,likeGecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)
PC UA:Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)
新增渲染UA:
移動(dòng)UA:Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 likeMac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143Safari/601.1 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)
PC UA:Mozilla/5.0 (compatible;Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)
2、反查IP
站長(zhǎng)可以通過(guò)DNS反查IP的方式判斷某只spider是否來(lái)自百度搜索引擎。根據(jù)平臺(tái)不同驗(yàn)證方法不同,如linux/windows/os三種平臺(tái)下的驗(yàn)證方法分別如下:
1)、在linux平臺(tái)下,您可以使用host ip命令反解ip來(lái)判斷是否來(lái)自Baiduspider的抓取。Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即為冒充。
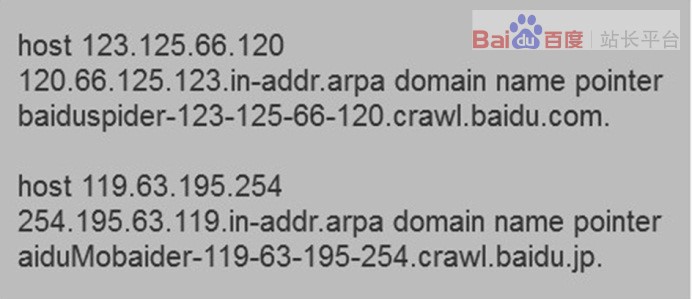
2)、在windows平臺(tái)或者IBM OS/2平臺(tái)下,您可以使用nslookup ip命令反解ip來(lái) 判斷是否來(lái)自Baiduspider的抓取。打開(kāi)命令處理器 輸入nslookup xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 來(lái)判斷是否來(lái)自Baiduspider的抓取,Baiduspider的hostname以*.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即為冒充。
3)、 在mac os平臺(tái)下,您可以使用dig 命令反解ip來(lái) 判斷是否來(lái)自Baiduspider的抓取。打開(kāi)命令處理器 輸入dig xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 來(lái)判斷是否來(lái)自Baiduspider的抓取,Baiduspider的hostname以 *.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即為冒充。
附:下面是一個(gè)php函數(shù),內(nèi)含較為完整的蜘蛛類型判斷。參數(shù)是UA。
/** 共源:http://www.snjht.com
* 判斷是否為搜索引擎蜘蛛,返回蜘蛛類型
* @return false/蜘蛛類型
*/
function spider($userAgent='')
{
$agent= empty($userAgent) ? strtolower($_SERVER['HTTP_USER_AGENT']) : strtolower($userAgent);
if (empty($agent)) return false;
#Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
$spiderSite= array(
"Googlebot" => "谷歌",
"Google AdSense" => "谷歌AdSense",
"Baiduspider+" => "百度",
"BaiduGame" => "百度",
"BaiDuSpider" => "百度",
"YisouSpider" => '神馬',
"Sogou Spider" => "搜狗",
'Sogou web'=>'搜狗',
"msnbot" => "MSN",
'bingbot' =>'必應(yīng)',
'360spider'=>'好搜',
'HaoSouSpider'=>'好搜',
"Sosospider+" => "SOSO",
"Yahoo! Slurp" => "雅虎",
"Yahoo Slurp" => "雅虎",
'YandexBot' =>'YandexBot',
"TencentTraveler" => "騰訊",
"YoudaoBot" => "有道",
"ia_archiver" => "Alex",
"MSNBot" => "MSN",
"Ask" => "Ask",
'linkdexbot'=>'linkdex',
"Speedy Spider" => "Speedy Spider",
"Java (Often spam bot)" => "Java (Often spam bot)",
"Voila" => "Voila",
"Yandex bot" => "Yandex bot",
"BSpider" => "BSpider",
"twiceler" => "twiceler",
"Heritrix" => "Heritrix",
"Python-urllib" => "Python-urllib",
"Alexa (IA Archiver)" => "Alexa (IA Archiver)",
"Exabot" => "Exabot",
"Custo" => "Custo",
"OutfoxBot/YodaoBot" => "OutfoxBot/YodaoBot",
"yacy" => "yacy",
"SurveyBot" => "SurveyBot",
"legs" => "legs",
"lwp-trivial" => "lwp-trivial",
"Nutch" => "Nutch",
"StackRambler" => "StackRambler",
"The web archive (IA Archiver)" => "The web archive (IA Archiver)",
"Perl tool" => "Perl tool",
"MJ12bot" => "MJ12bot",
"Netcraft" => "Netcraft",
"MSIECrawler" => "MSIECrawler",
"WGet tools" => "WGet tools",
"larbin" => "larbin",
"Fish search" => "Fish search",
);
foreach($spiderSite as $spider => $spiderName) {
$str = strtolower($spider);
if (stripos($agent, $str) !== false) {
return $spiderName;
}
}
return false;
}轉(zhuǎn)載請(qǐng)注明本頁(yè)網(wǎng)址:
http://www.snjht.com/jiaocheng/114.html
